1、Why ?
相信在你的电脑里,一定存有一些已经下载好的视频文件,如果你硬说没有,那我相信你曾经总有吧?曾经也没有?那我想对你说曾经免费的时候你不下载,直到电影都收费才后悔那些年错过下载的大片。
好了,言归正传,在日常我们一定见过很多后缀为avi, mp4, rmvb, flv等格式的视频文件。而很少有人真正挖掘这些文件到底是什么?其实以上格式都是封装视频的封装格式。
什么是封装格式 ?
把音频数据和视频数据打包成一个文件的规范。不用封装格式差距不大, 各有千秋。
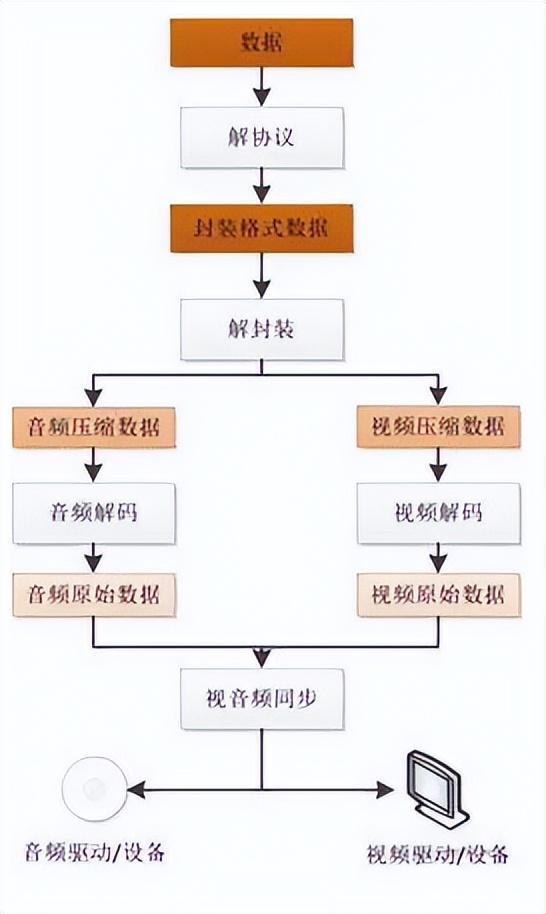
从视频播放器播放一个互联网上的视频文件
需要经过以下几个步骤:解协议,解封装,解码视音频,视音频同步。如果播放本地文件则不需要解协议,其他步骤相同。
