文章目录
大数据时代 数字与人类文明
数字是人类发明的最重要的概念之一,与整个人类文明进程相伴相生
早在8000年前美苏尔地区商人利用泥球计算商品销量

商鞅也说过经典的“强国知十三数“:竟内仓、口之数,壮男、壮女之数,老、弱之数,官、士之数,以言说取食者之数,利民之数,马、牛、刍藁之数。
我国古代的孙子兵法也有五条基本原则:“度(国之大小)、量(粮草资源多少)、数(军队数量多少)、称(各方实力对比)、胜“
从这些概念中都可以明白,数字是从古至今中人类一直在使用的东西,并且伴随着人类的发展也在不断的完善与进步。
对数字的利用在推动人类文明进步的时候都发挥了重大作用例如:美国制宪会议。

在制宪会议中,由于在制定参众两院分权机制的过程中,众议院的席位要按照人口多少来进行分配,拥有众多黑奴的南方各州于是就黑奴是否应该纳入人口总数与北方各州展开了激烈辩论。最终,大会决定,每隔黑奴按照3/5个白人(自由人)的标准纳入南方人口的总数。这个3/5页写进了宪法,成为了黑奴不平等的历史见证。但就当是而言,这个数字的制定,为推动宪法制定做出了重大贡献。
并且数字作为基本工具,为整个科学大厦奠定了基石
普查与统计学
人口普查是人类第一次有意识的、大规模的利用数据,统计学也就在人口普查中诞生了。

人类最早的统计活动,就是起源于和人口情况相关的社会调查。而统计(Statistics)一词也最早见于17世纪的德国,原意为国势学。
最初,人口普查时为了征税、评估国家的军事实力、实施社会控制。而后,纳入普查范围内
