本人系2020年美赛C题O奖+INFORMS Award得主(20年C题参赛队伍总数6800+,比例看上去十分唬人),团队角色:队长,主攻编程,辅助建模写作。获奖证明如下:

距离20年美赛结束已有一年多时间,现在本科毕业后有些空余时间,因此写下该分享贴(非专业性,非大佬,可能有不成熟的想法,甚至大量不专业内容),对美赛C题感兴趣的同学可以适当一看,获奖具有偶然性,天时地利人和最重要。
团队背景:
1.专业背景:三人均为西南财经大学大三(2020年,现已毕业)学生,专业均为金融或管理类相关。均参加过数模国赛培训。第一次参加美赛。
2.知识背景:三人均具备数模基本知识,金融学、统计学基础。本人主要学习了统计建模、数据挖掘、matlab和python编程相关知识。(简单说来就是菜鸟)
看到这里,想必大家应该明白了,本帖适合非理工科专业想要参加美赛的同学,也适合准备时间较短但仍想获奖的同学。
有人可能会问了,我不会NLP怎么办?

答案很简单,现学!半天之内只需要学会怎么调用基础的自然语言处理库就ok了,比如基础的分词、情感分析等等,这毕竟是数学建模,而不是机器学习,所以只要你有python基础,就直接上吧,人有多大胆,地有多大产!
有人可能会说,我只会matlab怎么办捏?

那我的建议就是趁早回家睡觉,节约四天暴肝时间(不要杠我,我太菜不会用matlab做NLP,大佬可以尝试),或者就是选择AB题之类的,换个题换个心情。
那么我要开始介(hu)绍(shuo)经(ba)验(dao)了!

假设你已经看完了20年美赛C题的题目和要求,你的第一印象是什么?
你怎么想我不知道,但是我当时的感受是:纳尼这居然是数模题?确定不是数据挖掘课的作业吗?作为一个被国赛荼毒已久的菜鸟,说实话还挺不适应的,那么它到底是不是一个单纯的数据挖掘题呢?(⊙ˍ⊙)
当然不是。——一定要有模型!不能只有数据处理过程。
在参加正式比赛之前,我看了近几年的美赛BDCEF和O奖论文,印象比较深刻的一个是19年E题的一篇O奖论文(具体是哪篇也忘记了,感兴趣的朋友可以告诉我,我去找找再告诉宁),这篇论文让我记住的特点就是:使用通俗易懂的方法建立了具有可解释性的决策模型,并通过优美的图表展示出来,对于题目的每一个需要解决的问题都给出了简洁明了且可行的决策方法和分析,每个模型都在通俗易懂和高逼格之间达到了一定平衡。——这也是我认为想要在美赛C题中取得好成绩的重点(毕竟参赛论文太多,阅卷老师看的并不仔细,盲目追求高逼格的模型可能适得其反)。
那么说回到我们的参赛过程。