为什么要对视频数据进行编码
视频编码的主要作用是将视频像素数据(RGB,YUV等)压缩成视频码流,从而降低视频的数据量。举个例子:比如当前手机的屏幕分辨率是1280 * 720(即我们平时在视频软件中可选的720P),假设一秒钟30帧(即1秒钟传输30张图片),那么一秒钟的数据为 1280 * 720(位像素)*30(张) / 8(1字节8位)(结果B),也就是一秒钟的数据量为3.456M数据量,一分钟就是207.36M,那么我们平常看一部电影就是大约18G的流量,试想下如果是这样对于存储即网络传输是件多么恐怖的事情。
正是因为以上原因,我们需要对视频数据进行编码,以最小程序减小清晰度与最大程序降低数据量,而H264正是目前广泛使用的一种编码格式,下面我们将主要介绍下H264的码流结构。
2、码流结构
刷新图像概念
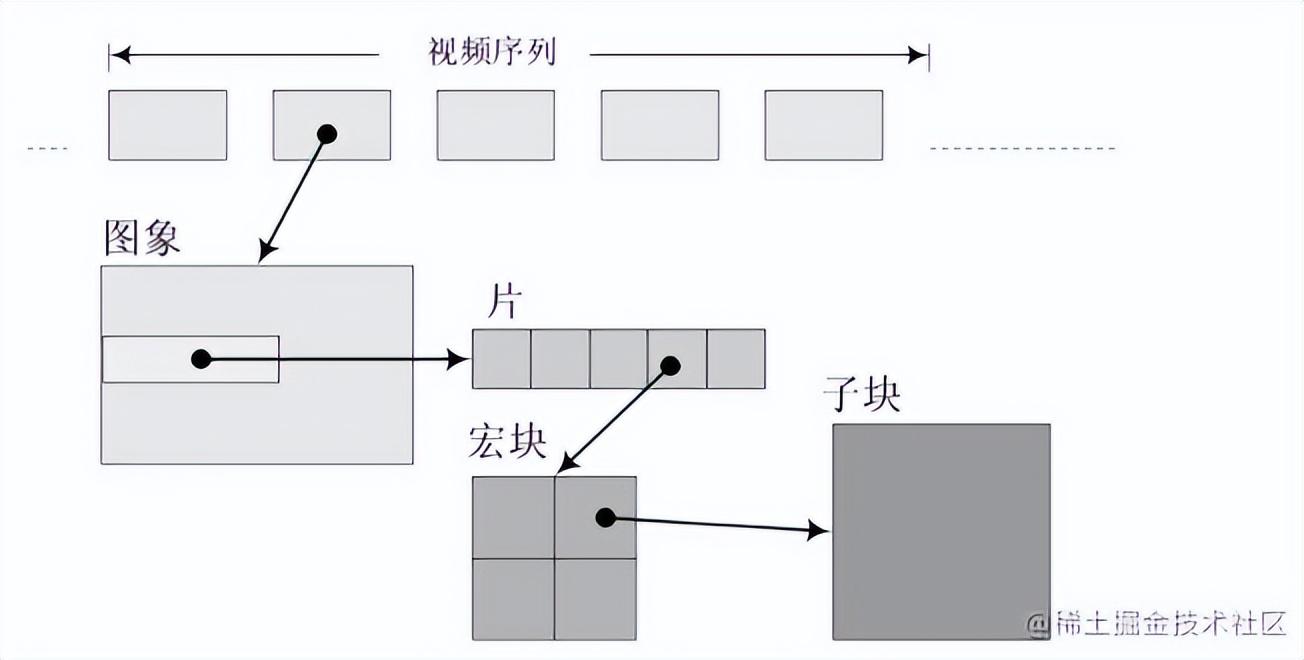
在我们的印象中,一张图片就是一张图像,而在H264中图像是个集合的概念。
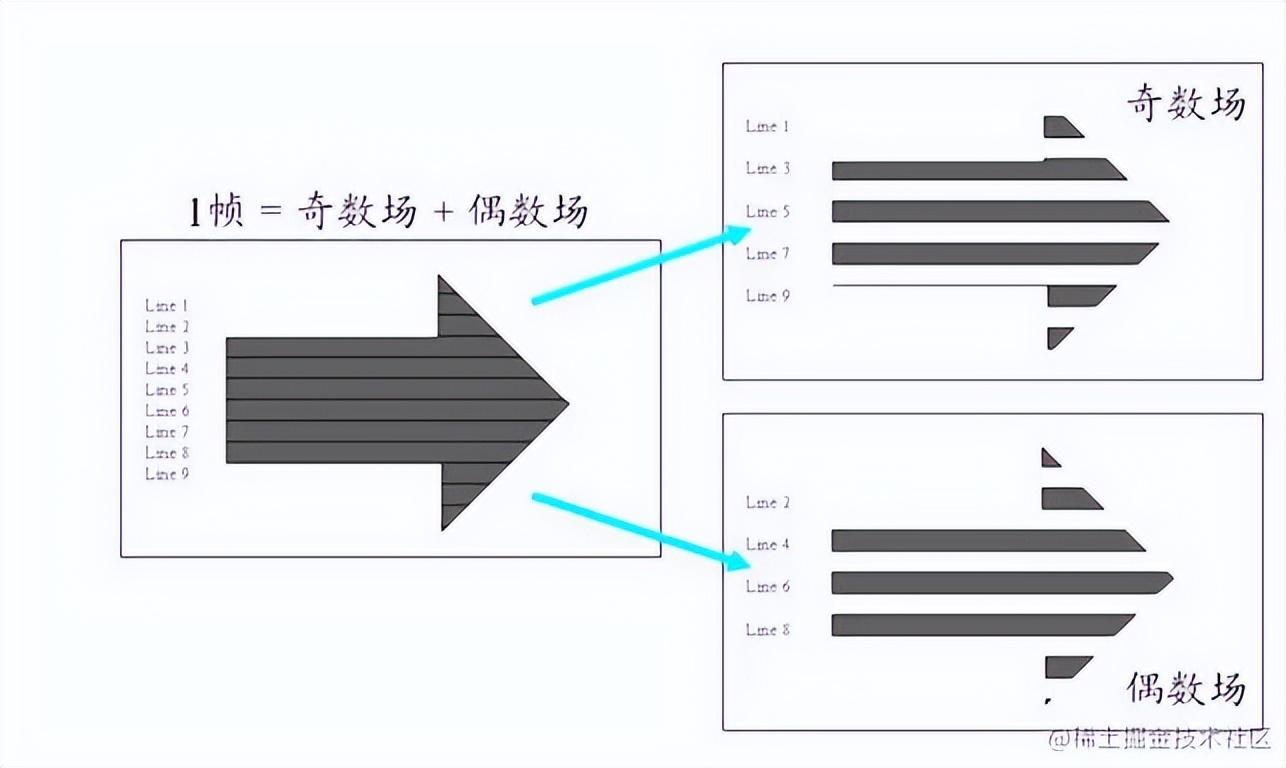
帧、顶场、底场都可以称为图像。一帧通常就是一幅完整的图像。当采集视频信号时,如果采用逐行扫描,则每次扫描得到的信号就是一副图像,也就是一帧。当采集视频信号时,如果采用隔行扫描(奇、偶数行),则扫描下来的一帧图像就被分为了两个部分,这每一部分就称为「场」,根据次序分为:「顶场」和「底场」。「帧」和「场」的概念又带来了不同的编码方式:帧编码、场编码。逐行扫描适合于运动图像,所以对于运动图像采用帧编码更好;隔行扫描适合于非运动图像,所以对于非运动图像采用场编码更好。