的项目数越来越多,普查本身的细分程度也不断加深,统计的难度和工作量不断增加。当时十八世纪的美国,每隔十年就需要进行一次普查,统计数据就要耗费8年。由此催生了自动制表技术抽样统计推断的一系列方法。
统计学成为近代数据科学最前沿的领域的发展与四个特质是息息相关的:
始终站在数据应用的第一线向各个垂直细分领域渗透持续不断的价值产出推动理论创新与技术创新

统计学所推动的数据新知
所谓数据,是指指用于记录某项客观事物运行状态或事物属性的有序数字集合,而数据分析则是挖掘数据所蕴藏的规律,而数字规律,即事物规律,然后用这些规律进一步的去指导生产生活,来不断的完善人们的生活。
统计学之殇:全美流感预测
2009年出现了一种新型流感病毒,这种甲型H1N1流感结合了导致禽流感和猪流感的病毒特点,在短短几周之内迅速传播开来。全球的卫生机构都担心一场致命的流感病毒即将来袭,更有评论家警告说,可能会爆发大规模流感。
然而更加糟糕的是,针对这个问题我们还没研发出对抗这种新型流感病毒的疫苗,因此能做的事情只是根据病毒出现地方进行应急防范,以延缓传播速度。这就要求必须先知道这种流感病毒出现在了哪里。
然而,患者只会因为患病后,甚至患病多日后才回去意愿,因为医疗机构的统计汇总效率比较底下,导致上报疾控中心需要时间,并且统计汇总也需要时间,造成的后果是公共卫生机构通常在两周后才能统计出全国各地患病信息这也导致了公共卫生机构在疫情爆发的关键时期反而无所适从。
