摘要
美团优选推出了客户从商户购买东西统一送到自提点,客户从自提点领取商品。 本文对美团优选中的商户进行聚类分析,首先对数据集进行数据探索分析与预处 理,包括数据缺失与异常处理、数据属性的规约、清洗和变换再对处理过的数据, 基于 LRFMC 模型进商户价值模型分类。最后针对不同价值类型的商户提供不同的 营销策略。将商户分为 5 类,分别是:特殊商户、优质商户、超优质商户、低价 值商户、发展商户。针对这 5 类商户给出相应的营销策略。
引言
美团优选是美团旗下的社区团购业务,采取“预购+自提”的模式,进入社区 团购赛道,进一步探索社区生鲜零售业态,满足差异化消费需求,推动生鲜零售 线上线下加速融合。“美团优选”是美团旗下的社区团购业务,采取“预购+自提”的模式,赋能社 区便利店,为社区家庭用户精选高性价比的蔬菜、水果、肉禽蛋、酒水零食、 家居厨卫、速食冻品、粮油调味等品类商品,满足家庭日常三餐所需,价格普遍 低于市场价。
用户可在每天 0 点到 23 点通过美团优选微信小程序下单,次日到门店或团长处 自提,最早中午前就可收到商品。在购买、收货过程中遇到问题,用户都可通过 团长解决,美团优选提供 100%售后支持。“预购+自提”模式可实现按需集中采购,并减少商品的运输、存储时间,最大 程度保障商品新鲜度且降低损耗,同时省去了最后一公里的配送成本,从而让利 给消费者,使得商品更具价格优势。
聚类分析
聚类分析介绍
聚类分析或聚类是对一组对象进行分组的任务,使得同一组(称为聚类)中的对 象(在某种意义上)与其他组(聚类)中的对象更相似(在某种意义上)。它是 探索性数据挖掘的主要任务,也是统计 数据分析的常用技术,用于许多领域, 包括机器学习,模式识别,图像分析,信息检索,生物信息学,数据压缩和计算 机图形学。
聚类分析本身不是一个特定的算法,而是要解决的一般任务。它可以通过各种算 法来实现,这些算法在理解群集的构成以及如何有效地找到它们方面存在显着差 异。流行的群集概念包括群集成员之间距离较小的群体,数据空间的密集区域, 间隔或特定的统计分布。因此,聚类可以表述为多目标优化问题。适当的聚类算 法和参数设置(包括距离函数等参数)使用,密度阈值或预期聚类的数量)取决
于个体数据集和结果的预期用途。这样的聚类分析不是自动任务,而是涉及试验 和失败的知识发现或交互式多目标优化的迭代过程。通常需要修改数据预处理和 模型参数,直到结果达到所需的属性。
常见的聚类方法
常用的聚类算法分为基于划分、层次、密度、网格、统计学、模型等类型的算法,典型算法 包括 K 均值(经典的聚类算法)、DBSCAN、两步聚类、BIRCH、谱聚类等。
K-means 聚类
聚类算法中 k-means 是最常使用的方法之一,但是 k-means 要注意数据异常:1、数据异 常值。数据中的异常值能明显改变不同点之间的距离相识度,并且这种影响是非常显著的。 因此基于距离相似度的判别模式下,异常值的处理必不可少。2、数据的异常量纲。不同的 维度和变量之间,如果存在数值规模或量纲的差异,那么在做距离之前需要先将变量归一化 或标准化。例如跳出率的数值分布区间是[0,1],订单金额可能是[0,10000 000],而订单数量 则是[0,1000],如果没有归一化或标准化操作,那么相似度将主要受到订单金额的影响。
DBSCN 聚类
有异常的数据可以使用 DBSCAN 聚类方法进行处理,DBSCAN 的全称是 Density-Based Spatial Clustering of Applications with Noise,中文含义是“基于密度的带有噪声的空间聚类”。 跟 K 均值相比,它具有以下优点:1、原始数据分布规律没有明显要求,能适应任意数据集 分布形状的空间聚类,因此数据集适用性更广,尤其是对非凸装、圆环形等异性簇分布的识 别较好。2、无需指定聚类数量,对结果的先验要求不高。由于 DBSCAN 可区分核心对象、 边界点和噪点,因此对噪声的过滤效果好,能有效应对数据噪点。由于他对整个数据集进行 操作且聚类时使用了一个全局性的表征密度的参数,因此也存在比较明显的弱点: 1、对于 高纬度问题,基于半径和密度的定义成问题。2、当簇的密度变化太大时,聚类结果较差。 3、当数据量增大时,要求较大的内存支持,I/O 消耗也很大。
