介绍大数据平台建设经验的文章已经不在少数,再次发表该类文章是因为我们觉得:条条大路通罗马,形形色色景不同。本文主要介绍了神州优车大数据平台(只介绍离线平台并且侧重于基础架构部分)的一些建设经验,希望能给同仁们带来一些帮助。文章将从4个方面展开介绍,分别是建设目标、总体架构、深入讲解和总结规划,介绍过程中将直抒其意,不会对行业术语和专有名词进行解释,如有疑问可自行百科。
建设目标
2018年之前我司的数据平台依次经历了基于SqlServer的传统数仓阶段、基于Hadoop的探索应用阶段和基于Hadoop的全面应用阶段,不同阶段解决了不同的问题,完成了不同的历史使命。站在新的起点,为了满足企业数字化转型的和精细化运营的需要,平台建设进入了一个新的阶段,一句话概括建设目标:打造全新平台,提升数据赋能水平,支持业务快速发展。主要建设目标如下:
提供一站式Portal
打通各个子系统,对功能进行整合和集成,保证用户只需登录一个平台,便可完成任务开发(现状是数据交换平台、元数据平台和任务调度平台等都是独立的子系统,用户需要跨平台进行操作)实现OneClick
用户发起新的开发任务,一般需要新建HIVE表、跑全量数据、合并全量数据到HIVE表,配置增量同步、配置定时ETL任务、配置数据质量校验等一系列操作,由于各子系统还未完全打通,这些操作都是半自动化的,系统打通之后,实现一键式快速开发支持用户DIY
诸如数据权限的管控、自定义函数的管控、自定义插件的管理、文件的上传和下载等功能,依托新的平台服务策略,支持团队和个人自我管理,降低平台服务方的运维压力提升小文件治理能力
MR任务或SPARK任务的分区设置如果不合理,会导致任务输出巨量的小文件,如不加以合理控制,不仅影响查询性能,还会给NameNode(或Impala Catalog Server)造成巨大压力,影响集群稳定性。随着平台承担了越来越多的业务需求,需要对小文件进行更合理的控制和优化提升过期文件治理能力
数仓中的很多表、用户自己目录空间下的文件、大量日志文件和临时文件、数据同步的原始文件等,可能已经过期没用了,但仍然占据了大量磁盘空间。所以,需要对冷文件和僵尸文件进行更深层次的管控对数据任务的资源配置进行治理
一个数据任务应该分配多大的资源,需要更加精细化的控制,分小了影响性能,分大了浪费资源,CPU和内存的配比也很重要,为了实现更科学的资源分配,需要基于数据分析,提升资源分配的合理性NameNode宕机