但是,在H1N1爆发的几周前,谷歌公司的工程师们在《自然》杂志上发表一篇论文,论述了如何利用人们在网上的搜索记录来完成全美冬季流感的传播预测,甚至可以精确到特定的地区和州,这是因为他们利用了5000万条人们的检索词频和美国疾控中心在2003年至2008年间流感传播时期的数据进行比较,并通过这些搜索记录来预测这些是否患上了流感,最终这项研究最终大获成功,他们的算法最终发现了45条检索词条的组合,最终预测结果和官方数据相关性高达97%,下面是预测的结果比较。
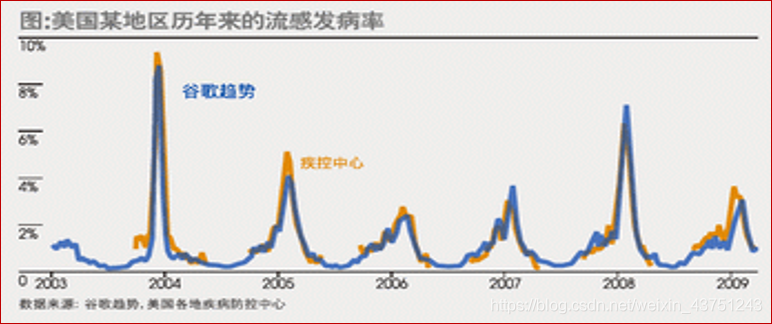
通过对2009年甲型H1N1流感的预测可以看出,两种统计方法表现出了两种截然不同的效率:
谷歌的预测可以为公共卫生机构的预防流感措施部署提供极有价值的信息,更关键的是,这是一种从未使用过的预测工具。该事件所代表的价值观和方法论,都深刻的影响了我们看待和使用数据的方法。
患病人次预测案例
我们希望通过这次案例获取患病人次的一般规律,进行患病人次的预测。
首先进行背景介绍:
然后我们进行目标分析,我们希望可以达成三点:
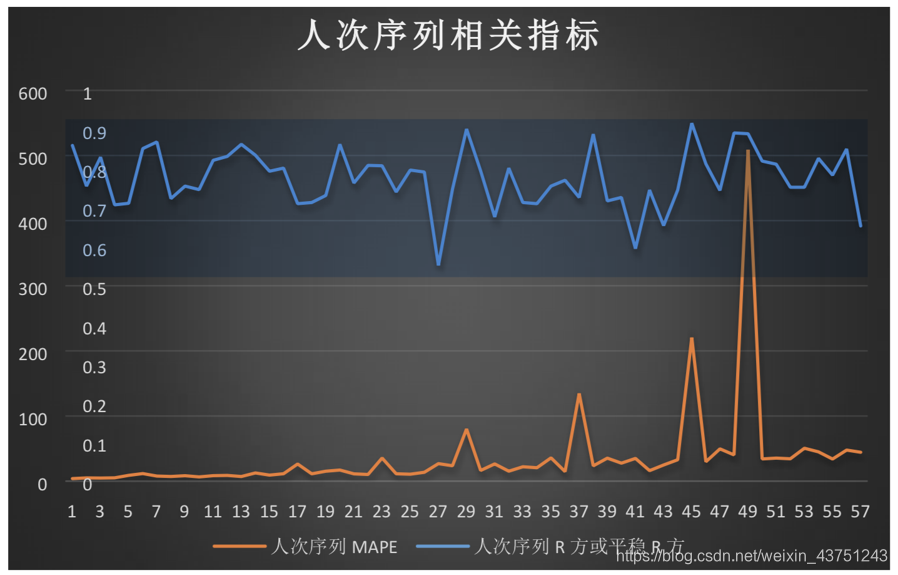
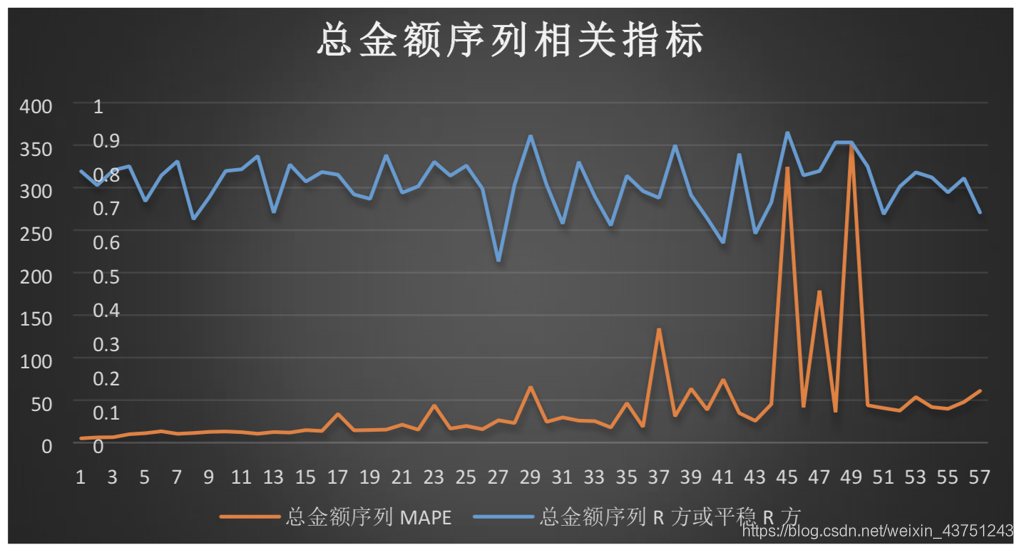
我们选择时间序列模型进行分析,查看一下数据图。
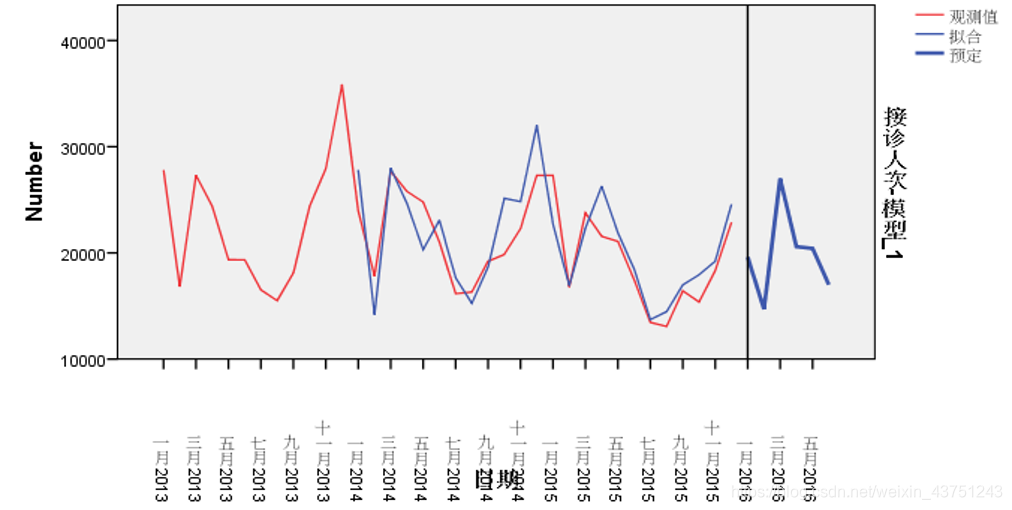
下面查看实际的患病人次与预测的人次之间的差距

通过对结果进行分析可以看出,以季度为单位进行迭代式动态预测,以误差率作为评判指标,预测集和训练集无交集,可见模型较为稳健,并将误差率控制在5%-10%左右。

大数据时代
让我们简单复盘一下谷歌公司如何做到这么精准的预测,在我看来主要是因为拥有三点:
在这个大数据时代,所有的大型互联网公司都在朝向大数据领域发力,而上述谷歌公司所拥有的的三点,将会最终构成推动数据科学发展的三驾马车。
数据、算法、计算资源 摩尔定律
IT技术的蓬勃发展,可以用摩尔定律准确的描述,1965年,英特尔创始人之一戈登摩尔在考察计算机硬件的发展规律后,提出了著名的摩尔定律。
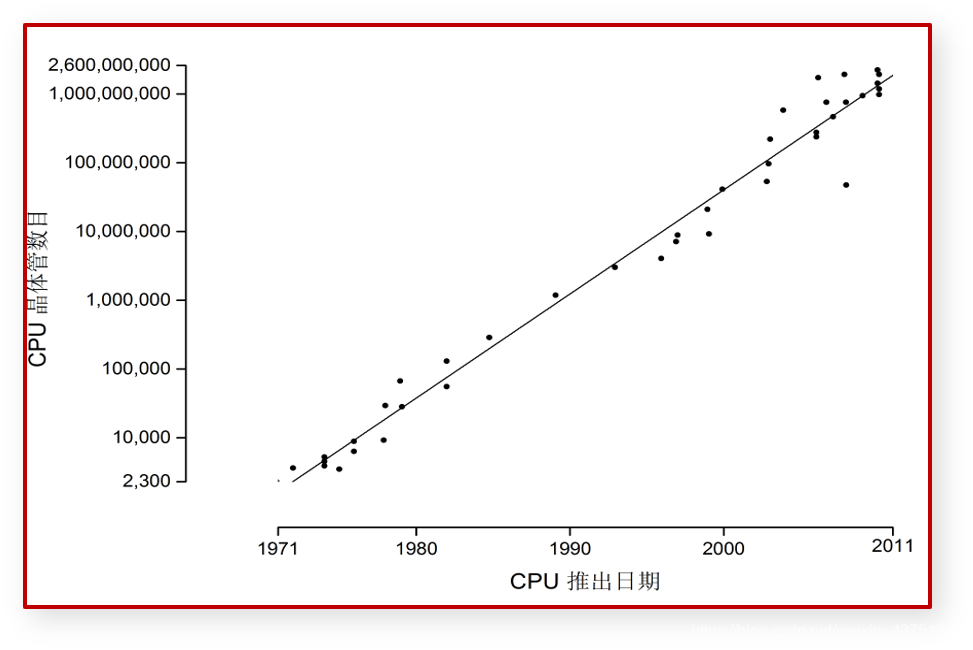
该定律认为,同一面积芯片上可容纳晶体管的数量,每隔16-24个月将翻一倍,计算性能也将翻一倍。换而言之,也就是每隔16-24个月,单位价格可购买到的计算能力将翻一倍。在随后的几十年内,摩尔定律被无数次的被印证。
而同步发展的还有网络宽带和物理存储容量

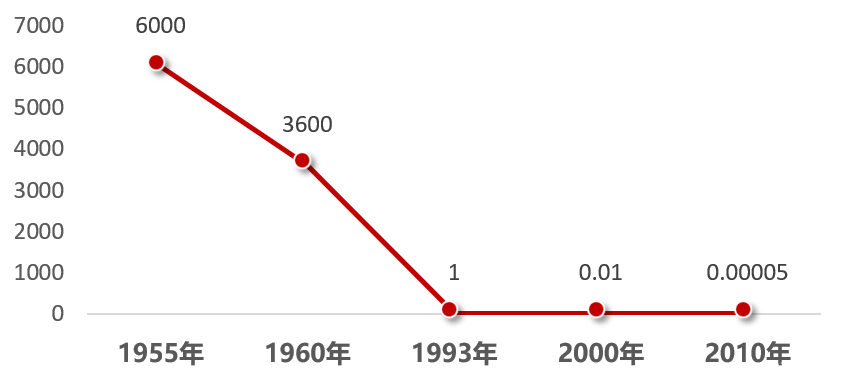
下图是硬盘存储器一兆节价格一览图(美元),从图片中可以看出,半个多世纪以来,存储器价格几乎下降到原来价格的亿分之一。
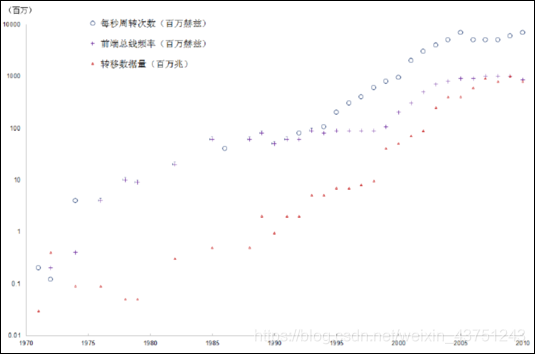
下图是网络宽带变化的趋势
OTT式技术创新
伴随着物理硬件升级,IT领域的OTT式技术革新,分布式计算和量子计算机的出现,也必将决定性的改变计算资源供给端的情况:
分布式集群
分布式集群可以调动不同的计算资源为同一个计算目标服务,可以实现一个计算目标可以调配无限计算资源并予以支持,解决大数据情境中运算量过大超出单台屋里机运算承受能力极限的问题,最终达成同物理计算资源协同调配的成效,也为后续的云计算奠定了基础。
分布式算法执行
