原创: 刘昕
2019年6月5日下午,由中国科学院智能信息处理重点实验室、中科视拓(南京)科技有限公司、南京市大数据协会与南京江北新区产业技术研创园联合主办的“2019云智中心AI实验室‘大数据驱动AI落地’主题研讨会”在南京市江北新区研创园举行。中科视拓CEO刘昕博士带来主题演讲“当数据遇上AI“,以丰富的案例对AI产业与大数据的结合作了精彩讲解,指出大数据堪称“AI时代的石油”。
以下为刘昕博士演讲节选。
当数据遇上AI(节选)
尊敬的各位领导,各位中科视拓的新老朋友,大家下午好。非常荣幸今天我来给大家分享一下视拓在人工智能基础设施,包括人工智能和大数据结合方面所做的一些工作。
整个人工智能市场其实非常巨大,2019年已经达到了千亿规模。这么大规模的市场,来自国家和各个行业的支持力度也是空前的。今天谈到人工智能,可能想到高铁站已经开始刷脸过闸机了,我们园区有很多人脸门禁、刷脸吃饭的系统,很多肯德基已经开始刷脸支付了,这些其实都是AI的应用。AI价值的产生,其实不是单独的,它实际上要扎根于各个行业。这一个一个的行业场景,就是AI落地生根的土壤。
从学术的角度,整个AI技术其实有三大支撑性引擎,第一个引擎是深度学习算法。深度学习算法其实从1943年就开始发展了,一直到2012年它再一次被提出,并迅速成为这一次人工智能革命的代表性技术。为什么它过了几十年才大发展呢?其实得益于两个要素。一个是大数据,过去由于设备的存储能力有限,我们是不可能有这么丰富的数据的。现在我们的视频、语音数据,规模是过去完全不可想象的。二十年前买电脑,普通个人PC的内存只有几M的硬盘,当时觉得已经很大了;现在你去买一台手机,可能已经是8G、16G的内存了。另外一个要素,其实就是高性能的计算,包括GPU、XPU、NPU为代表的高性能计算技术。
对AI来说,大数据是一个非常关键的基础设施,大数据产业的蓬勃发展,使得数据的传输、存储和应用成为可能。这些大数据正是AI孜孜勃勃的养分。对AI时代来说,大数据就是石油,如果没有石油,我们就没法驱动AI的列车往前走。
我们举一些形象的例子,数据究竟有多大。以视频和图像为例,现在全球有34亿互联网用户,每天产生10的15次方张图像。另一个是监控数据,全球有5亿个监控摄像头,中国有2亿个,每天产生48亿小时的视频数据。这是完全没有可能全部用人去看的,所以让计算机去理解图片、理解视频,才能挖掘有意义的信息。比如逃犯驾驶某一个型号的汽车,但我不知道车牌号,我能不能通过视频结构化分析知道这个车现在行驶在哪条路上、哪个路口?这其实就是视频的理解技术,是在视频大数据的基础上用人工智能提高大数据的检索和理解能力。

比如IoT数据。2018年全球IoT设备已达到220亿,每天产生大量的行为、交互数据,特别是跟人的数据。以电商为例,淘宝网的日活已超过1个亿,拼多多已经超过4000万,1亿的日活每个人哪怕做十次操作,每天就有十亿次的浏览,全年下来是3000多亿次,这是非常恐怖的一个量,是一个巨大的电商数据群。今天的大数据得益于传感器技术,得益于手机的普及,每个人其实都是大数据时代的一个贡献者,进一步为整个AI的发展贡献数据的养分。其他包括一些政府、金融的行业数据也在陆续开放。
AI干两件事情最擅长,一是人可以干,但数量太大干不过来的事情,比如每天48亿小时的视频监控数据,机器可以做得更快、甚至做得更好。还有一类任务,就是人完全不能做,比如一些极端的情况,比如高噪声、一些非可见光的传感器或者一些人眼的感知不到的频率,比如我们今天开放实验室里会展示一个微表情的识别应用,它以每秒120帧的速度去抓取人的面部微动作,而人眼最大的频率也就是20帧左右,超过这个频率它是没有办法捕捉的。