MiniBatchKMeans 聚类
K 均值在算法稳定性、效率和准确率(相对于真实标签的判别)上表现非常好,并且在应对 大量数据时依然如此。它的算法时间复杂度上界为 O(nkt),其中 n 是样本量、k 是划分的聚 类数、t 是迭代次数。当聚类数和迭代次数不变时,K 均值的算法消耗时间只跟样本量有关, 因此会呈线性增长趋势。但是当面对海量数据时,k 均值算法计算速度慢会产生延时,尤其 算法被用于做实时性处理时这种弊端尤为明显。针对 K 均值的这一问题,很多延伸算法出 现了,MiniBatchKMeans 就是其中一个典型代表。MiniBatchKMeans 使用了一个种名为 Mini Batch(分批处理)的方法计算数据点之间的距离。Mini Batch 的好处是计算过程中不必使 用所有的数据样本,而是从不同类别的样本中抽取一部分样本(而非全部样本)作为代表参 与聚类算法过程。由于计算样本量少,所以会相应减少运行时间;但另一方面,由于是抽样 方法,抽样样本很难完全代表整体样本的全部特征,因此会带来准确度的小幅度下降,但是并不明显。
谱聚类
在大数据背景下,有很多高纬度数据场景,如电子商务交易数据、web 文本数据日益丰富。 高维数据聚类时耗时长、聚类结果准确性和稳定性都不尽如人意。因为,在高维数据,基于 距离的相似度计算效率极低;特征值过多在所有维度上存在簇的可能性非常低;由于稀疏性 和紧邻特性,基于距离的相似度几乎为 0,导致高维空间很难出现数据簇。这时我们可以选 着使用子空间聚类,或是降维处理。子空间聚类算法是在高维数据空间中对传统聚类算法的 一种扩展,其思想是选取与给定簇密切相关的维,然后在对应的子空间进行聚类。比如谱聚 类就是一种子空间聚类方法,由于选择相关维的方法以及评估子空间的方法需要自定义,因 此这种方法对操作者的要求较高。
使用聚类分析中间预处理
图像压缩
用较少的数据量来表示原有的像素矩阵的过程,这个过程称为图像编码。数据图像的显著特 点是数据量庞大,需要占用相当大的储存空间,这给图像的存储、计算、传输等带来了不便。 因此,现在大多数数字网络下的图像都会经过压缩后再做进一步应用,图像压缩的方法之一 便是聚类算法。
在使用聚类算法做图像压缩时,我们会定义 K 个颜色数(例如 128 种颜色),颜色数就是聚 类类别的数量;K 均值聚类算法会把类似的颜色分别放在 K 个簇中,然后每个簇使用一种颜 色来代替原始颜色,那么结果就是有多少个簇,就生成了多少种颜色构成的图像,由此实现图像压缩。
图像分割
图像分割就是把图像分成若干个特定的、具有独特性质的区域并提出感兴趣的目标技术和过 程,这是图像处理和分析的关键步骤。图像分割后提取出的目标可以用于图像语义识别,图 像搜索等领域。例如从图像中分割出前景人脸信息,然后做人脸识别。聚类算法是图像分割 方法的一种,其实施的关键是通过不同区域间明显不同的图像色彩特征做聚类,聚类数量就 是要分割的区域的数量。
图像理解
在图像理解中,有一种称为基于区域的提取方法。基于区域的提取方法是在图像分割和对象 识别的前提下进行的,利用对象模板、场景分类器等,通过识别对象及对象之间的拓扑关系 挖掘语义,生成对应的场景语义信息。例如,先以颜色、形状等特征对分割后的图像区域进 行聚类,形成少量 BLOB;然后通过 CMRM 模型计算出 BLOB 与某些关键词共同出现的概率。
异常检测
异常检测有多种实施方法,其中常用的方法是基于距离的异常检测方法。即使数据集不满足 任何特定分布模型,它仍能有效地发现离群点,特别是当空间维度比较高时,算法的效率比 基于密度的方法要高得多。算法具体实现时,首先算出数据样本间的距离(如曼哈顿距离、 欧氏距离等),然后对数据做预处理后就可以根据距离的定义来检测异常值。 例如,可以使用 K-means 的聚类可以将离中心店最远的类或者不属于任何一个类的数据点 提取出来,然后将其定义为异常值。
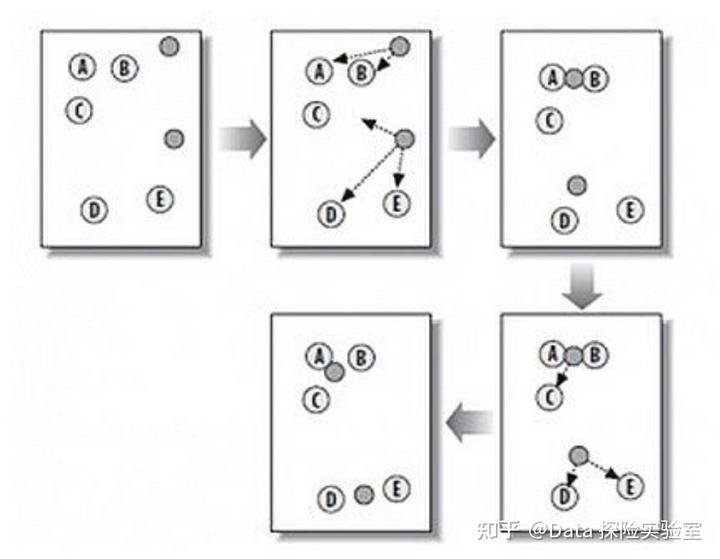
实验过程算法流程
1、从 N 个样本数据中随机选取 K 个对象作为初始的聚类质心。