H264原始码流
C++音视频学习资料免费获取方法:关注音视频开发T哥,点击「链接」即可免费获取2023年最新C++音视频开发进阶独家免费学习大礼包!
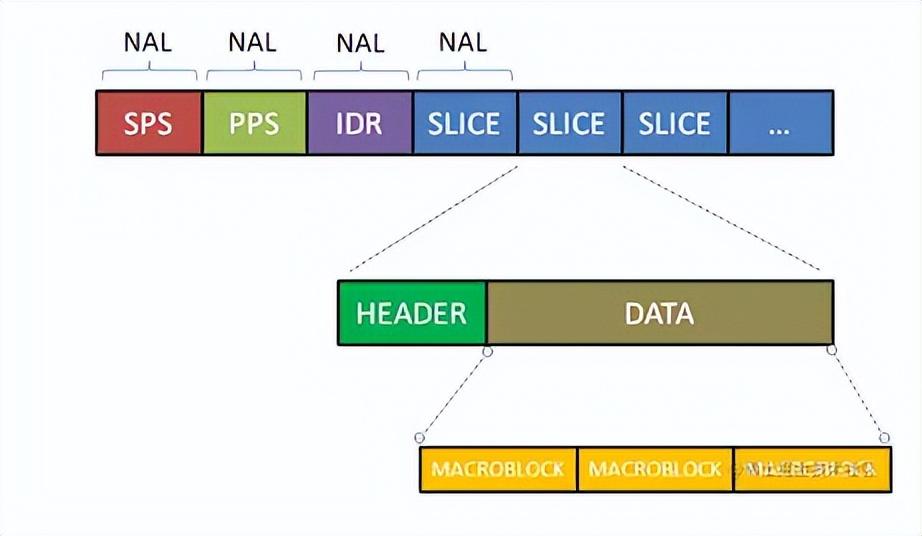
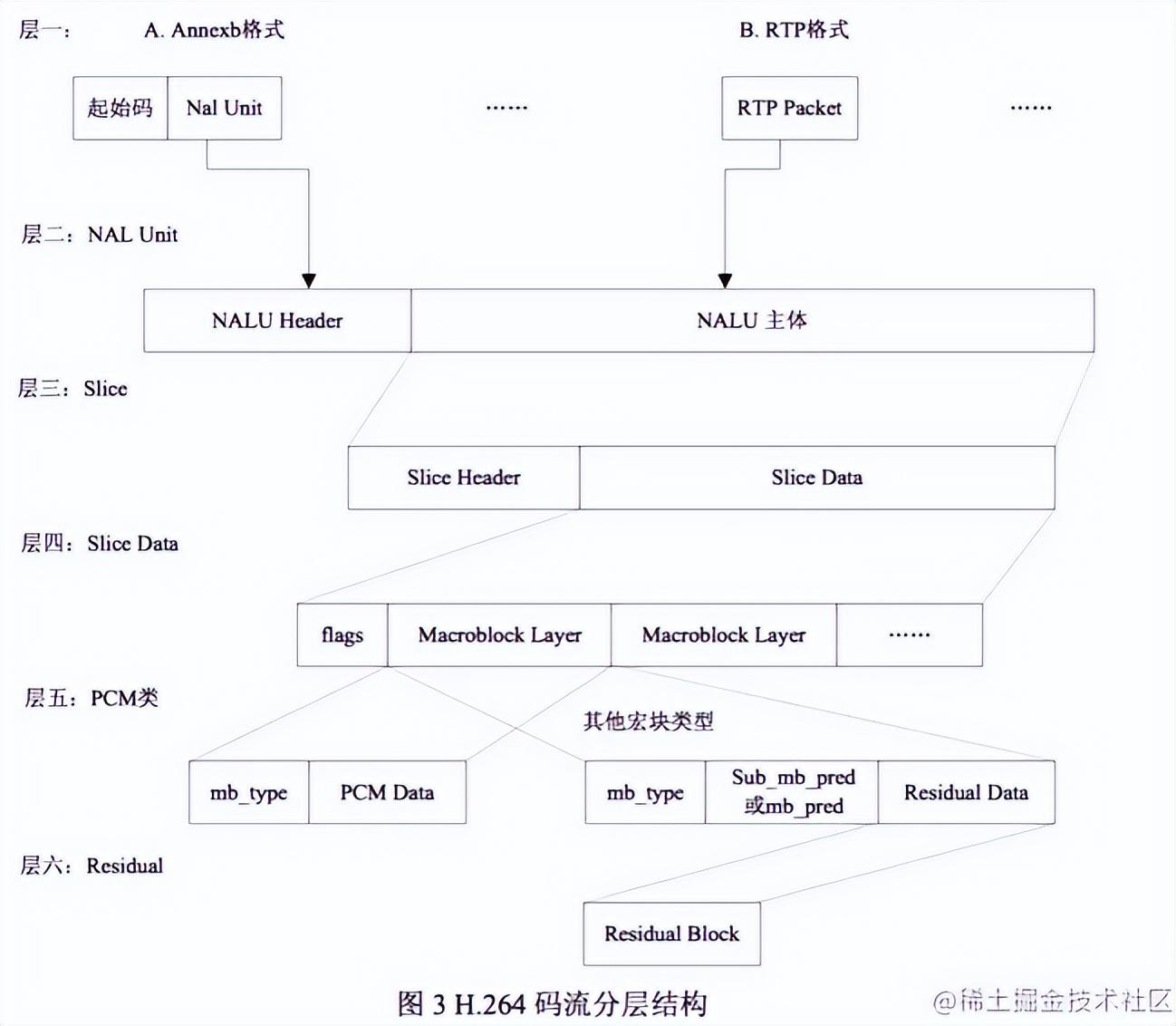
一个原始的H.264 NALU 单元常由 [StartCode] [NALU Header] [NALU Payload] 三部分组成

例如:
00 00 00 01 06: SEI信息
00 00 00 01 07: SPS
00 00 00 01 08: PPS
00 00 00 01 05: IDR Slice
复制代码
什么是切片(slice)?