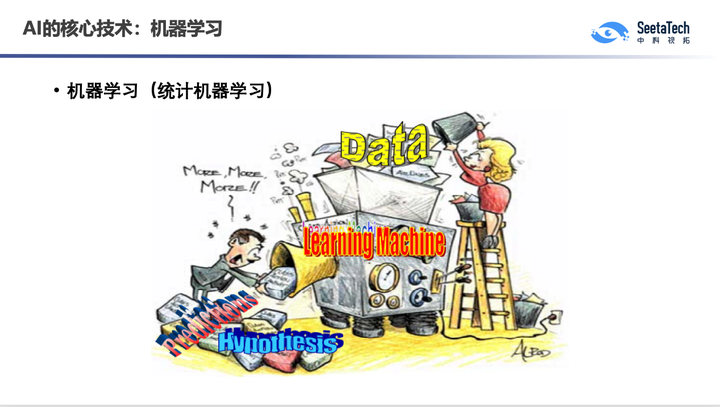
如何让机器具备理解数据的能力呢?这就牵扯到机器学习。机器学习实际上就是让机器具备理解数据的能力,什么叫理解数据?从历史的数据当中学习知识,从而能够预测未知的数据。好比现在我想训练一个机器去区分苹果和橘子,实际上我要拿大量苹果和橘子的照片给它看。从大量的历史数据中去学习知识,建立所谓的机器学习的模型,基于这个模型去预测未知的数据。有个漫画,画里有我们称为learning Machine的学习机,大家看,这个小孩在往里面倒的就是我们的大数据,这个数据进到这个机器之后,出来的其实就是我们的模型,就是model。
下面我以讲故事的形式讲一讲我们在机器学习领域怎么运用各种不同类型的数据。第一种最经典的,所谓监督学习,也称之为有导师学习,就是我提前告诉机器这个是什么。比如我想训练一个机器区分不同的水果,监督学习实际上会提前告诉它哪一种水果是什么,比如这个是樱桃,这个是梨子。但监督学习有个很大的问题,就是非常依赖训练集的规模和质量。以自动驾驶为例,假如我现在训练这个车,天天让它跑高速,它在高速上跑得非常好了。那接下来我把这辆车放到堵车时某一个城市的路口,发现这个车子不会开了,那是因为这个车在它的历史数据当中学到的都是这种高度规范化的数据,但当一堆行人、非机动车和机动车混在一起,甚至不去遵守红绿灯的时候,这个车完全不会开了。所以对于AI而言,为什么这么需要大数据?因为它必须见过足够丰富的历史数据,它才可以学到比较普适性的知识。其实AI发展到今天还是非常依赖于海量的有标签的数据,超过90%的AI是离不开这种监督学习的,包括我们现在熟悉的人脸识别,自动驾驶,背后全是监督学习的技术。

另外一种比较经典的学习模式叫半监督学习。这个现在是学术研究的一个热点,就是有一部分数据我告诉它标签了,比如这个是猕猴桃,这个是哈密瓜;但另一堆数据我没有告诉你它到底是什么,你能不能把这两边数据混在一块学到一个更好的模型,这叫半监督学习。因为我们很多数据可能是没有标签的,比如我们现在想在银行里做一个关于骗贷风险的模型,我知道有些客户他没有骗贷、没有逾期,有些客户他逾期了,但现在我引进来新的客户,他还没有到期,我不知道他到底是逾期还是不逾期。那这些数据能不能加入到我们前面训练里面去呢?这个其实就叫做半监督学习。
还有一种叫无监督学习,就是这个数据完全没有标签,它就是一堆数据,它可能是结构化的,可能是半结构化的,甚至可能是完全非结构化的,我们能不能从这些数据当中学习出一点东西?这就是所谓的无监督学习。无监督学习里最经典的就是聚类分析,就是我现在给你一堆图片,一堆数据,你能不能告诉我这里面有几种类别,相当于自动给这些数据打标签。像现在很多小姑娘喜欢给男生打标签,什么大叔、小鲜肉,也是类似的,这也是一种无监督的分类方法。
另外一种就是强化学习。强化学习火起来的一个标准其实就是AlphaGo,因为AlphaGo2.0已经不再需要人类的棋谱了,完全是机器的左右互搏,基于左右互搏的结果,就可以直接学习出一个自动识别复杂环境的模型了。强化学习的核心实际上就是让这个模型接受环境的反馈,通过这个反馈来调整自己的行为,当这个行为调得越来越准,越来越适应这个环境的时候,这个模型就学好了。比如我现在训练一个机械手去抓零件,或者训练一个机器人在一个完全没有标注的地图环境里去运行,实际上它就需要自己去多撞几次。其实小孩的学习就有点像强化学习,像宝宝走路的时候,一开始他老是跌倒,他跌几次他自动就知道怎么去调整自己的重心,调整自己走路的姿态。
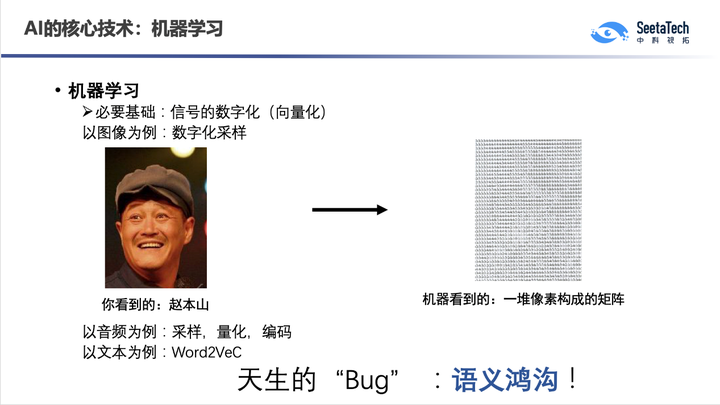
为什么我们讲机器学习很难做?因为机器在学习这些数据的时候,它看到的数据跟我们人看到的数据是不一样的。比如当我们看到赵本山的时候,我们看到的就是赵本山,但机器看到的是一堆像素,以及每个像素的强度。这就是所谓的机器学习里面临的一个根本性问题叫做“语义鸿沟”。所以有时候人看起来很简单的任务,机器做起来很复杂;但有时候人看起来很复杂的东西,机器做起来比较简单。比如双胞胎,很多时候人认不出来,但机器能认出来,可以研究出面部非常微弱的一些差异。比如一个小孩丢了十几年,他的父母一直在找他,那十几年后看照片还能认出孩子吗?这种跨年龄的识别能力其实人已经编码到基因里去了,因为小孩一定要找到自己的父母。我们小时候学小蝌蚪找妈妈,其实很多小孩他走失多年之后,父母还能认出它,其实有生物的基因机制在里面,而这些其实机器做起来很复杂。

所以刚刚我们举了两个很极端的例子,那是因为它们机制不一样,为什么它的机制复杂呢?因为对机器而言,不管你是做什么样的机器学习任务,都是学习一个数学函数。数学函数设计其实就有两个流派了,第一个流派就是所谓的经验驱动,人为定义这个函数长什么样。在经验驱动模式里,函数的设计方法是人为确定的,它可能跟这个数据并不一定是最适配的。朱松纯教授有一个漫画我引用一下,过去我们机器学习专家,什么叫专家呢?就像老中医,当你拿到一个机器学习任务的时候你也不知道咋做,那咋办呢?我就抓点药吧,我听我的师父说好像这种药比较适合于这种任务。一个一个药箱子里就是我们所谓的各种特征和算法,那我做一个新的任务的时候我就凭经验把这些东西做一下组合,这叫所谓的经验驱动。
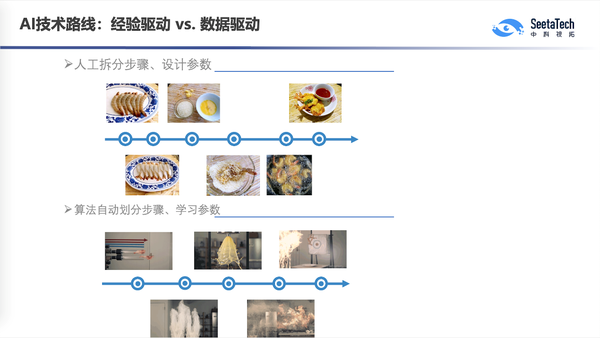
那么深度学习时代呢,完全不一样了。有了大数据之后就有了智能,我把数据直接灌到模型里面,直接得到输出结果,不再是人去拆分这样的一个模型了。有一个漫画来形容传统的经验驱动策略和数据驱动策略的不同。经验驱动的时候我要炸一只虾,可能是妈妈教我们,这个虾要洗,要切,要裹淀粉,然后下油锅去炸,炸到两面金黄色装盘。但现在是一个完全大数据的时代,我要去炸虾怎么办呢?我直接做个机器吧,在这个机器里面自动去控制撒粉的速度,控制火候,控制调料,把这个虾扔进去最后虾就炸好了。这是我们说的所谓的大数据时代的机器学习,它实际上是从历史的大数据当中去挖掘知识,人不再去显示地定义这个算法的各个阶段。
对于现在数据驱动的AI来说,深度学习是代表性的技术,也是从2012年到现在这个领域最火的一个技术。虽然不断有声音在唱衰深度学习,说现在已经进入了一个后深度学习的时代了,深度学习本身的能力已经被挖掘得差不多了,但是对产业界来说,在新的技术出现之前,深度学习仍然是目前最有效的技术。
实际上在深度学习来临之后,结合大数据,我们看到很多领域取得了非常突破性的进步。深度学习其实能做非常多的事情,像聊天机器人,智能投顾,智能医疗,专家系统,这背后都有AI技术的影子。
那我又要回到大数据了。为什么我们说需要大数据?因为你要想做好AI模型,你一定要机器见多识广,积累足够丰富的数据。以自动驾驶为例,我要想让机器认识车道线,认识行人,认识这些不同的车辆,认识不同的背景,我其实要大量的数据。所以我们经常看到百度或者其他公司,它的自动驾驶汽车在频繁地跑,实际上是在采数据。我们做过一个统计,平均每个AI公司有10%的投入是用于整个的大数据基础设施的建设,如果说整个AI产业是一个千亿或者万亿规模的话,它直接相关的大数据产业就已经有百亿或者千亿这么多了,还不包括大数据本身的产业规模。所以其实它跟大数据产业实际上是紧密相关的,没有大数据产业就没有AI。
下面我们来介绍一下我们在大数据与AI结合里面做的一些工作。我们是一个做AI基础设施的公司,其实我们会面对各式各样的AI需求。我们给各位来宾发的小册子里就有我们做的一些案例,比如畜牧的,我们要去识别牛的花纹,识别猪脸,甚至给猪计数,各种奇奇怪怪的AI需求。我们发现这些AI需求里有一些共通性的问题,第一个就是数据,其实高质量的数据非常难获取。很多时候我们获得的数据虽然很大,但它可能有噪声,或者压根儿没有标注。那这些大而不精确的数据,我怎么去应用呢?另一块是本身AI的调参非常复杂,我可不可以用AI的技术,或者说大数据的技术来加快AI的调参?因为每一次AI模型的训练和部署,其实它就积累了一次数据,那这么多的AI公司,这么多的AI开发者,这些行为数据本身也是大数据,这些大数据能不能反过来去加速AI的进展?这是我们研究的第二个问题。
所以我们做了几个工作。第一个就是复杂数据条件下的深度学习,假如这个数据标签是错的,比如这个人明明不是坏人,你给他标成坏人,一个坏人你标成好人。这个数据里面有噪声,但不是所有数据都有噪声,我们如何利用这样的数据标签可能不精确的数据。我们第二个工作,就是一部分数据有标签,一部分数据没标签,我能不能自动复原没有标签的这些数据的标签,也就是半监督学习。
再比如刚说的调参,开发者的每一次调参其实都是数据,从这些大数据中我们也能学习到知识,用这些知识来指导我们AI模型的调参。再比如我们这些数据非常难获取,比如车祸的场景,你想去获取真实的数据非常困难,但我能不能用CG的引擎去做模拟呢?这是我们现在重点做的一个方向,就是“虚拟数据合成”,其实就是用CG模型来合成一些在我们自然环境当中获得不了的场景,比如特定的视角、特定的光照、特定的场景。比如我现在希望在研创园里去模拟一个很多人聚集的场景,我很难把这些人凑在一起,但如果我有研创园的CG模型,我可以用CG模拟最后把数据采集出来。

还有一块就是用计算机技术合成大数据。这个视频相信大家都见过,叫DeepFake换脸术,最早这个视频是朱茵,现在这张脸换成杨幂,毫无违和感。这其实就是用计算机去做虚拟数据的生成。比如我们右边的例子,这个人是黑头发,我现在想把他换成黄头发;或者他没有戴眼镜,我想给他戴上眼镜;或者我希望把他变老,或者表情变一下。所以现在的计算机合成技术,已经可以让你做出根本就不存在的表情,帮你做出一个根本不存在的视频。曾经记得《潜伏》当中,余则成被他的同事陷害,把他老婆跟一个人的语音串在一起做了一个录音带。那今天其实视频虚拟合成的技术已经可以合成一个完全不存在的视频,其实这个也挺可怕的,但如果这个技术被善用的话,它其实就意味着我们可以合成出很多真实场景中不存在的数据,来丰富整个数据库,降低我们的成本。

今天我们来到江北新区研创园,现在整个智慧园区的建设正在如火如荼地开展,我们视拓也非常荣幸承建了其中一部分工作。我们也发现,其实整个社会也正在加快进行到一个智能化的时代,过去我们讲信息化时代,现在我们更多地强调智能化,很多无人值守的设施开始出现,比如楼下就放了我们一台无人值守的视觉冰柜,各种各样无人化的设施进入到我们生活的各个层面,比如智能的交通,智能的家居,智慧的出行。
大数据结合AI,可以极大地提高我们生活、生产的效率,降低浪费,可以让更多的人能够从事创造性的工作。我们非常期待一个智能化时代的到来,这意味着我们大数据的企业和我们人工智能的企业,能够获得非常快的发展机会。另一方面,我们认为数据其实是整个AI行业的基础设施,我们现在在建的云智中心,其实它从数据到算法再到应用场景整个流程打通了,其中非常重要的一个环节就是行业数据。所以我们也非常迫切地希望进入到大数据协会的工作当中,能够和更多的行业企业,跟政府,跟各位新老合作伙伴一起来推动AI技术在各个行业里落地。这是视拓的使命,所谓我们董事长说的“开源赋能共发展”,让我们每一位合作伙伴能共同发展。好,谢谢。
—END—