在反复阅读题目后,我大致将它看作是一个电商产品用户评论数据挖掘和分析的数模题,为了节约大家的时间,我们简单复习一下它的题目内容(有一定提炼,不是中文翻译):
在亚马逊创建的线上市场中为客户提供了一个对购买进行评价和评估的机会。根据这些用户评论数据,公司可以判断参与时机以及根据顾客的建议对商品进行设计改造。
我们的任务可以概括如下:
1.分析星级、帮助性评级与评论的关系;
2.深入分析评论反馈,星级,产品声誉变化等情况,确定产品的优缺点,为产品改进提出建议;
3.基于评价和评级的分析建立产品评分体系,识别潜在的重要设计特征,选出优质品牌的商品。
可以看到题目中的要求有些零散,需要进行一定的总结,确定好建模的大致框架,因此我们将建模大致分为四个部分:
1.研究review, star rating和helpfulness rating之间的关系;
2.研究产品品牌评级方法;
3.预测产品的reputation;
4.预测star rating对reviews的影响。
每一个步骤并非独立,且都是循序渐进的,整体流畅图如下:
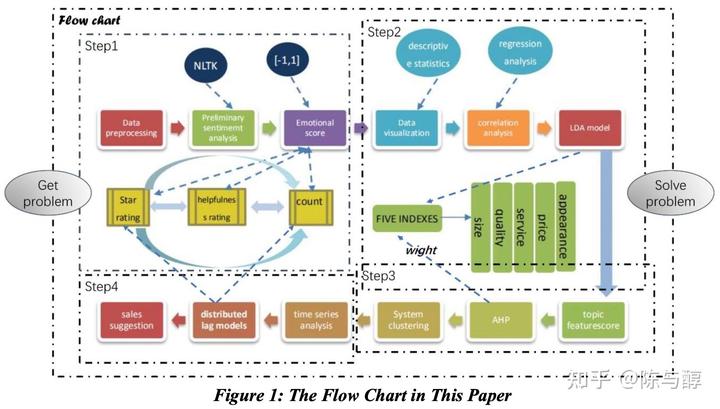
Model 1-Analysis of Star rating, Helpfulness rating and Review1.1 数据预处理
确定好框架后,我们从step 1开始,首先去除无用信息,如产品名称、市场和产品类别,在此基础上进行初步的数据预处理,包括处理缺失值、异常值;构造helpfulness rating属性以便于更好地分析评论的有用性;大小写转换,拼写检查,表情包意义转换等等。
经过上述步骤后,我们的数据集变得更容易接受,但当我们更仔细地查看评论内容时,可以发现许多评论内容与产品无关,可以被视为冗余信息,例如:
以奶嘴为例,需要剔除与奶嘴无关的评论。我们根据文本相似度来识别冗余信息,过程如下:将产品评论视为一组词,通过计算文本中每个词的数量来建立文本的特征向量,然后利用向量间的余弦相似度计算文本间的相似度。如果该条评论与其他评论之间的平均相似性小于我们设置的阈值,则删除该条评论。
预处理过程具体如下图:
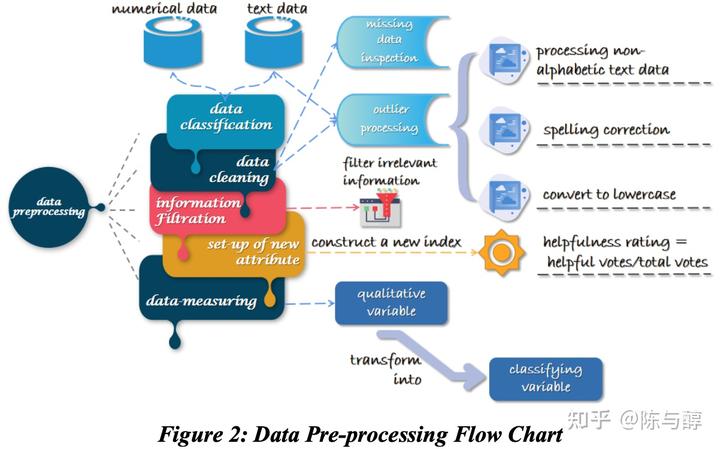
这里有个小tip:本题目属于数据分析类的建模题,因此最好把数据预处理的过程详细展示出来,从而更能体现论文的严谨性。
1.2 分词与情感分析
虽然评论文本数据已进行了初步处理,但仍然需要进一步的挖掘,而评论数据是非结构化的,需要不同的机制来提取信息。情感分析或观点挖掘是一个计算过程,用于确定作者对文本的态度是积极的、消极的还是中立的。对于评论数据,我使用NLTK库进行了初步的情感分析,以确定和量化每次评论的情感倾向。