2、分别计算每个样本到各个聚类中心的距离,将对象分配到距离最近的聚类中。
3、所有对象分配完成之后,重新计算 K 个聚类的质心。
4、与前一次的 K 个聚类中心比较,如果发生变化,重复过程 2,否则转过程 5。
5、当质心不再发生变化时,停止聚类过程,并输出聚类结果。如图所示 :
情景问题的模型建立
美团平台搭建了线下门店和用户的桥梁。用户在平台上搜索满意的门店,然后到 店消费。门店通过平台引流获取用户。平台通过团购的提点(类似于 CPS)获得收入。三方均各取所需。商户是平台的收入来源方,为了健康地提升平台的收入。 需要建立商户的价值评估模型,对商户进行分类,比较不同类别的商户价值,并 制定相对应的策略。商户的价值模型分为两部分:商户本身的价值和商户给平台 带来的价值。 商户本身的价值用两个指标衡量:1)商户的“星级”;2)商户获取的“DAU” 数。星级高或者DAU高对应的商户价值便高。商户给平台带来的价值用一个指标 衡量:通过交易提点给平台带来的收入。将这个指标进行处理后,得到“单 DAU 价值”这个指标(公式:收入/DAU)。
主要步骤
1、对数据集进行数据探索分析与预处理,包括数据缺失与异常处理、数据属性 的规约、清洗和变换。
2、利用步骤 1 中完成预处理的数据,基于 LRFMC 模型进商户价值模型分类。 3、针对不同价值类型的商户提供不同的营销策略
Python 实现
#代码涉及的所有模块引入
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans import matplotlib.pyplot as plt 导入数据
predata = pd.read_excel('shop_data.xlsx', sheet_name='工作表 1') #读取原始文件
简单的数据查看
print(type(predata)) #
# 'score'对应星级 'DAU'对应 DAU 'tg_income'对应团购收入
print(predata.columns) #(['shopid', 'shopname', 'score', 'DAU', 'tg_income'], dtype='object') print(predata.head()) #查看前 5 行数据
print(predata.isna().sum()) #统计所有空值(NA)
explore = predata.describe(percentiles = [], include = 'all').T #基本描述,percentiles 参数是 指定计算多少的分位数表(如 1/4 分位数、中位数等);T 是转置,转置后更方便查阅 print(explore)
数据清洗
data = predata.dropna() #去除含有空值的行
data = data[['score', 'DAU', 'tg_income']] #只包含数字信息 数据标准化处理
data['DAU_values'] =0 #引入“单 DAU 价值”一列
data['DAU_values'] = data['tg_income'] / data['DAU']
data['DAU_values'] = data['DAU_values'].fillna(0) #DAU 包含 0 值,除完后为 NA data = data[['score','DAU','DAU_values']]
data = (data - data.mean(axis=0))/(data.std(axis=0)) #z-score 标准
调用 k-means 算法,进行聚类分析
kmodel = KMeans(n_clusters=5, n_jobs=4) #n_jobs 是并行数,一般等于 CPU 数较好 kmodel.fit(data) #训练模型 #注意:n_clusters=5,“5”需要人为提前输入。具体输入值需要不断测试观察进行判断 结果输出
label = pd.Series(kmodel.labels_) # 各样本的类别
num = pd.Series(kmodel.labels_).value_counts() # 统计各样本对应的类别的数目