借助分布式集群、Hadoop生态进行算法执行,使用者创造工具,那么工具肯定也会反过来影响使用者,而分布式式算法可以解决多个步骤:
虚拟化与云计算
云计算是指在虚拟化技术的基础之上,根据实际计算需求定制化的输出计算资源从而获取计算资源,打通了计算资源供给和需求的两端,可以不用在本地配给计算资源,直接通过互联网给计算中心发送计算请求,计算中心在根据计算要求分配计算资源并执行运算,最终将计算结果返回给用户。
云计算,给万物赋能
通过云计算,只要能联网、有消息发送终端和接收终端,就能随时随地申请计算资源执行计算,终端不再需要拥有复杂运算能力,也能够执行复杂运算,进一步执行复杂决策,云计算能够给万物赋能,赋予万物执行计算的能力。
当然,云计算所代表的赋予万物计算能力中心化的管理,也客观上促进了数据统一存储,同时也推动了物联网的兴起。
数据的价值 数据生产1.0
IT行业每隔15-20年就会迎来一轮重大的技术革新,在1980年前后,第一次信息化浪潮也就是个人计算机的普及到1995年前后,第二次信息化浪潮也就是互联网化的浪潮。伴随着这两次信息化浪潮的出现,数据的诞生方式产生了重大的变化,从原先的可以搜集的小样本抽样转变为后来的自动生成无穷无尽的数据。
数据产生2.0
90年代末,互联网技术兴起,主要的作用是信息的传播和分享,到2004年Facebook和Twitter相继问世,互联网成为了人们实时互动、交流协同的载体,全世界的网民都开始变成了数据的生产者,在到2012年乔治大学的教授李塔鲁考察了Twitter上产生的数据量,他作出估算说,过去50年,《纽约时报》总共产生了30亿个单词,现在仅一天,Twitter上就产生80亿个单词的信息量。