HDFS本身还是很稳定的,像我们的HBase集群,很少因为HDFS出问题而导致系统故障,但HDFS最怕的就是小文件,文件数过多将给NameNode带来巨大压力。有段时间我们的NameNode经常宕机,定位到是文件数量过载导致的之后,一方面调大了NameNode进程的内存,另一方面想办法控制文件数量,随后系统稳定运行了相当长的时间。但突然有一天NameNode又宕了,反复试了几次,把内存调到很大,才勉强启动起来,启动起来之后发现文件数量在一天之内暴增了近一倍,随后系统长时间处于blockmissing状态无法恢复。最后定位到的原因是一个非常大的数据任务执行失败了,但是产生了巨量的.hiveStaging文件没有释放,造成文件数暴增,压垮了NameNode;而重启后一直处于blockmissing状态无法解除是因为,文件数暴增导致DataNode负责的block块儿也增多了,DataNode在向NameNode汇报块儿信息的时候,传输的数据量太大,超过了参数ipc.maximum.data.length的限制,汇报不上去。针对这个问题,如果有“文件数量异动报警”功能,便可以及早发现问题,从而避免事故的发生。关于.hiveStaging和blockmissing的问题,可参见如下两个链接:
参考一:cnblogs.com/ucarinc/p/11831280.html
参考二:cnblogs.com/ucarinc/p/11831353.html调度任务延迟
任务一旦出现延迟,早晨报表就出不来,随之而来的是大量投诉,顿时感觉亚历山大。导致任务延迟的原因非常多,最直接的就是hadoop集群出问题,另外就是调度引擎和执行引擎自身的问题,再有就是调度任务的时间安排的不合理等。举几个印象深刻的任务延迟场景,如下:HiveServer卡住导致所有MR任务延迟
cloud.tencent.com/developer/article/1149029HiveServer内存溢出导致所有MR任务延迟MetaStore内存溢出导致所有任务延迟Yarn资源预留机制触发了Yarn死锁,导致任务延迟,参考资料如下
blog.csdn.net/zhanyuanlin/article/details/78799341超长的大任务占据大量资源,影响调度任务队列设置的maxRunningApps参数过小
如上所列的这些问题,已经有保障体系(如:长任务超时报警,jvm内存报警、GC报警等)可以进行预警,但需要在广度和深度上做更多的整合和细化
数据质量问题
出现过由于幂等控制不合理,导致调度任务重复提交,引发表数据重复的问题;出现过由于主子表外键类型不统一(一个String,一个BigInteger),导致关联查询数据重复,引发表数据重复问题;出现过由于并发控制不合理,导致同一任务并行执行,引发表数据丢失的问题;出现过由于hadoop写入机制不健全(参见:issues.apache.org/jira/browse/HDFS-11915 ),导致spark-sql无法完整读取block块儿数据,引发表数据丢失和截断的问题。 总体架构全局视图

局部视图
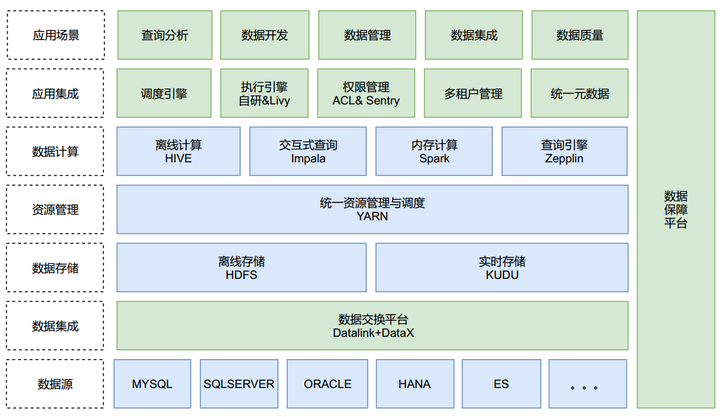