片的主要作用是用作宏块(Macroblock)的载体(ps:下面会介绍到宏块的概念)。片之所以被创造出来,主要目的是为限制误码的扩散和传输。
那么片(slice)的具体结构,我们用一张图来直观说明吧:
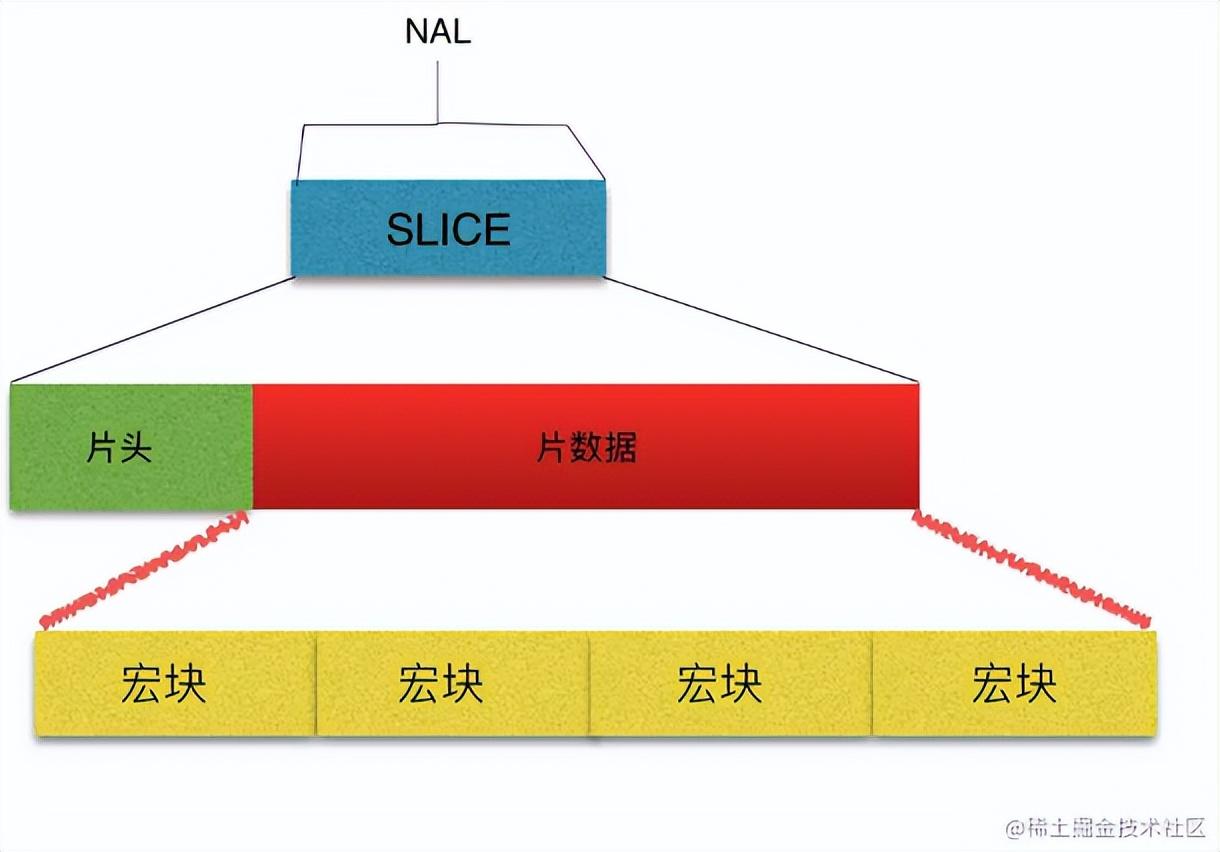
上图结构中,我们不难看出,每个分片也包含着头和数据两部分:
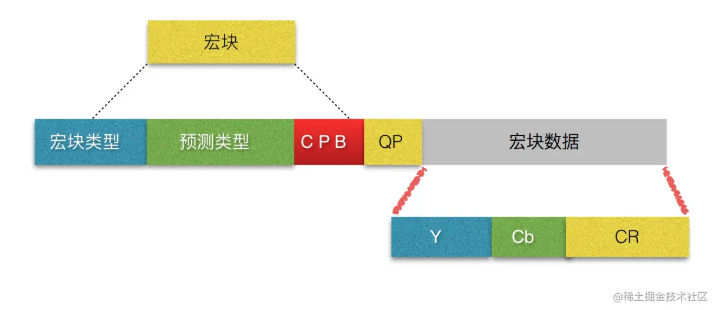
什么是宏块?