数据产生3.0
现在我们通过智能手机+智能穿戴+感知传感器,这极大程度上拓展了数据采集渠道,我们利用智能手机与其他组织或个人发生实时互动,行为数据也被实时记录,智能穿戴和传感器无时无刻,不在自动采集数据,在可以预见的未来,以人为核心的一切事物运行和状态都将被数据所记录。
数据与石油
数据的价值,在于数据结论的产出,也就是如何使用数据,就如同埋在地底下的石油,需要开采和冶炼,才能够真正挖掘其价值。所以在大数据时代,数据是基础,而算法是核心。
算法核心
算法核心用途是挖掘事物运行内在逻辑和规律,如果说数据是石油,计算能力是开采石油的工具,那么算法,则是石油冶炼技术,将算法作用于数据,产出有价值结论的过程,实际上就是挖掘数据价值的过程。
数理统计与机器学习
目前来说以神经网络为代表的机器学习类算法,正掀起一场针对统计学算法的革命。
学习型算法
阿里集团学术委员会主席、湖畔大学教育长:曾鸣提出的看法是:所谓学习是通过概率论的方法,不断地去通过正反馈来优化结果,而不是像人一样去思考学习。这种机器学习的方法必须基于海量数据的校验,必须基于算法的一个不断反馈调整的过程。
医保反欺诈案例
随着社会老龄化程度加深,我国各地医保压力持续增加,部分地区已经面临穿底风险。并且医保欺诈面临着以下的问题:
在此背景下,利用大数据的方法,对医保骗保行为进行智能识别,在骗保行为发生的第一时间进行识别与制止,则能够起到较好的反欺诈效果。
首先,我们抽象定义时间和时间,以及它们的属性。

接着,将就医路径抽象成有时序关系的事务集。