深入讲解数据交换平台
神州优车数据交换平台,能够支持多种异构数据源之间的【实时增量同步】和【离线全量同步】,是一个能支撑多种业务场景的综合性平台,本文只介绍和大数据相关的功能板块,更多详细介绍可参考:mp.weixin.qq.com/s/BVuDbS-2Ra5pIJ7oV78FBA。概括来讲,数据交换平台在整个大数据平台的【数据处理Pipeline】中担任了【数据采集】和【数据回流】的重任,如下所示:
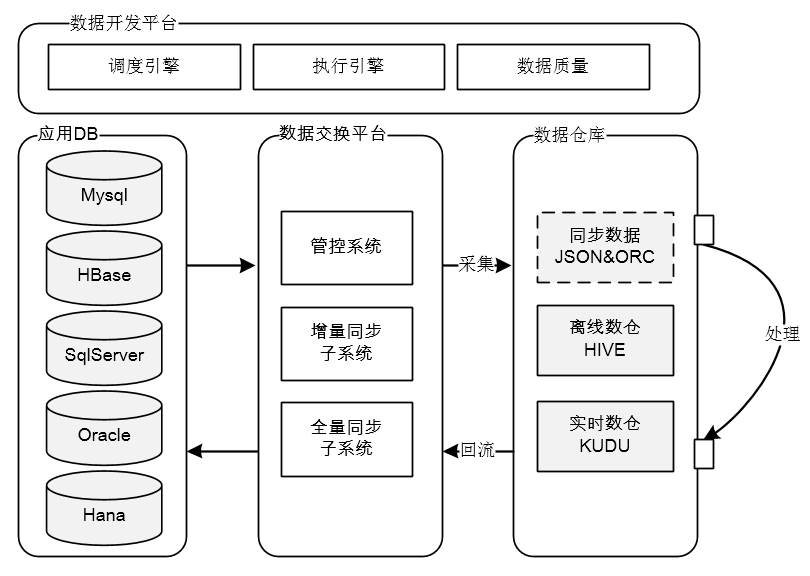
而专讲数据采集或回流略显单薄,所以接下来将围绕大数据平台的【数据处理Pipeline】展开介绍,Pipeline分为3个部分,分别是数据采集、数据处理和数据回流:
数据采集
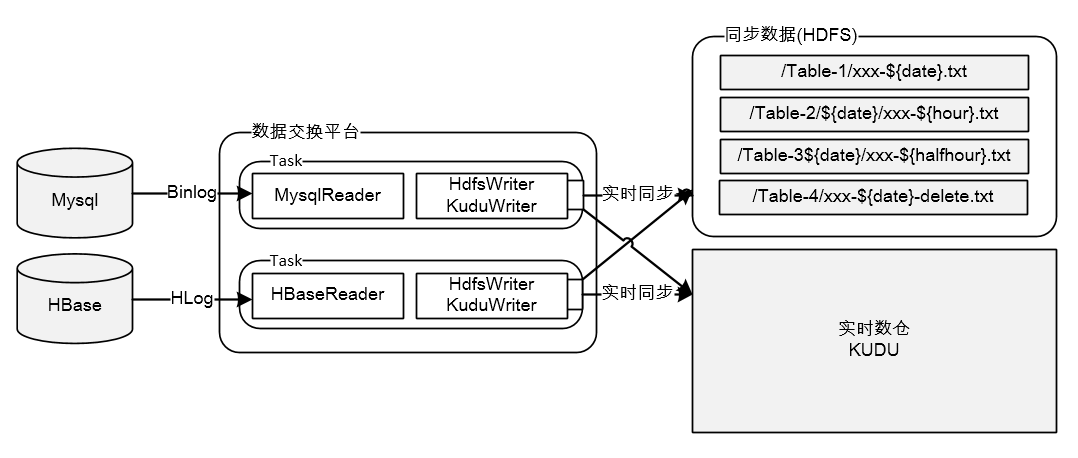
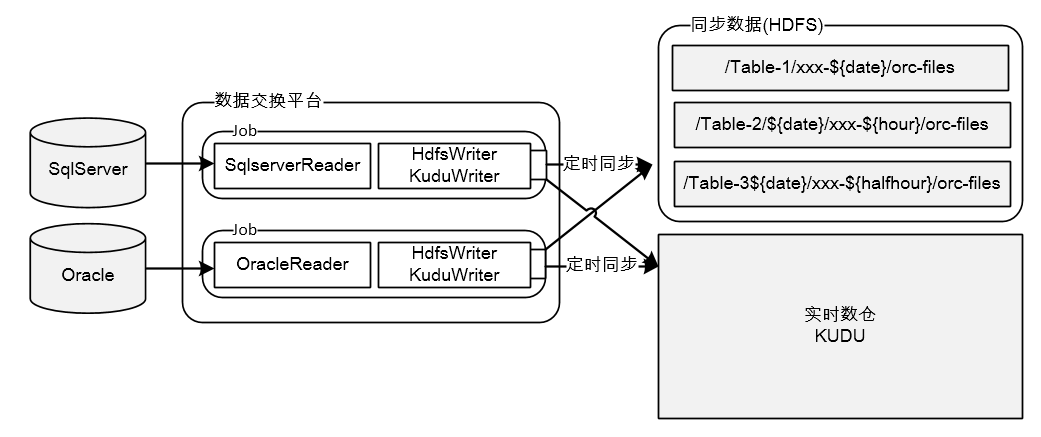
如上图所示,数据采集是把业务系统数据通过数据交换平台流转给大数据平台的过程,采集方式分为两大类:一类是依靠DB的Replication机制,通过抓取DB的日志获取数据,如:Mysql的Binlog,Hbase的Hlog;另一类是受限于DB的日志机制不够强大,只能直接从DB抽数,如:SqlServer、Oracle、Hana。下面对两种方式展开说明:
数据处理
此处说的数据处理主要指的是离线数仓的数据处理流程(实时数仓比较简单,没有load的过程),处理过程由两部分组成,分别是【数据加载】和【数据转换】,前者负责把同步数据Load到ODS库中,后者负责依照数仓模型对数据进行Transform。数据采集、数据加载和数据转换,是一个ELT的过程,如下图所示,关于ETL和ELT的对比介绍,可参考:mp.weixin.qq.com/s/osCRnfnuCFGJIR1jkhgUwA
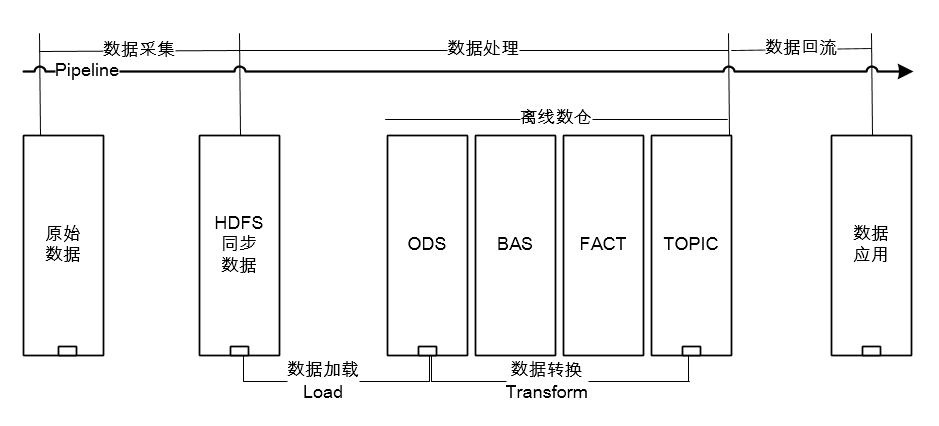
数据回流
数据回流可以看做数据采集的逆向过程,但远没有数据采集的流程复杂,其核心功能就是表间的数据同步,目前支持两种形式的回流,分别是:【数据交换平台任务回流】和【SparkSql回流】,两种方式各有优缺点,将在后面的【数据开发平台】章节详解
数据保障平台
数据保障平台(内部代号SpaceX),是一个集成了监控、运维和资源治理的平台,用于对大数据平台的基础设施进行稳定性保障,目前在监控和资源治理方面已经有了一定的成果,在自动化运维或者智能运维方面还有很长的路要走。接下来分3部分对平台进行介绍,分别是平台整体架构、HDFS监控治理和YARN监控治理
平台整体架构
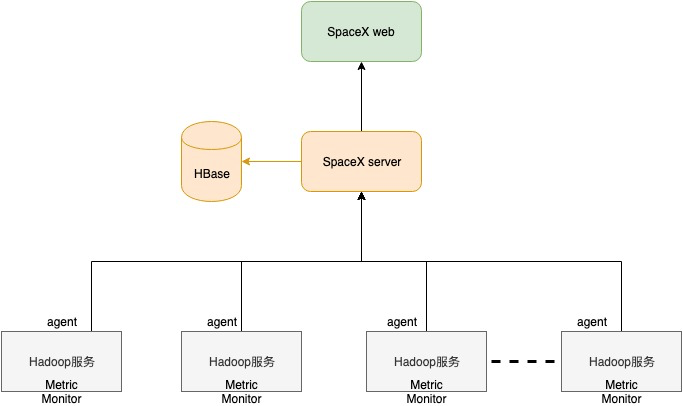