使用NLTK库在Python3中构建基本情绪分析模型。预处理通过标记文本、规范化单词和去除噪声来进行。接下来,Ntlk emotional analyzer用于构建一个模型,并将文本与特定情感关联起来,并对其进行量化。通俗的说,即把每条评论量化为一个情感得分。如下图:
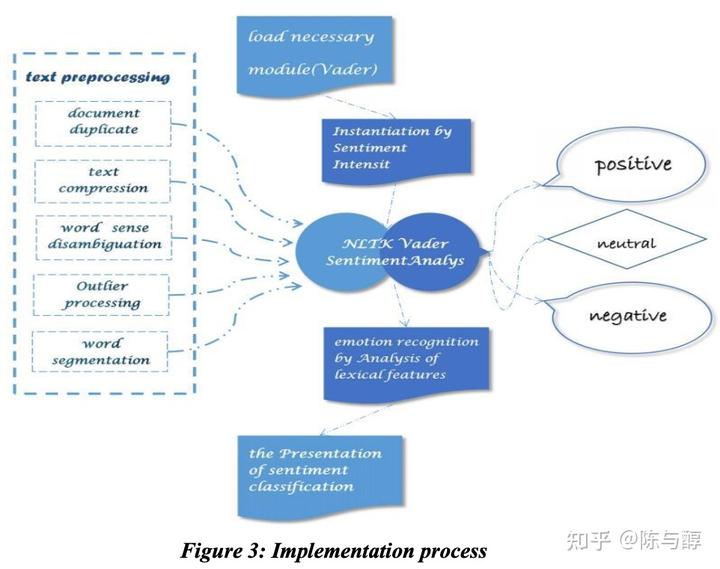
1.3 描述性分析
下表描述了这三种产品的star rating的总数、平均值和方差。我们还计算了helpful votes的平均值和评论中的单词数量和平均值。下图描述了它们的分布情况。
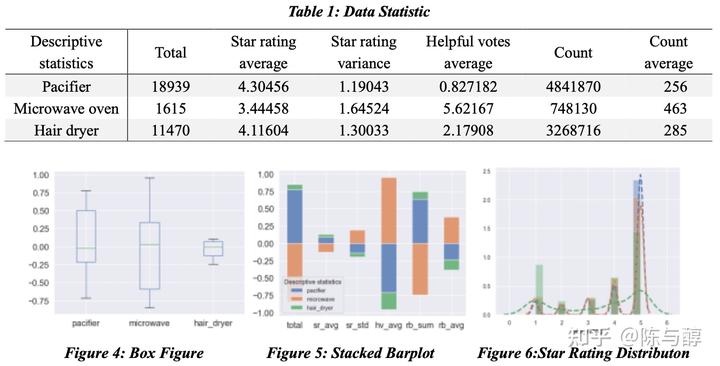
描述性分析和数据可视化对于建模没有特别明显的作用,但却是数据分析中必不可少的一个步骤,有助于我们更加直观地了解数据的分布情况,能够减少出现违背常识的分析结论的几率,也能够使论文的结构更完整和美观。
下图描述了helpfulness rating、star rating、评论长度和情感得分之间的关系。
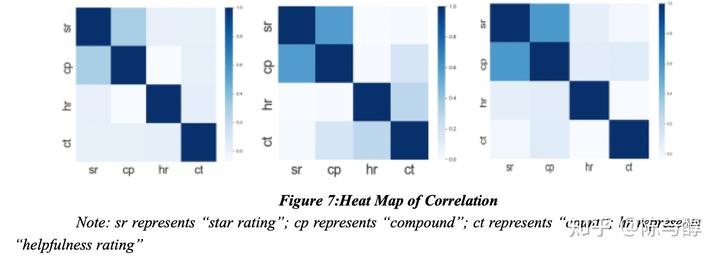
图中的颜色越深,两个指标之间的相关性就越大。我们可以发现,情感得分和star rating在三个指标中有很强的相关性。helpfulness rating和评论长度有轻微的相关性。
1.4 相关性分析
描述性分析类似于定性分析,在此基础上我们需要定量化地去分析指标之间的相关性。因此我们采用相关分析的方法,对 helpful votes的百分比( H_{r} )、star rating、每条评论中的单词数(count)和情感得分(compound)进行相关分析。皮尔逊相关系数测量结果如下:
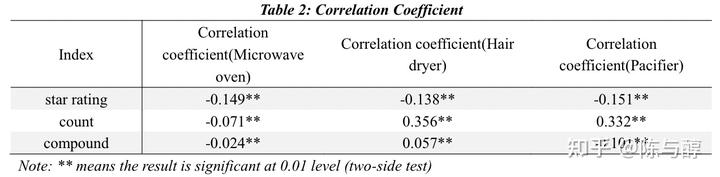
从上表中我们可以看出,对于三个数据集, H_{r} 和star rating、count和compound之间存在显著相关性(在双侧检验中均显著),这与可视化分析的结果一致。更具体地说,微波炉、吹风机和奶嘴的star rating与 H_{r} 呈负相关。吹风机和奶嘴的count与 H_{r} 呈正相关,而微波炉的count与 H_{r} 呈负相关。微波炉、奶嘴的compound与 H_{r} 呈负相关,电吹风的compound与 H_{r} 呈正相关。
1.5 多元逻辑回归模型