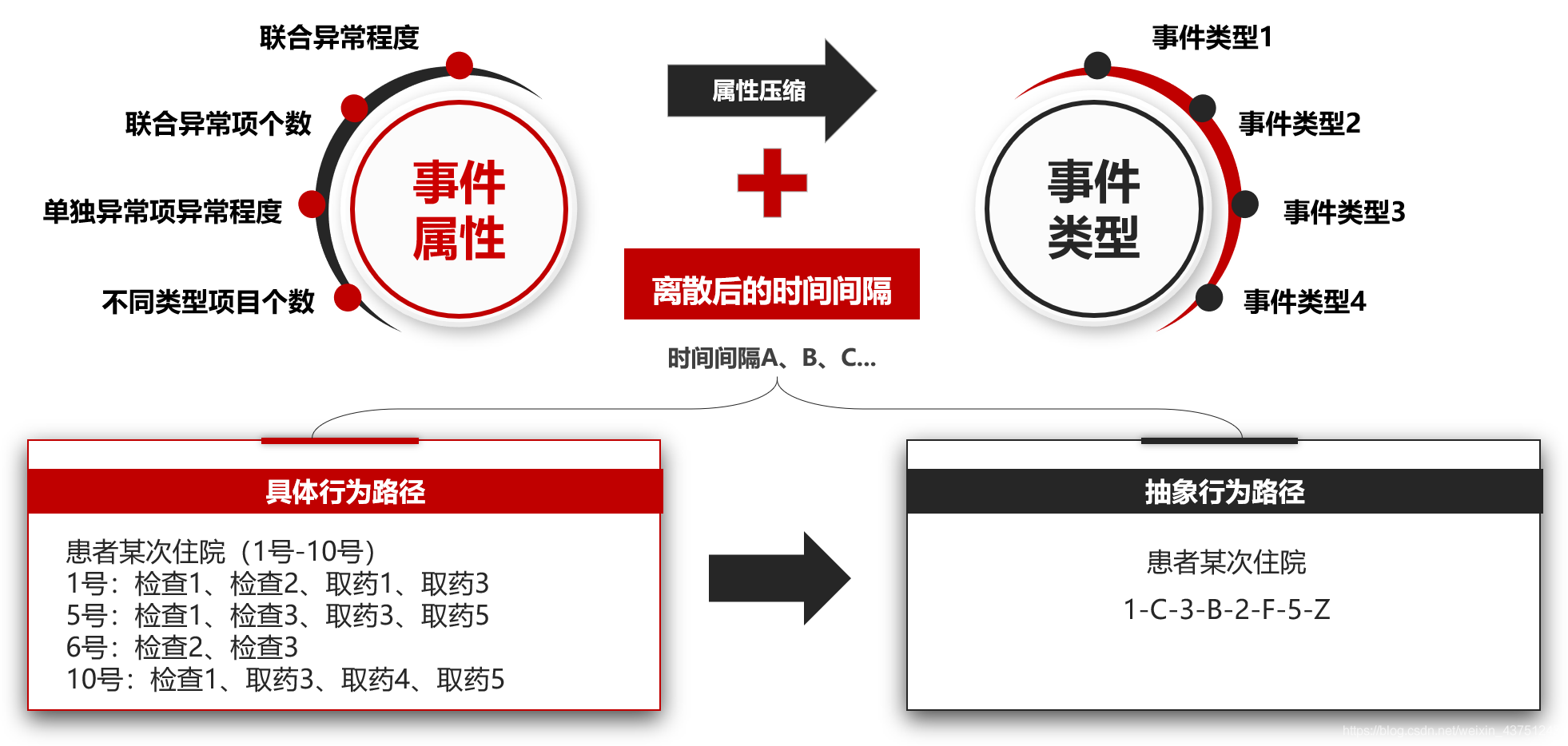
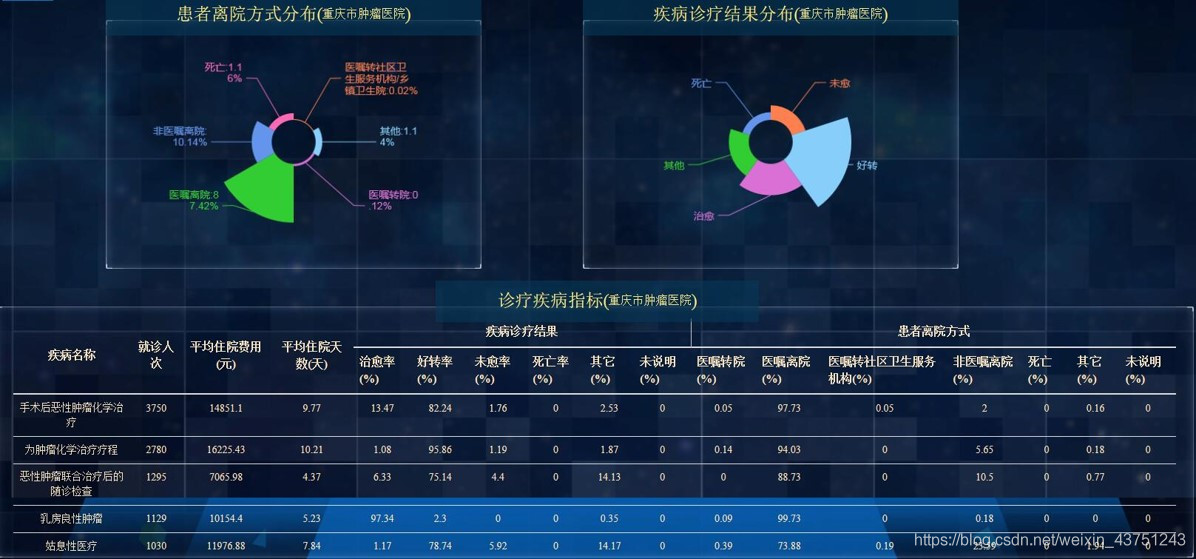
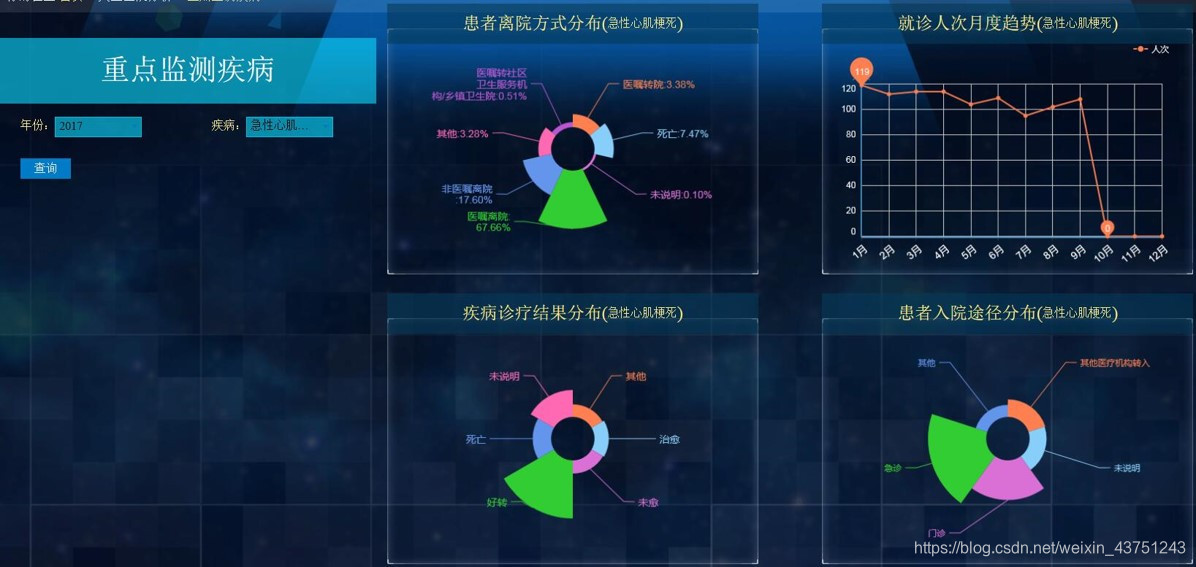
然后查看各类的相关指标
实际案例
CDA就曾与重庆卫计委展开合作,就一些病情对患病人群进行调查分析,并且可以针对某些具体的病症进行观察,成功的帮助卫计委对患病人群进行管理预测。
推动数据科学进步的三驾马车
随着科技不断的进步,数据科学也在不断的进步,而主要推动数据科学进步的有三部分:
这三部分是相辅相成、相互促进,并且缺一不可的,只用继续的发展这三部分,数据科学才能在发展的道路上,拥有源源不断的动力。
人工智能
根据2018年1月18号颁发的中国《人工智能标准化白皮书》定义,我们可以将人工智能视为数据科学皇冠上的明珠,目前的主流研究仍然集中于弱人工智能,并取得了显著进步如语音识别、图像处理和物体分割、机器翻译等方面取得了重大突破,甚至可以接近或超越人类水平。但是弱人工智能并不能成为真正实现推理和解决问题的智能机器,这些机器表面看像是智能的,但是并不真正拥有智能,也不会有自主意识。
2018年1月国家标准化管理委员会颁布的《人工智能标准化白皮书》对人工智能学科的基本思想和内容作出了解释:
而人工智能随着这么多年的发展,可以将其发展历程分为三代
第一代人工智能
第一代人工智能是基于规则的“智能”,典型代表:IBM深蓝(Deep Blue)