上面是SpaceX的部署架构图,其架构深入参考了Ambari的设计,主要由4部分组成:
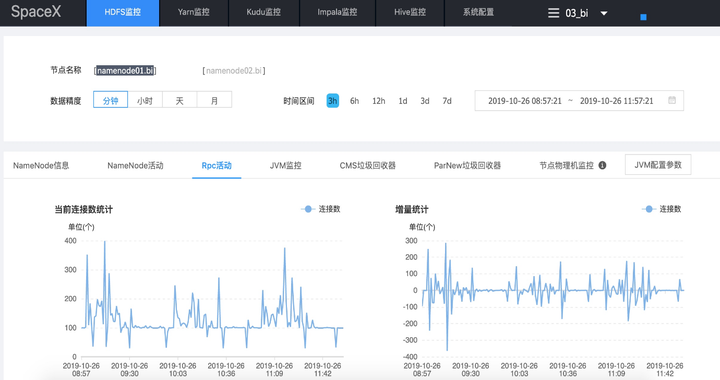
上图是系统Portal的一个概览图,目前支持对HDFS、Yarn、Kudu、Impala和Hive的监控和管理,系统支持多集群模式,即:可以对多套集群同时管理,并可快速增加对新集群的监控,如SpaceX同时管理了实时计算集群、离线计算集群、Hbase集群、OpenTsDB集群的HDFS文件系统
HDFS监控治理
对于HDFS的监控治理,分为3个层级:第一个层级是基本的可用性监控,第二个层级是集群各项Metrics的监控,第三个层级是对文件的深度分析和治理。
第三个层级
集群目前有多少大文件,有多少中文件,有多少小文件,有多少空文件,有多少冷(旧)文件,它们的比例如何,它们在文件目录中是怎么分布的,它们归属于哪个团队等等,这些问题靠第三层级的监控治理给出答案,先列出一组图,如下:

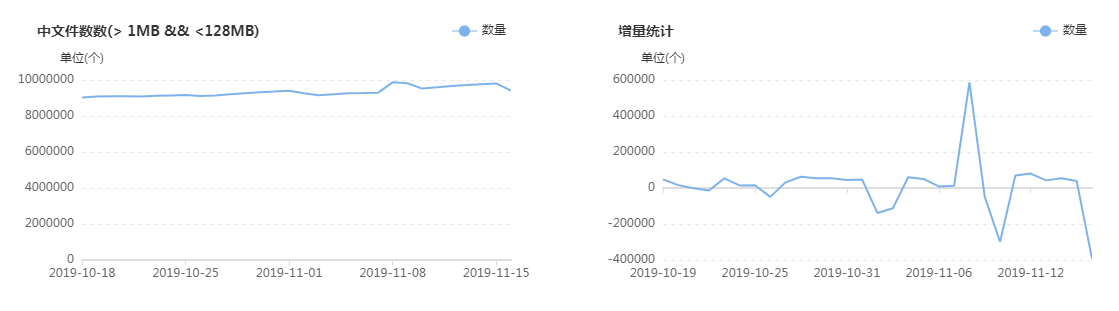
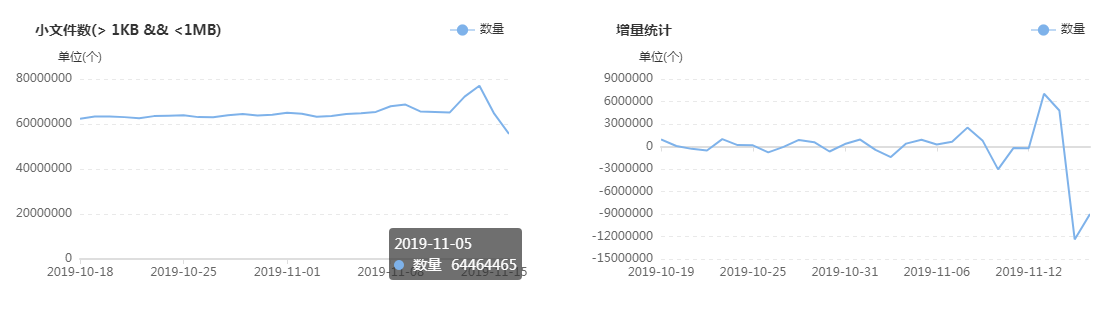
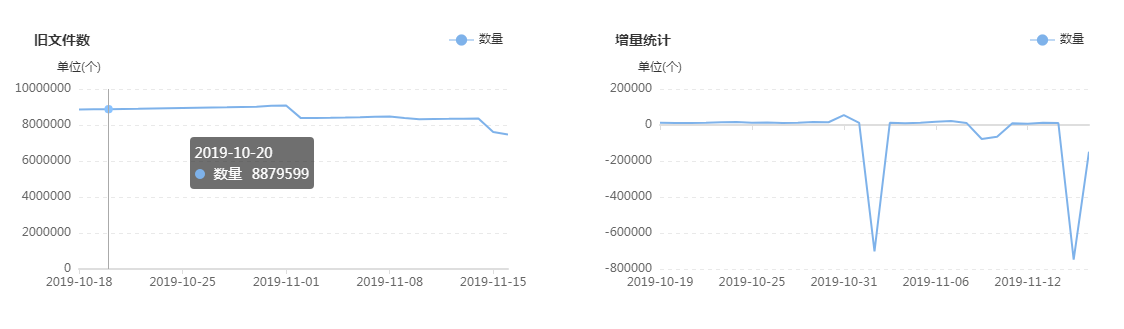
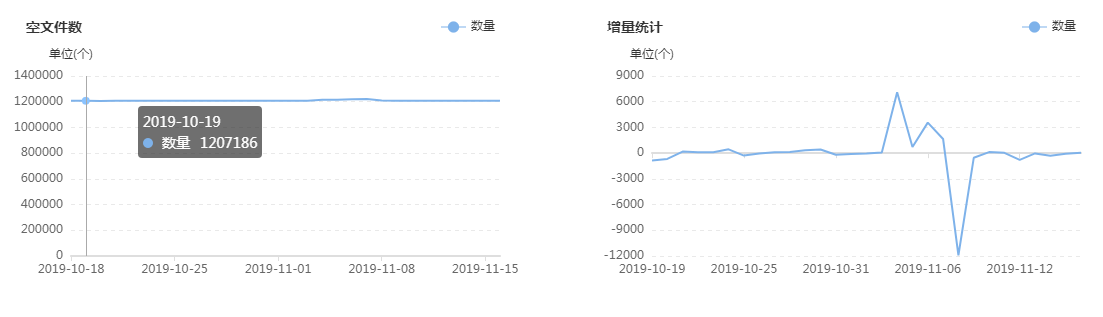
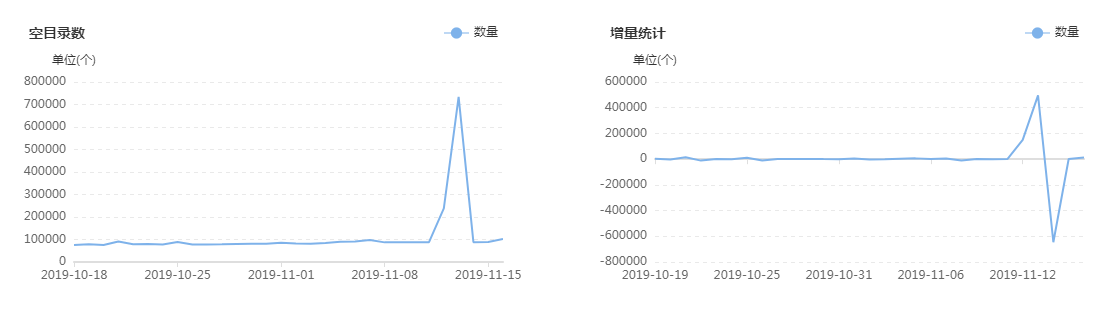
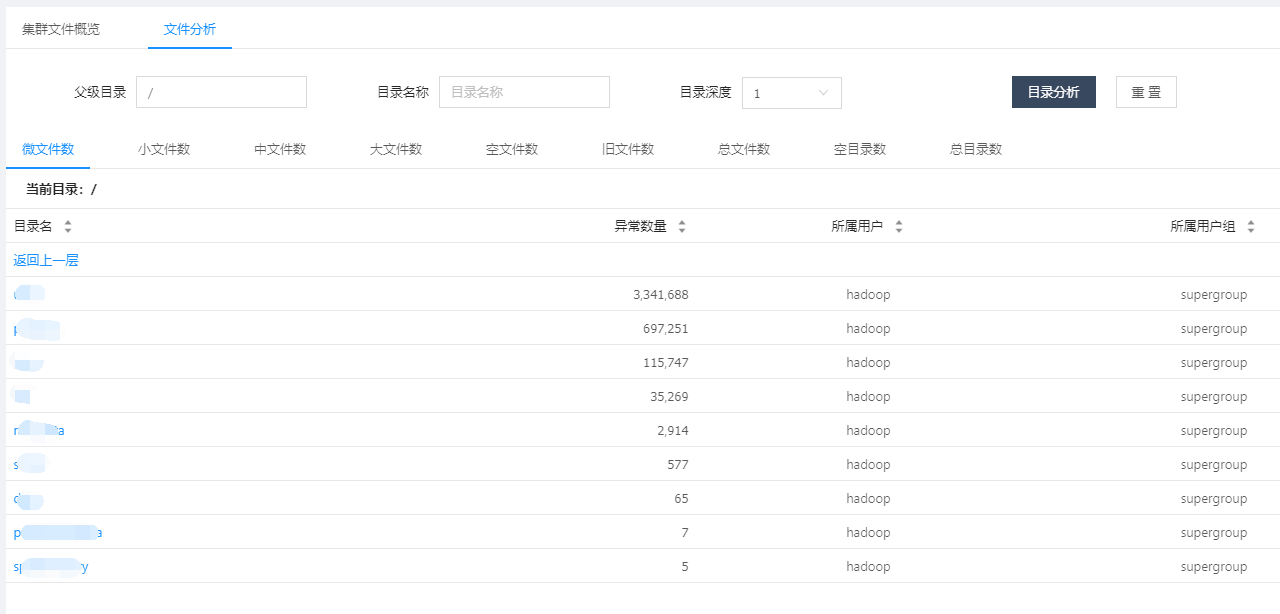
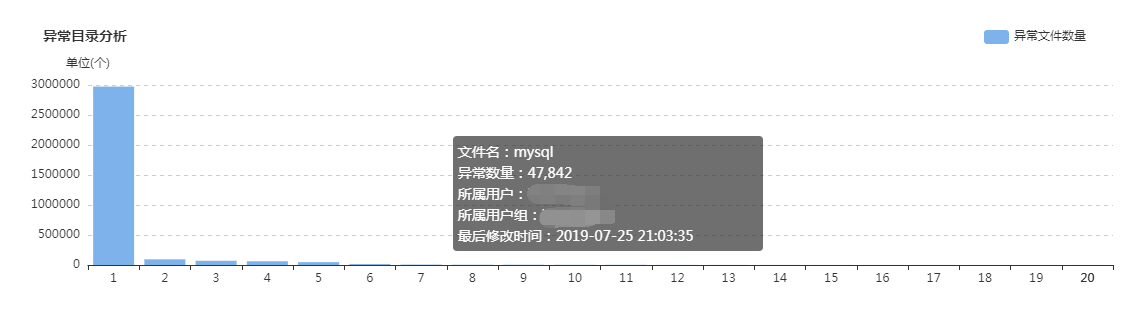
上面这组图是SpaceX中涉及文件分析功能的一些核心页面,总的来说分为两类:一类是对各种类别的文件进行分析,监控其数量变化的轨迹和趋势,以及不同文件的数量比例;另一类是提供交互式页面,允许用户精确分析指定的目录,当输入目录并点击分析之后,系统会列出不同类型文件的分析结果,如:每个子目录下存在的异常文件个数,按存在的异常文件个数列出Top10的异常子目录,展示Top500的异常文件列表等;除此之外,系统还会根据后台的分析数据,定期输出报表发给各开发团队,各开发团队根据报表的指导进行对应的优化,如:把历史分区中的小文件合并为大文件、把旧文件进行压缩归档、调整任务参数以降低输出的文件数量等等。
在建设背景章节提到过资源铺张浪费的问题,其中涉及文件相关问题的解决主要依托的就是该文件分析功能,而该功能得以实现的首要功臣是PayPal开源的NNAnalytics,一款基于HDFS-FSImage的文件分析引擎(github.com/paypal/NNAnalytics),我们在其基础上进行了二次封装和改造,结合自身场景进行了应用落地。目前,集群的总文件数已经从接近1亿优化到了5000W以内,后续的目标是降到3000W以下,随着优化的不断进行,集群性能随之不断提升,举例如下:
YARN监控治理
和HDFS的监控治理类似,YARN的监控治理也分为3个层级:第一个层级是基本的可用性监控,第二个层级是集群各项Metrics的监控,第三个层级是对任务资源(CPU&MEMORY)的深度分析和治理,下面展开介绍:
其它模块目前还没有非常深入的研发,此处就暂不介绍了,这个产品也是刚刚完成基本版的建设,以后要走的路还很长,更高效的自动化运维、更深层次的监控分析、更便捷的易用性等都还需要不断迭代
数据开发平台
数据开发平台(内部代号:DSpider)是整个大数据架构中最核心的一个版块,起着承上启下的作用,对下,将底层的技术框架进行集成和封装,转化为不同的功能引擎,对上,为用户提供方便易用的功能,屏蔽技术细节。本章节将对数据开发平台展开详细的介绍
架构介绍
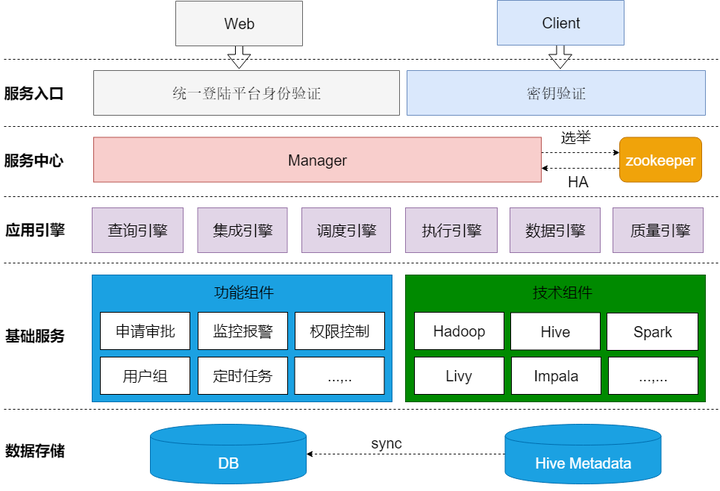
上图展示的是DSpider的应用架构,分为5个层次,分别是数据存储、基础服务、应用引擎、服务中心和服务入口,每个层次的介绍如下:
数据引擎
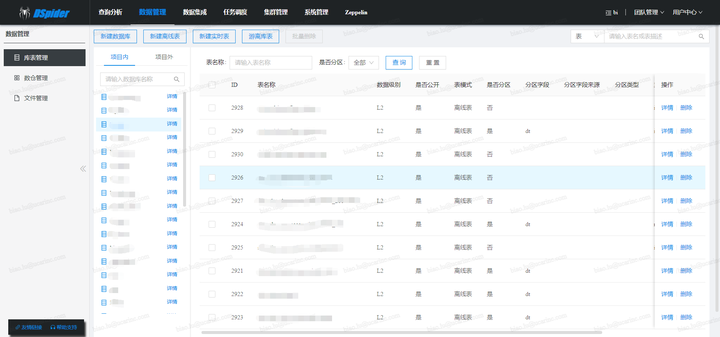
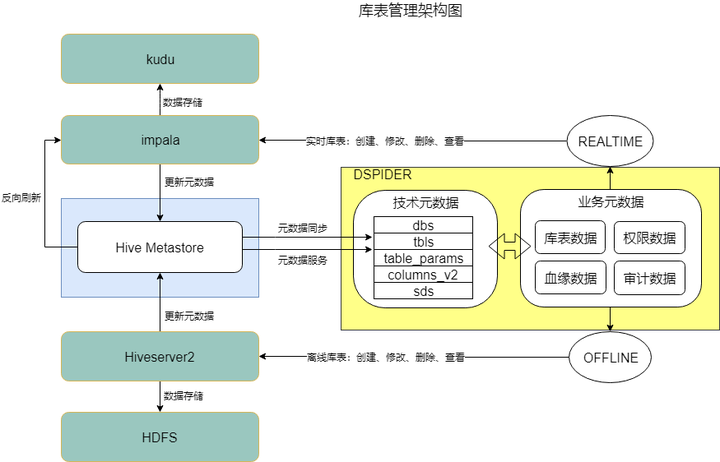
整个流程架构可以划分为三部分:
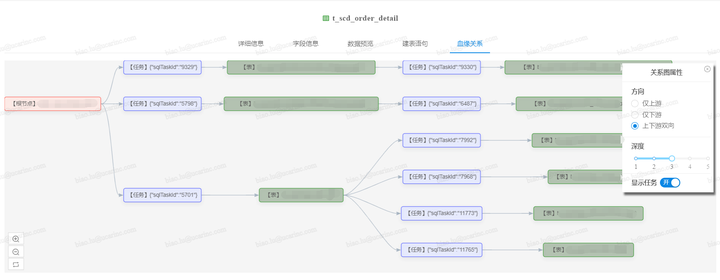
血缘关系(或者叫数据地图)是数据引擎另一个非常重要的模块,其能够立体化分析出数据从哪里来、到哪里去的依赖视图,DSpider的血缘关系不仅能展现大数据平台内表之间的上下游关系,还能把和外部系统的表间关系分析出来。
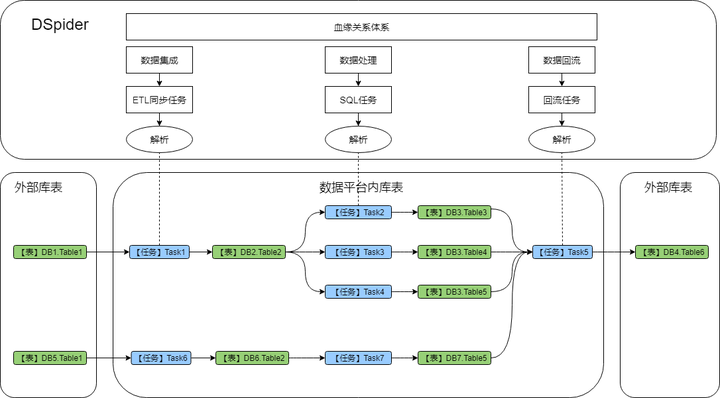
如上图所示,血缘分析工作贯通数据平台pipeline的所有环节,主要通过分析【ETL同步任务】、【SQL任务】和【数据回流任务】的配置信息来构建血缘依赖,不仅能展现表之间的直接依赖关系,还可以展示出是靠哪些任务构建出的依赖关系。
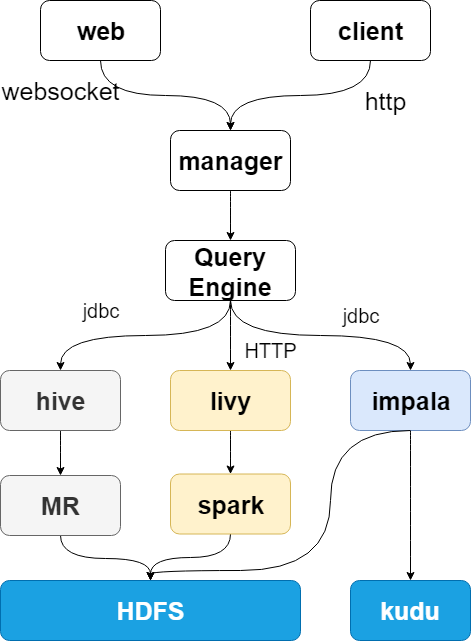
查询引擎
集成引擎
数据集成引擎,还提供了补数据的功能,当仓库表出现数据问题,需要修复的时候,用户可以发起修复申请,审批通过之后,系统会自动化进行处理调度引擎
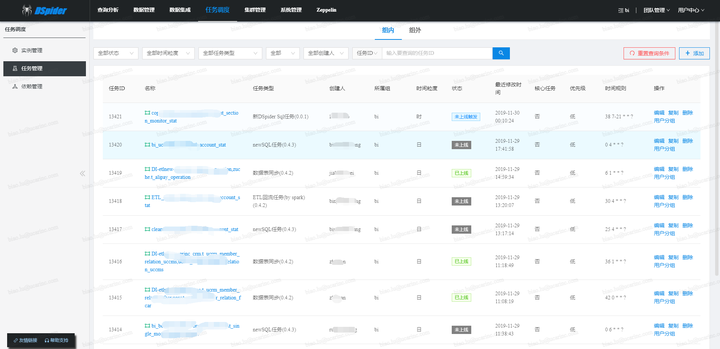
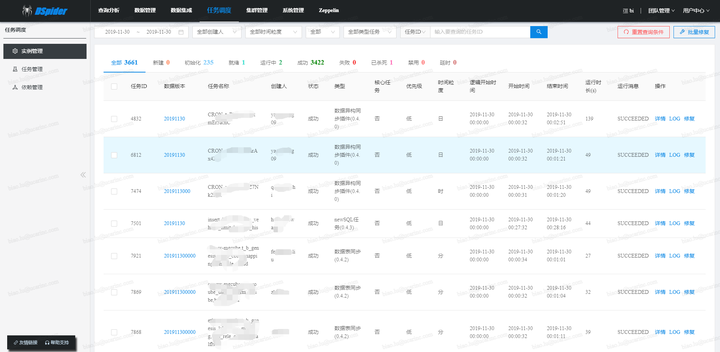
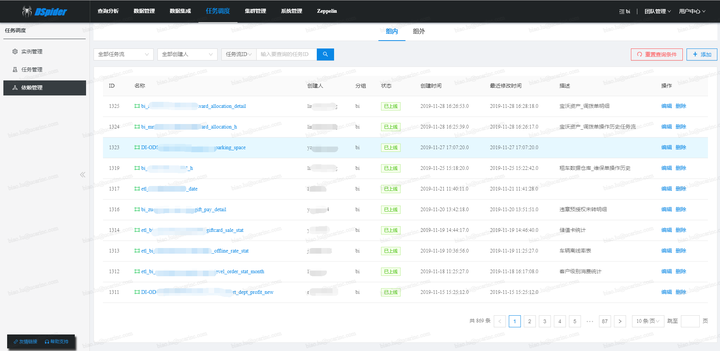
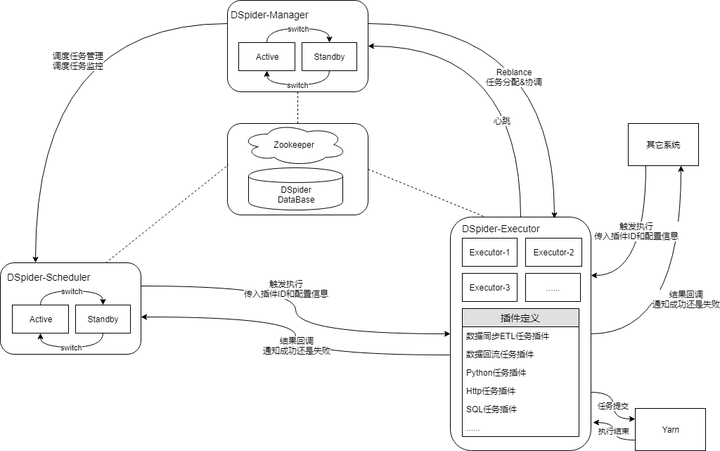