相关性分析一定程度上证明了我们可视化的结论,但这种分析显然不够,我们怎么知道诸如star rating的指标对于评论有用性的影响程度呢?回归模型是解决这类问题的经典方法。我们需要选择一个合适的回归模型。
因此,我们采用Multinomial logistic regression模型进一步分析star rating、评论长度和情感得分对helpfulness rating的影响,事实上,helpfulness rating是每个消费者投票(是或否)的累积结果。因此, helpful votes服从二项分布,logistic模型正好适用于这类数据的实证分析。多元logistic回归可以确定解释变量 x_{n} 在预测Y发生概率中的作用和强度。假设X是响应变量,P是模型的响应概率,相应的回归模型如下:
其中,事件的概率 p 是由解释变量 X_{i} 构成的非线性函数,表达式如下:
在这三个指标的基础上,我们引入了两个附加变量:star rating 的平方(SS)和评论长度的平方(CS),以进一步探讨star rating和评论长度对helpfulness rating的影响。
同时,考虑顾客是否为会员(vine)以及购买是否被验证(Verified Purchase,VP)对评论真实性和有效性的影响,我们将这两个指标也纳入自变量进行考虑。
综上,我们将自变量分为三个层次,分别代表直观评价(star rating、SS)、评论内容特征(评论长度、CS、情感得分)和评论者特征(vine,VP),在此基础上详细探讨影响helpfulness rating的各种原因。
对于因变量,我们根据其数值将其分为四类,即:
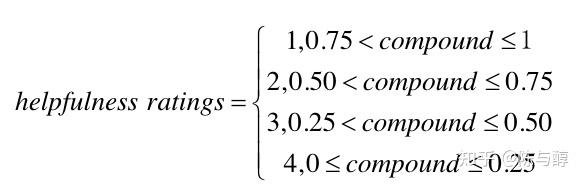
将自变量划分为几个部分,分别进行回归分析。模型1、2和3中的自变量以及回归系数汇总如下表所示。出于篇幅原因仅给出微波炉的结果,附录中包含了吹风机和奶嘴的结果。
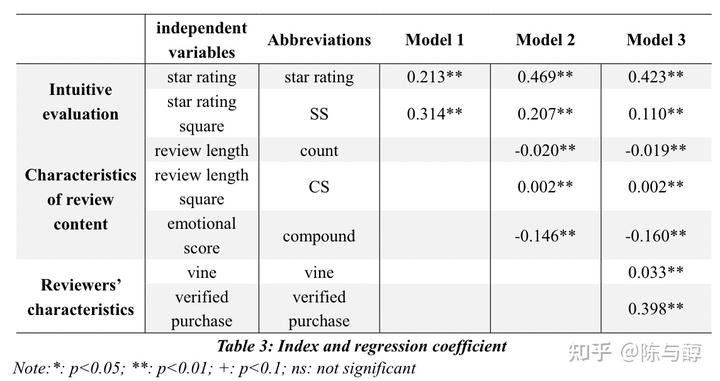
从上表可以看出,每个变量都通过了显著性检验。微波炉、电吹风和奶嘴的star rating回归系数均为正,star rating平方项的回归系数也为正。这表明star rating与评论的helpfulness rating之间存在“U型”关系,这与Mudambi和Schuff的研究结论相反。我们的分析表明,评分较高或较低的评论者可能是更愿意对产品表现出明确的态度(特别喜欢或特别讨厌),从而他们提供的评论更有价值;而给中星级的评论者,由于态度不那么鲜明,可能缺乏参考价值。