下面是宏块的结构图:
切片(slice)类型跟宏块类型的关系
切片(slice)来讲,分为以下几种类型:
2.1 整体结构
H.264的码流结构并没有那么复杂,编码后视频的每一组图像(GOP,图片组)都给予了传输的序列(PPS)和本身这个帧的图像参数(SPS),所以,整体给够如下
GOP 图像组主要形容一个I帧到下一个I帧之间间隔了多少帧,增大图片组能有效的减少编码后视频的体积,但是也会降低视频质量,至于怎么取舍,得看需求。
2.2 NALU头部的类型
enum nal_unit_type_e
{
NAL_UNKNOWN = 0, // 未使用
NAL_SLICE = 1, // 不分区、非 IDR 图像的片(片的头信息和数据)
NAL_SLICE_DPA = 2, // 片分区 A
NAL_SLICE_DPB = 3, // 片分区 B
NAL_SLICE_DPC = 4, // 片分区 C
NAL_SLICE_IDR = 5, / ref_idc != 0 / // IDR 图像中的片
NAL_SEI = 6, / ref_idc == 0 / // 补充增强信息单元
-
参数集是 H.264 标准的一个新概念,是一种通过改进视频码流结构增强错误恢复能力的方法。
NAL_SPS = 7, // 序列参数集 (包括一个图像序列的所有信息,即两个 IDR 图像间的所有图像信息,如图像尺寸、视频格式等)
NAL_PPS = 8, // 图像参数集 (包括一个图像的所有分片的所有相关信息, 包括图像类型、序列号等,解码时某些序列号的丢失可用来检验信息包的丢失与否)
-
NAL_AUD = 9, // 分界符
NAL_FILLER = 12, // 填充(哑元数据,用于填充字节)
/ ref_idc == 0 for 6,9, 10 (表明下一图像为 IDR 图像),11(表明该流中已没有图像),12 /
};
ps: 以上括号()中的为类型描述3、补充说明
I帧
P帧
B帧
帧内编码帧
前向预测编码帧
双向预测编码帧
I帧通常是每个GOP的第一帧,经过适度压缩,作为随机访问的参考点,可看成一个图片经过压缩后的产物
通过充分低于图像序列中前面已编码帧的时间冗余信息来压缩传输数据编码图像,也叫预测帧
既考虑与源图像序列前面已编码帧,也顾及源图像序列后面已编码帧之间的时间冗余信息来压缩传输数据量的编码图像,也叫双向预测帧
3.1 I,P,B帧3.2 DTS,PTS3.3 GOP
GOP是画面组,一个GOP是一组连续的画面。 GOP一般有两个数字,如M=3,N=12.M制定I帧与P帧之间的距离,N指定两个I帧之间的距离。那么现在的GOP结构是 I BBP BBP BBP BB I
3.4 IDR
一个序列的第一个图像叫做 IDR 图像(立即刷新图像),IDR 图像都是 I 帧图像。
I和IDR帧都使用帧内预测。I帧不用参考任何帧,但是之后的P帧和B帧是有可能参考这个I帧之前的帧的。IDR就不允许这样。
帧内预测和帧间预测

我们可以通过第 1、2、3、4、5 块的编码来推测和计算第 6 块的编码,因此就不需要对第 6 块进行编码了,从而压缩了第 6 块,节省了空间

可以看到前后两帧的差异其实是很小的,这时候用帧间压缩就很有意义。 这里涉及到几个重要的概念:块匹配,残差,运动搜索(运动估计),运动补偿. 帧间压缩最常用的方式就是块匹配(Block Matching)。找找看前面已经编码的几帧里面,和我当前这个块最类似的一个块,这样我不用编码当前块的内容了,只需要编码当前块和我找到的快的差异(残差)即可。找最想的块的过程叫运动搜索(Motion Search),又叫运动估计。用残差和原来的块就能推算出当前块的过程叫运动补偿(Motion Compensation).
4、参考文章:
深入浅出理解H264, 从零了解H264结构, 音视频基础
原文链接:H.264码流结构 (H.264 Data Structure) - 掘金