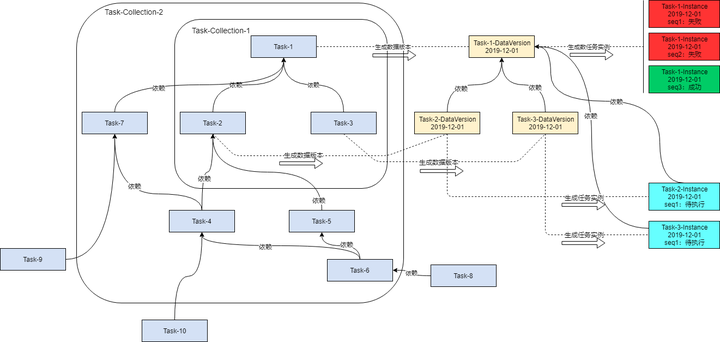
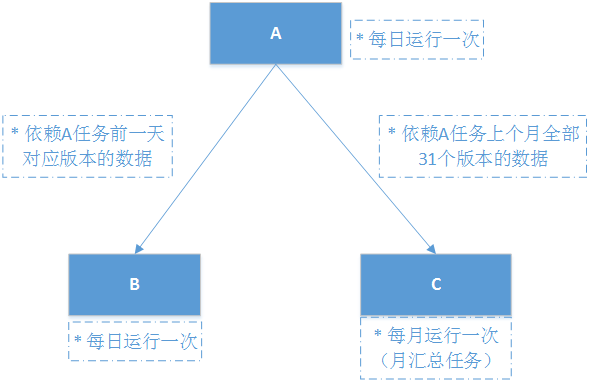
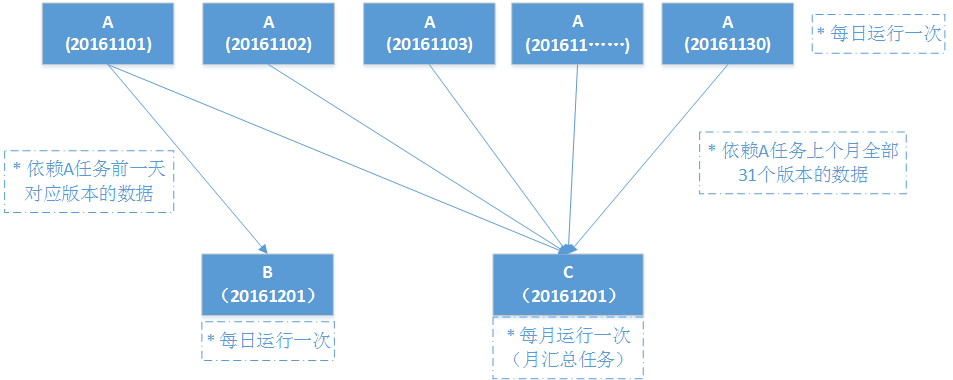
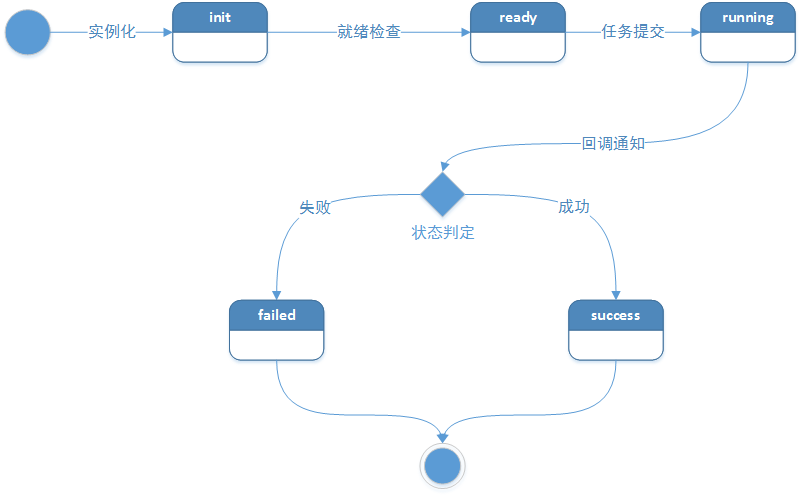
调度引擎的内核是仅仅围绕这个状态机进行设计的,内核整体采用SEDA的设计思想(进行了部分改良),将调度流程分成多个独立的Stage ,每个Stage处理特定的Event,系统全局通过Event机制实现调度引擎运转,为了降低Stage间的耦合度,系统通过独立的Schedule Event Bus(SEB)实现Event在不同Stage间的传递。内核架构如下图所示:
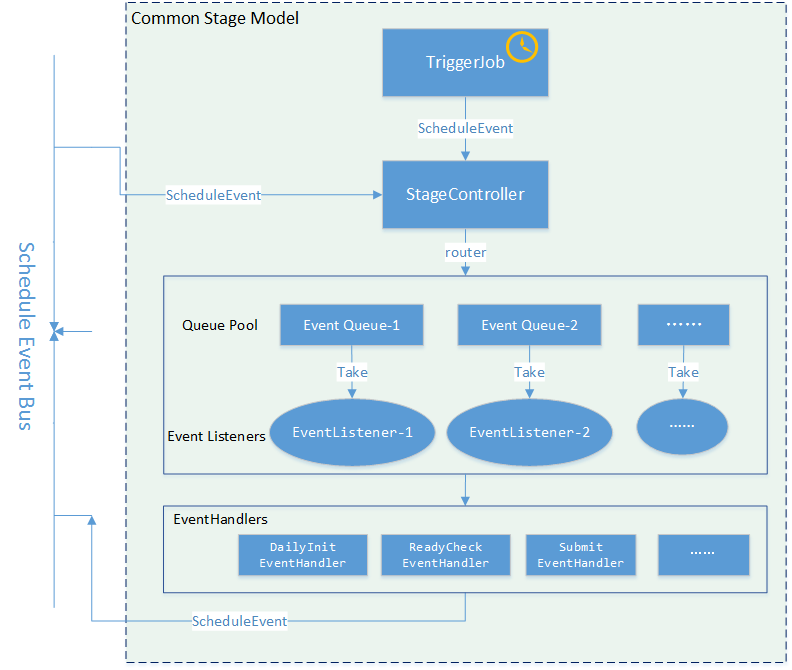
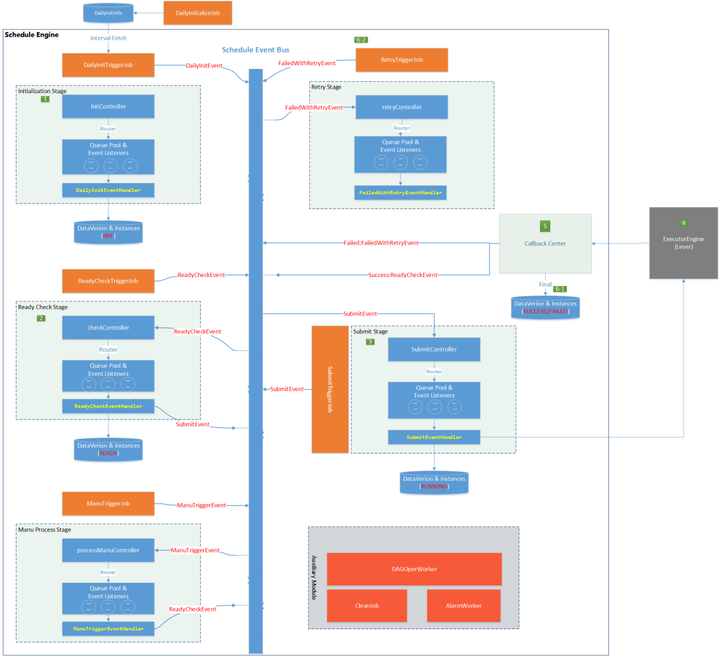
几个核心的Stage分别是:InitizlizationStage,接收DailyInitEvent,用于生成下一日的执行计划,生成后的作业实例状态为init;ReadyCheckStage,接收ReadyCheckEvent,用于把满足条件的作业实例状态置为ready;SubmitStage,接收SubmitEvent,用于把满足条件的作业实例状态置为running,并提交作业到执行引擎;RetryStage,接收FailedWithRetryEvent,用于把失败的作业实例状态置为failed,并触发重试;ManuProcessStage,用于接收ManuTriggerEvent,执行用户手动触发的任务实例。
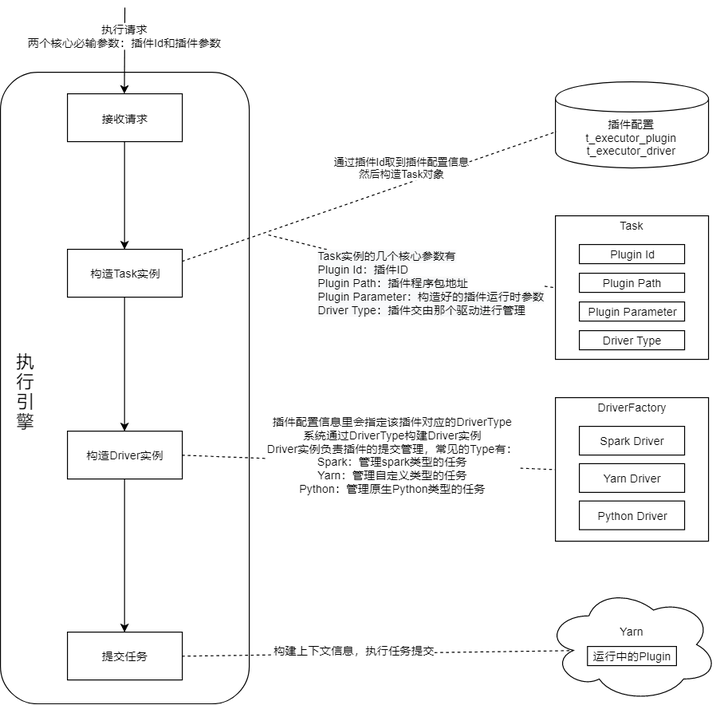
执行引擎
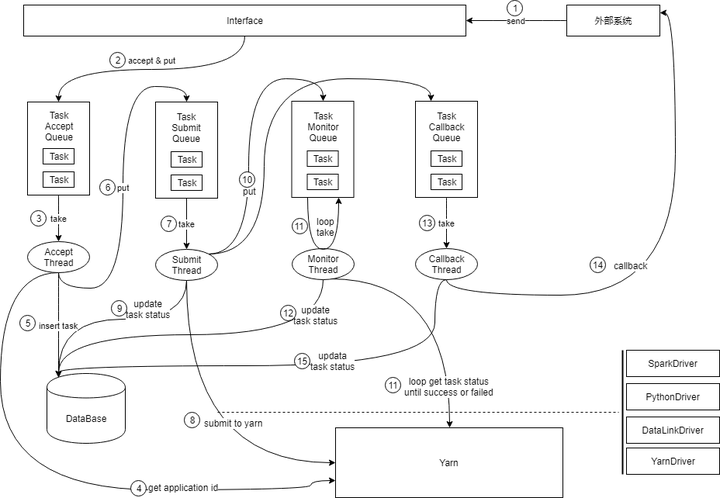
外部系统根据负载均衡策略(一般是轮询)发送执行请求到某个ExecutorExecutor接收请求,并将请求封装为Task放入Accept QueueAccept工作线程从AcceptQueue取出TaskAccept工作线程访问Yarn,获取一个ApplicationIdAccept工作线程将ApplicationId赋给Task,并将Task信息插入数据库,此时Task的状态为INITAccept工作线程将Task放入Submit Queue,并返回响应给外部系统Submit工作线程将Task从Submit Queue取出Submit工作线程对Task进行解析,找到对应的Driver,用4步取到的ApplicationId进行任务提交Submit工作线程将Task的状态变为RUNNING,并更新数据库Submit工作线程将Task放入Monitor Queue和CallbackQueueMonitor工作线程循环检测Monitor Queue中的Task是否执行完毕,将完毕的Task移出队列对执行完毕的Task进行状态变更,并更新数据库,状态可以是SUCCEED、FAILED和KILLEDCallback工作线程将执行完毕的Task从Callback Queue中取出调用外部系统回调接口通知Task执行结果
补充说明:1) 上图展示的是正向的核心流程,对一些异常情况的处理并没有体现出来;2) 第4步获取的ApplicationId非常重要,是系统进行幂等判断的主要依据,场景举例:第8步中Task提交到Yarn之后,Executor发生了宕机,然后触发了集群的Rebalance,随后Task被其它Executor接管,因为宕机前第9步未来得及执行,所以Task的状态还是INIT,被新的Executor接管后会被放到SubmitQueue,第8步会被新的Executor重复执行,但Yarn能识别这是重复提交,会予以忽略。
Rebalance的机制和流程如下图所示:
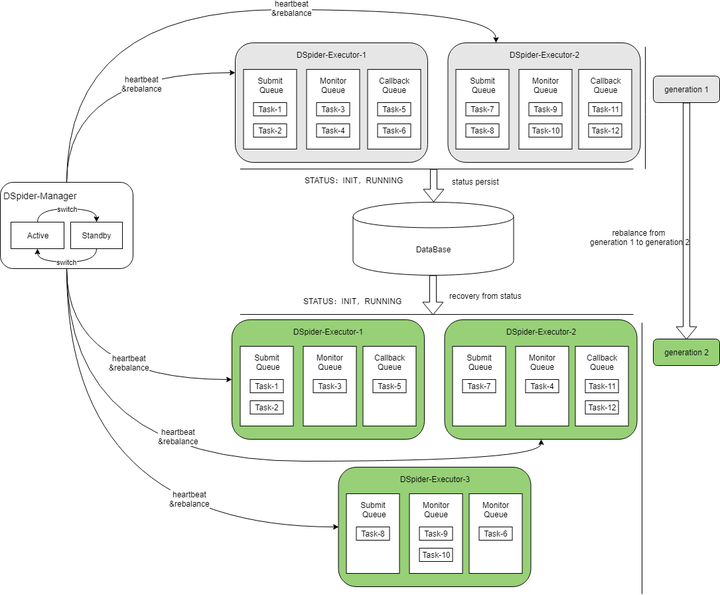
执行引擎内置了一部分通用的插件供用户使用,并提供了可扩展的插件模型,方便用户自定义,自定义插件的上架流程也很简单:第一步开发插件,第二步注册插件,第三步上传插件,第四步使用插件。系统内置的核心通用插件简介如下:
数据采集插件 (与数据交换平台打通,将业务数据同步到hdfs)表同步ETL插件(将数据交换同步过来的数据文件进行去重和清洗,并合并到Hive表)Sql插件(支持用户通过写Sql语句(hivesql、sparksql、impalasql等),对Hive、Kudu表数据进行操作)Datalink回流插件(支持用户通过简单配置生成回流任务,比Spark回流插件更便捷)Spark回流插件(支持用户通过SpakrSql将Hive表数据回流到业务库,比Datalink回流插件更灵活)HTTP任务插件(根据用户传入的URL,发起http调用请求)等等质量引擎
数据质量的保证是所有一切数据分析和数据挖掘的基础,DSpider的质量引擎,提供了一套统一的流程来定义和检测数据集的质量并及时报告问题,其内核设计建立在Apache Griffin的基础上,并做了很多二次改造和封装,其功能模块主要分为三个部分:质量定义,数据度量和质量校验。总体架构图如下所示:
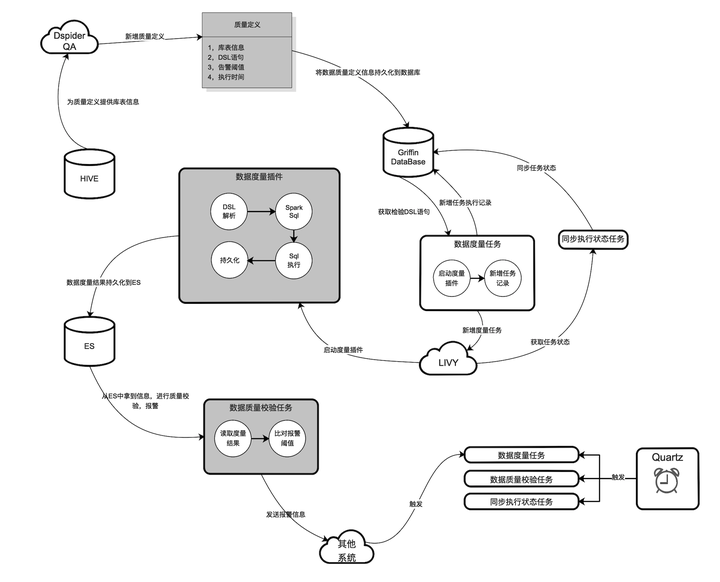
如下是新增质量定义的页面截图,供参考
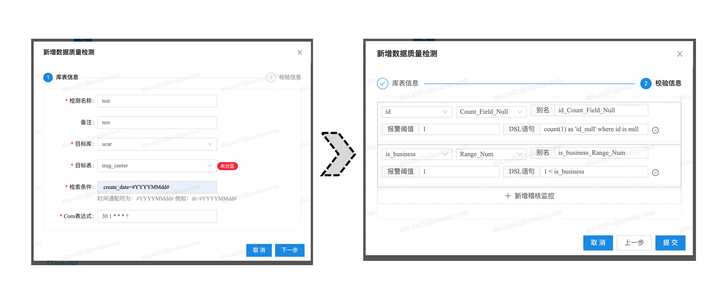
权限模型