在模型1的基础上,将评论长度、评论长度的平方和情感得分添加到模型中。从表中的数据可以清楚地看出,评论长度项的回归系数为负,而评论长度的平方项回归系数为正,这表明评论长度和helpfulness rating之间的关系为“倒U型”。根据我们的分析,太短的评论通常内容有限,无法提供足够的有用信息;而过长的评论也许会提供很多有价值的信息,但其他客户可能没有耐心花时间和精力去阅读它们(我们需要给出符合常识的解释)。因此,具有高helpfulness rating的评论应具有中等长度。在模型2的基础上,在模型3中,我们引入其他与评论相关的功能,如Vine和Verified Purchase。可以看出,大部分客户都不是vine会员,很多购买都没有在样本数据中得到验证,因此很难对这两个指标进行分析并得出有价值的结论。尽管如此,他们使我们的模型更加完整和适用。
Model 2-Establish a Scoring System to Determine Product Positioning
接下来进入到step 2,根据三个数据集,每种产品都有数百种不同的品牌。如果Sunshine Company希望进入微波炉、电吹风、奶嘴等市场,准确把握各品牌的市场定位意义重大。不同品牌的市场定位主要取决于star rating和客户的评价。关于star rating的处理相对简单,所以我们主要讨论了如何处理客户评论的文本。
2.1 LDA Model
潜在Dirichlet分布是Blei等在2003年提出的一种生成性主题模型,也称为三层贝叶斯概率模型,具有文档(d)、主题(z)和单词(W)三层结构,可以有效地对文本进行建模。基于LDA主题模型,我们可以在数据集中挖掘潜在的文本主题,然后分析数据集的主要信息和相关的特征词。有关模型原理请自行查阅相关资料。
在基于LDA的分析之后,评论文本被划分到三个主题中,得到的结果是每个文本数据集中10个最常用的单词和它们在每个主题下的对应概率。下表显示了微波炉正面评价文本中的潜在主题,另一个描述了负面评价。吹风机和奶嘴的结果放在附录中。
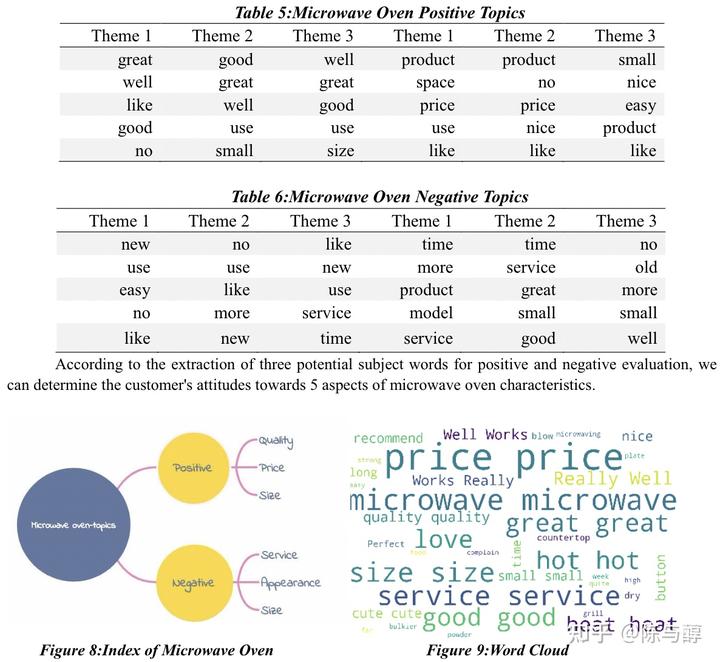
评论中这些高频词也可以反映客户在购买微波炉时的关注点,即质量、价格、尺寸、服务和外观。这五个指标能够全面反映一个产品。同样地,通过对奶嘴和吹风机的分析,得出这五个指标也可以作为衡量它们是否值得购买的标准,以质量、价格、尺寸、服务、外观和星级等为评价指标,我们建立了一个评分体系,对这三种产品进行综合评价,从而获得每个品牌产品的准确市场定位,为阳光公司制定一个良好的销售策略。我们的品牌评分系统的步骤如下:

2.2 Determine index score
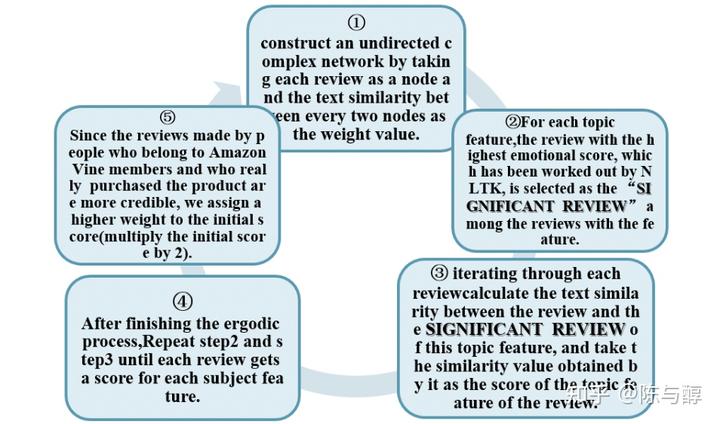
总结一下,该过程就是:使用LDA主题生成模型确定5个评论指标(质量、价格、尺寸、服务、外观,再加上star rating),引入一个遍历搜索算法计算具体5个指标下的具体评论得分(可使用matlab实现):
建立一个无向复杂网络,将每条评论作为一个节点,每两条评论的文本相似性作为边权值;
2. 对于每一个指标,拥有最高情感得分(由NLTK计算得到)的评论称为该指标下的“SIGNIFICANT REVIEW”;
3. 遍历每一条评论,计算每条评论与“SIGNIFICANT REVIEW”之间的文本相似性,将其作为该评论在指标下的得分;
4. 重复上述步骤,计算得到每条评论在5个评论指标下的得分;
5. 对于Vine客户和经过Verified Purchase认证的客户,我们认为其评论更具有可靠性,对于他们的评论得分将赋予更高的权重。
此外,需要考虑对不同的指标进行赋权,我们用层次分析法给出评价指标权重,得到加权后的指标体系,并基于系统聚类计算品牌相似度,将所有产品划分为10个品牌等级,找到优等品。这里是step 3的部分。
该处省略了AHP和聚类的原理描述,详见论文原文。注意:写美赛论文时,不能因为模型比较常见就省略描述模型原理的过程。
下表给出每种产品的5个一流品牌:

Model 3-Time Series Analysis
在step 4中,我们构建了一个时间序列分析模型来分析产品声誉变化。那么如何量化声誉?在本文中,我们用star rating和情感倾向来表示产品声誉。之后,通过分析产品的评论和star rating,我们可以预测产品声誉走向。根据统计数据,客户在购买商品时往往会更加关注评论,因此评论对产品声誉的影响比star rating更大。因此,我们将70%的权重分配给评论的平均情绪得分,将30%的权重分配给平均star rating。它们之和是产品声誉的综合得分。
基于我们的假设,产品声誉得分将受到时间序列自相关性的影响。因此,我们选择 p^{th} 阶自回归模型来拟合曲线,即AR(p)。
其中Y代表第n年的产品声誉得分。
a_{1}...a_{p} 表示不同滞后阶的影响系数。
\mu_{n} 代表均值为0,方差为 \sigma^{2} 的误差项。该分布与白噪声过程 WN(0,\sigma^{2}) 相匹配.