center = pd.DataFrame(kmodel.cluster_centers_) # 找出聚类中心
max = center.values.max()
min = center.values.min()
X = pd.concat([center, num], axis=1) # 横向连接(0 是纵向),得到聚类中心对应的类别数 目
X.columns = list(data.columns) + ['NUM'] # 表头加上一列
绘图(雷达图)
fig = plt.figure(figsize=(8,6))
ax = fig.add_subplot(111, polar=True) #polar=True 画圆形 feature = ['score','DAU','DAU_values']
center_num = X.values #
N = len(feature)
for i, v in enumerate(center_num):
# 设置雷达图的角度,用于平分切开一个圆面 angles = np.linspace(0, 2 * np.pi, N, endpoint=False) # 为了使雷达图一圈封闭起来,需要下面的步骤 center = np.concatenate((v[:-1], [v[0]]))
angles = np.concatenate((angles, [angles[0]]))
# 绘制折线图
ax.plot(angles, center, 'o-', linewidth=2, label="NO.%d = %d (%d%%)" % (i + 1, v[-1],v[-1]*100/total))
# 填充颜色
ax.fill(angles, center, alpha=0.25)
# 添加每个特征的标签
ax.set_thetagrids(angles * 180 / np.pi, feature, fontsize=12) # 设置雷达图的范围
ax.set_ylim(min - 0.1, max + 0.1)
# 添加标题
plt.title('SHOP_CLUSTERING', fontsize=20) # 添加网格线
ax.grid(True)
# 设置图例
plt.legend(loc='upper right', bbox_to_anchor=(1.3, 1.0), ncol=1, fancybox=True, shadow=True)
# 显示图形 plt.show() 数据输出
shop_data_output = 'shop_data_output.xls' out = pd.concat([predata, label], axis=1) out.to_excel(shop_data_output, index = False) 实验结果
得到如下图(雷达图指标基于聚类的质心绘制):
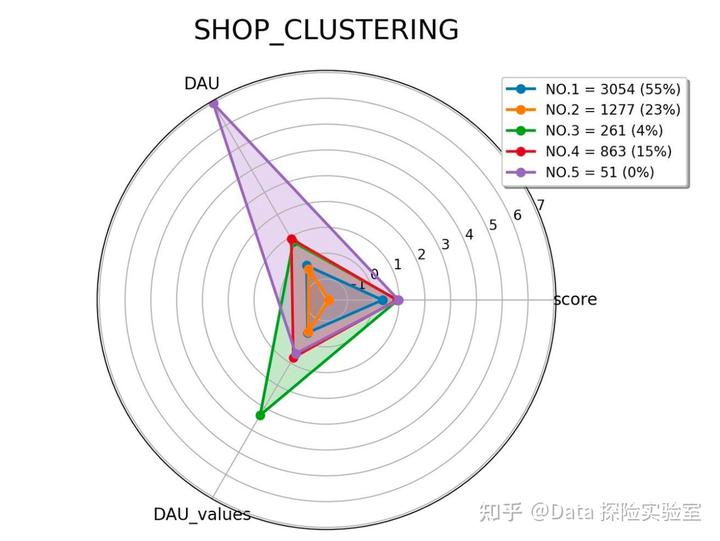
将商户分为 5 类:
DAU 和 DAU 价值表现差,星级表现不错
DAU、DAU 价值和星级表现均差
DAU 和星级表现不错,DAU 价值表现佳
DAU、星级和 DAU 价值表现均不错
DAU、星级表现不错,DAU 价值表现佳
将上述 5 类商户进行业务描述:
第一类商户定义为:发展类商户.商户体量大(占比 55%),具备较大的发展潜力空间,未来可以往“分类 4”商户 发展,可以通过“霸王餐”等用户体验活动,积累好评,提升星级,进而提升门 店竞争力,不适合采购额外的线上流量。
第二类商户定义为:低价值商户,不应投入过多的精力.
第三类商户定义为:超优质商户 重点服务对象,具备“高客单价”或者“高访购率”特性,如果线下承载能力存 在空余(或特殊时段空余),可以进行固定时间段线上营销活动,提升线上流量。
第四类商户定义为:优质商户 提升服务质量,适当提升平均客单价,往高客单价发展,适度进行线上营销活动, 提升线上流量。
第五类商户定义为:特殊商户.这部分商户比较特殊,可能是大型连锁店或者网红店为主,需要特殊对待
