作者 | 西西
编辑 | 陈彩娴
众所周知,算法、算力与数据是人工智能(AI)发展的“三驾马车”,吴恩达等学者也常说:以数据为中心的AI,或数据驱动的AI。
由此可见,近年来激增的数据量是 AI 腾飞的源动力之一,数据在 AI 中扮演重要角色。那么,人们口中常说的“大数据”,规模究竟有多大呢?
出于好奇心,一位意大利物理研究者 Luca Clissa 调查了 2021 年几个知名大数据源(谷歌搜索、Facebook、Netflix、亚马逊等等)的规模大小,并将它们与大型强子对撞机(LHC)的电子设备所检测到的数据做了对比。

地址:
毫无疑问,LHC 的数据量是惊人的,高达 40k EB。但商业公司的数据量也不容小觑,比如,亚马逊S3存储的数据量也达到了大约 500 EB,大致相当于谷歌搜索(62 PB)的 7530 倍。
此外,流数据在大数据市场中也占有一席之地。Netflix 和电子通信等服务产生的流量比单纯的数据生产者要多一到两个数量级。
LHC 的数据量
根据 Luca Clissa 的调查,2021年各大知名数据源的体量大约如下:
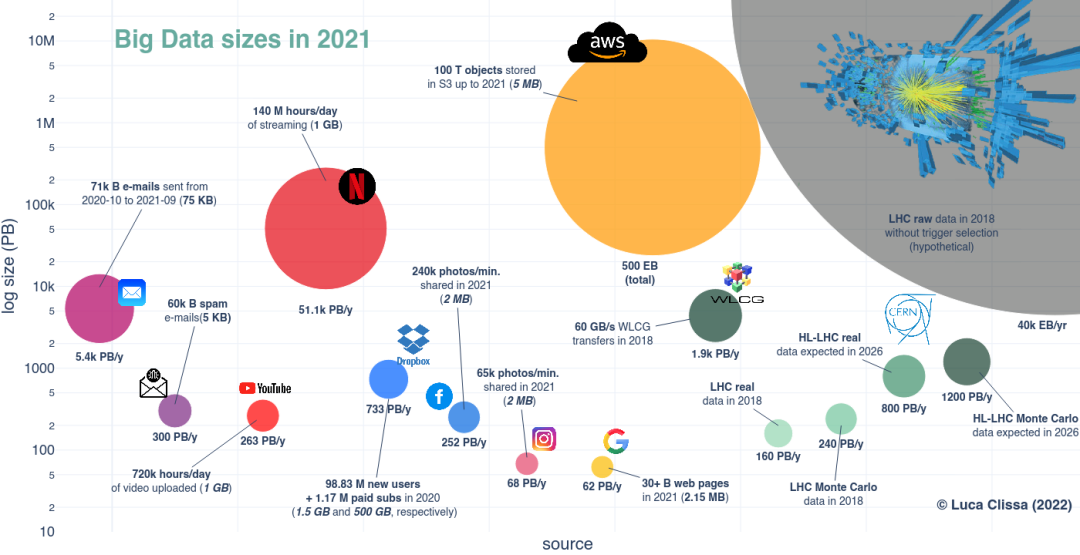
图注:2021年的大数据规模
右上角(灰色部分)是欧洲核子研究组织(CERN)大型强子对撞机(LHC)实验的电子设备所检测到的数据,规模最大。
在上一次运行(2018 年)中,LHC 在四个主要实验(ATLAS、ALICE、CMS 和 LHCb)中的每一个实验里,每秒产生大约 24 亿次粒子碰撞,每次碰撞可以提供约 100 MB 数据,因此预计年产原始数据量约为 40k EB(=10亿千兆字节)。
但根据目前的技术和预算,存储 40k EB 数据是不可能的。而且,实际上只有一小部分数据有意义,因此没有必要记录所有数据。记录的数据量也降低到了每天大约 1 PB,2018 年的最后一次真实数据只采集了 160 PB,模拟数据 240 PB。
此外,收集的数据通过 WLCG (全球LHC计算网络)不断传输,2018 年产生了 1.9k PB 的年流量。
不过,欧洲核子研究组织(CERN)正在努力加强 LHC 的能力,进行 HL-LHC 升级。这个过程预计生成的数据量将增加 5 倍以上,到 2026 年,每年估计产生 800 PB的新数据。
大厂数据量对比
大公司的数据量很难追踪,且数据通常不会公开。对此,Luca Clissa 采用了费米估算法(Fermi estimation),将数据生产过程分解为其原子组成部分,并做出合理的猜测。
比如,针对特定数据源,检索在给定时间窗口内产生的内容量。然后通过对这些内容的单位大小的合理猜测来推断数据总量,例如平均邮件或图片大小,1 小时视频的平均数据流量等等。
他对谷歌搜索、YouTube、Facebook等等数据源进行了估算,结论如下:
谷歌搜索:最近的一项分析估计,Google 搜索引擎包含 30 到 500 亿个网页。根据 Web Almanac 所提供的信息,假设谷歌的年度平均页面大小约为 2.15 MB,截至 2021 年,Google 搜索引擎的数据总规模应约为 62 PB。
YouTube:根据 Backlinko 的数据,2021 年用户每天在 YouTube 上上传的视频时长为 72 万小时。假设平均大小为 1 GB(标准清晰度),2021年 YouTube 的数据大小约为 263 PB。
Facebook 与 Instagram:Domo 的 Data Never Sleeps 9.0 报告估计,2021 年 Facebook 与 Instagram 每分钟上传的图片数量分别为 240k 和 65k。假设平均大小为 2 MB,则总共大约为 252 PB 和 68 PB。
DropBox:虽然 Dropbox 本身不产生数据,但它提供了云存储解决方案来托管用户的内容。2020年,公司宣布新增用户 1 亿,其中付费订阅用户达到 117 万。通过推测免费和付费订阅的占用率分别为 75%(2 GB)和 25%(2 TB),Dropbox 用户在 2020 年所需的存储量约为733 PB。
电子邮件:根据 Statista 的数据,从 2020 年 10 月到 2021 年 9 月,用户大约传送了近 131,000 亿次电子通信(包含 71,000 亿封电子邮件和 60,000 亿封垃圾邮件)。假设标准邮件和垃圾邮件的平均大小分别为 75 KB 和 5 KB ,我们可以估计电子邮件的总流量约为 5.7k PB。
Netflix:Domo 估计,2021 年 Netflix 用户每天消耗 1.4 亿小时的流媒体播放,假设每小时 1 GB(标准定义),总计大约 51.1k PB。
亚马逊:亚马逊网络服务 (AWS) 的首席布道师 Jeff Barr称,截至 2021 年,亚马逊 S3 (Simple Storage Service)中存储了超过 100 万亿个对象。假设平均每桶的对象大小为 5 MB ,那么存储在 S3 中的文件的总大小则约等于 500 EB。
总的来说,科学数据可以在数量上与商业数据源相媲美。
参考链接:
1.
2.
3.
4.
5.
6.
7.
8.