构建AR(1)模型预测产品声誉的综合得分。结果如下:以电吹风为例,为了观察产品声誉综合得分与时间变化趋势之间的关系,我们在SPSS中对时间序列进行了分析和预测。模型原理和参数估计详见论文原文。
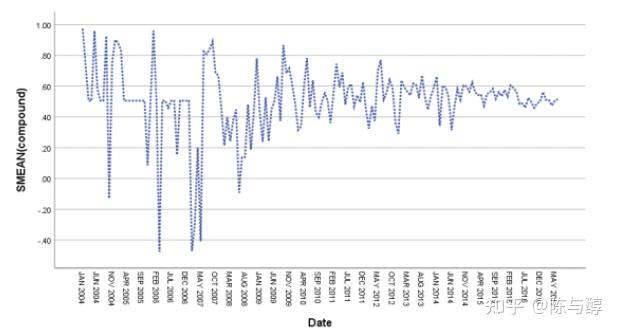
通过以上序列图,我们发现时间序列的季节波动基本不变,因此我们选择加法模型对季节因素进行分解。剔除季节性因素后,误差序列值很小,因此长期趋势和周期性变化序列(长期趋势+周期性变化)与季节性因素修正后的序列(长期趋势+周期性变化+不规则变化)基本吻合。
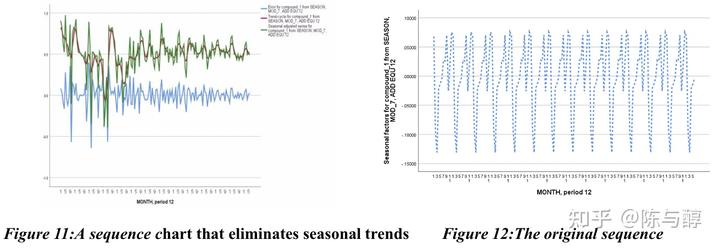
通过对季节性趋势的分析,可以发现,趋势在每年第一季度先下降,然后上升到第一个峰值,然后在急剧下降后,有明显的上升趋势,大约在第八个月达到第二个峰值,然后出现小幅下降。此后,它在10月份左右达到峰值,然后一直下降到第二年初。为了分析季节性变化的原因,我们用时间图展示了年销售量(如下图)。从中可以看出,声誉和销售的时机具有大致相同的季节性趋势,表明随着销售的增加,客户更可能给予好评,因此我们得出结论,这与实际情况是一致的。例如在夏天,人们会更频繁地洗头,因此他们倾向于在6月至8月购买吹风机,并有更高的可能性给出好评;然而,10月左右进入冬天,气温变冷,吹风时间变长,这也可能会提高吹风机的需求量和口碑。(注意给出符合常识性的解释)
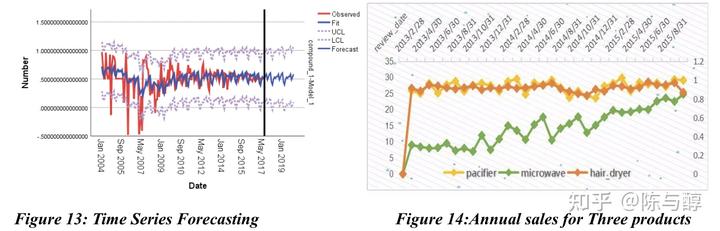
通过时间序列预测,我们得到2016-2019年的数据,并发现电吹风的声誉和需求与季节性高度相关,未来很可能保持稳定的季节性循环模式,微波炉和奶嘴大致相同,微波炉的声誉综合得分在4月和10月达到峰值。通过以上分析,我们认为吹风机、微波炉、奶嘴的市场前景不容乐观,阳光公司可以根据季节性趋势,在产品声誉度上升时,增加销售份额,或在声誉即将下降之前减少投资。
Model 4-Distributed lag model
现在,我们只剩下两个问题需要解决了,一个是研究前期产品的star rating对后期评论的影响。特定star rating会引起更多评论吗?例如,在看到一系列低星级的评级之后,客户是否更有可能撰写某种类型的评论?