1997年5月11日美国IBM公司研制的并行计算机“深蓝”击败了雄踞世界棋王宝座12年之久的卡斯帕罗夫。但是国际象棋每一步的选择以及应对对手某一特殊步骤的最有方案是确定的,只要足够多的定性棋谱以及足够大的计算速度,就能够在对手走任何一步的时候准确判断出下一步应该如何走,就本质上而言,1997年的深蓝是基于规则的人工智能,深蓝本身并不会创造新的战略战术。
第二代人工智能
第二代人工智能是能够自主学习的人工智能,典型代表:谷歌的AlphaGo

2016年3月9日到15日,阿尔法围棋程序挑战世界围棋冠军李世石的围棋人机大战五番棋在韩国首尔举行。比赛采用中国围棋规则,最终阿尔法围棋以4比1的总比分取得了胜利。

2017年5月23日到27日,在中国乌镇围棋峰会上,阿尔法围棋以3比0的总比分战胜排名世界第一的世界围棋冠军柯洁。在这次围棋峰会期间的2017年5月26日,阿尔法围棋还战胜了由陈耀烨、唐韦星、周睿羊、时越、芈昱廷五位世界冠军组成的围棋团队。
第三代人工智能
假如数据变为无限,那么世界将会变成什么样子,目前第三代人工智能的代表是百战百胜的AlphaGo Zero
2017年10月19日,谷歌DeepMind团队在Nature发表论文,以《Mastering without human knowledge》为名,详细介绍了没有再用人类历史棋局作为训练样本,训练过程从随机开始,通过左右互搏精进棋艺,最终以100:0战胜了AlphaGo的AlphaGo Zero。
但是以上的这些人工智能,都是在信息透明,规则透明,结构明确,且为围棋规则和判断棋局的输赢本身也是一种监督信号,总的来说尚未脱离人类控制