权限有两类,功能权限和数据权限,此处所说的权限模型主要是指数据权限(以及和Group关联的功能权限,下文有述)。对于大数据平台来说,数据权限模型的设计,是一个很大的痛点问题,主要原因在于业界没有一套统一的权限标准,平台建设过程中集成的很多框架或产品,要么没有权限模块(如:Spark),要么比较薄弱,要么自成体系。另外,不同公司或团队对权限的要求也不尽相同,各家公司大数据平台的架构方案也不尽相同,这就导致权限模型很难复用,都需要建设者自行开拓出一套适合自己的体系。
虽然没有银弹,但业界还是有不少可参考的解决方案的,《大数据平台基础架构指南》一书的第7章做了很好的总结,里面列举了各种技术方案,并做了深入的优缺点分析,可参考学习。在参考了不少技术文章和博客后,我们的权限模型设计思路也逐渐清晰,一句话来总结:统一服务入口,通用权限模型,合理平衡折中。首先通过服务入口的统一,保证数据使用者无法绕过权限验证;然后通过标准化权限模型和体系,屏蔽不同的技术组件,提供统一的权限体验;最后通过不同场景的适配,控制权限的松紧程度。
接下来对权限模型展开介绍。DSpider是一个多租户的平台,不同团队的不同个体都可以使用平台提供的服务,同时平台管理的各种数据和资源也带有团队的属性,团队之间的数据访问也都需要进行权限控制。团队、个人、数据、资源,是DSpider权限模型的基本组成要素,如下图所示:
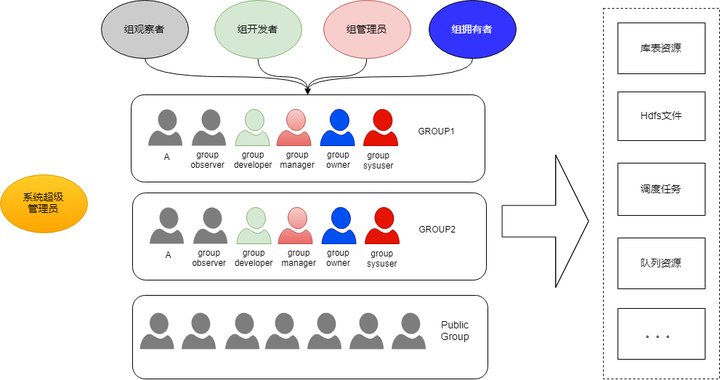
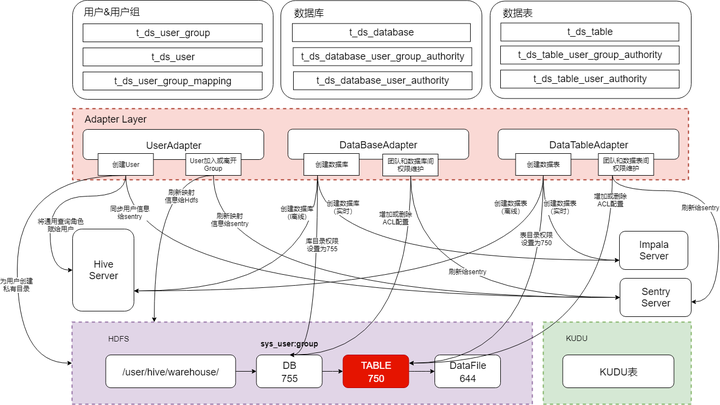
上面介绍的是权限体系的概念模型,概念模型如何映射为技术层面的物理模型,是比较有挑战的地方,下图展示的是DSpider权限模型的技术方案
blog.csdn.net/yu616568/article/details/54969729
cnblogs.com/tomato0906/articles/6057294.html
总结规划
平台经过一年多的建设,已经基本成熟,但还有很多细节需要慢慢去研磨,目前只能说刚刚脱贫,同小康和全面富裕的目标相比,还有很长的路要走。在开发效率和系统资源的优化上还有很大提升空间,把离线平台、实时平台以及机器学习平台进行打通也是一个重点规划,总之,一直在路上。
平台建设心得一:系统建设可以先污染后治理,但不要污染到无可救药,否则带来的将是巨大的填坑成本和痛苦的系统重构,应该做好总体规划、做好过程控制、做好快速迭代。不谋万世者,不足谋一时;不谋全局者,不足谋一域;言前定则不跲,事前定则不困,行前定则不疚,道前定则不穷。
平台建设心得二:引用别人的一句话,系统建设的难点不在于组装多少时髦组件,而在于对技术和产品本质的理解,以及对公司文化、业务特点、团队组成等一系列真实世界问题的认知、思考和权衡。
附录
附一些数据架构相关的资料链接,供学习参考
产品架构技术架构查询分析调度系统数据治理流式计算数据集成