我相信对于这个问题的处理,一定涌现了五花八门的方法和模型。

出于金融学背景,队友Z提出使用计量经济学中的分布滞后模型来处理该题。
在这一部分中,我们应用分布滞后模型来确定客户的评论是否会受到其他人star rating的影响。分布滞后模型是基于被解释变量受解释变量的影响,分布在不同时期的解释变量的滞后值上,理论上也是在时间序列模型的范畴内。
其中,s是滞后长度。
该模型中的每个系数反映了解释变量的每个滞后值对解释变量的不同影响,通常称为乘数效应:

具体而言,我们基于滞后3个周期的二阶Almon多项式分布滞后模型,建立当前评论与以往star rating和评论的回归方程,以确定是否存在以往star rating影响当前客户评论的现象。我们选取三种具体产品的数据进行分析。
下面的有限分布滞后模型用Almon 方法进行估计,系数用二次多项式估计:
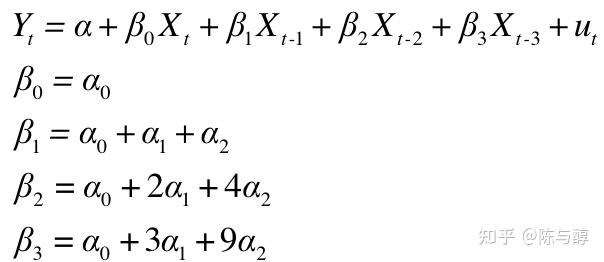
于是原始模型可以转变为:
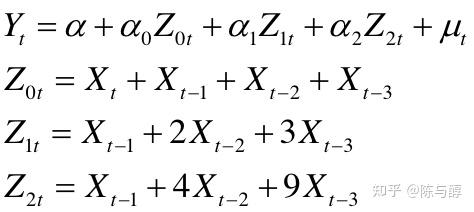
通过回归得到分布滞后模型的最终估计公式。回归结果如下:
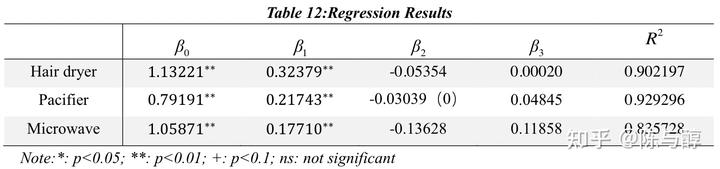
这三种产品过去的star rating综合得分与当前评论的情感得分之间的回归方程如下:

因此,我们可以证明,客户当前的评价与过去的star rating和评价之间存在相关性,即客户当前的评价将受到过去评级和评价的影响。
Model 5-Correlation Analysis between Star Rating and Comments
最后一个问题,即研究诸如“热情”,“失望”之类的评论词语是否与评级水平密切相关。严格来说,我们前面的建模已经对这个问题进行了一定解释,但仍然有必要在论文相应的地方给出具体处理方法。
根据时间序列模型,我们可以快速得到客户评论的拐点。通过分析这些拐点对应的评论中的具体描述词语,并与评论对应的star rating进行比较,我们很容易知道这些词是否与star rating密切相关。在上面的模型中,我们已经得到了每个时间段内的评论和star rating的平均分。通过比较两者随时间变化的同步性,我们可以得出结论,带有正面词的评论对应的star rating较高,而带有负面词的评论对应的star rating较低。(由于空间限制,文中只放了微波炉图片,附录有吹风机和奶嘴的图片。)
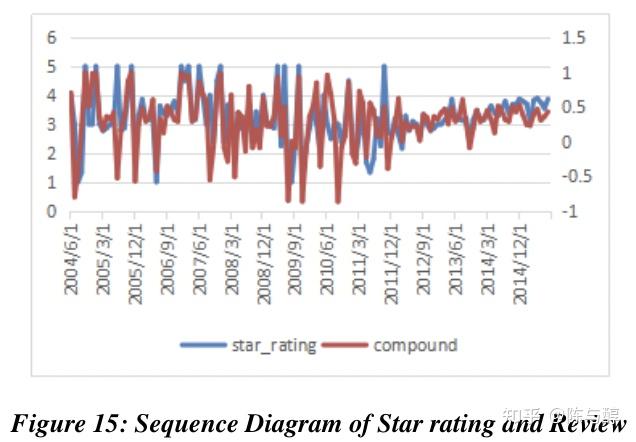
然而,从图表中仍然可以看出,一些star rating较高的评论的情感得分较低,因此不排除有高分、差评(反之亦然)和虚假评论。
最后是论文的敏感性分析、模型评估和给Sunshine Company写的信,感兴趣的朋友欢迎阅读原文。
美赛论文的分享到此结束,如果有关于数模比赛准备过程或者组队之类的问题也欢迎私信我和我交流~

最后宣传一波我的CSDN博客,欢迎感兴趣的朋友关注,日常分享论文解读和编程相关帖子:
