我全面参与了一次开源对话模型(俗称为开源版“ChatGPT”)开发的非凡之旅。在这个过程中,我有幸与一群来自UCB(主导这个项目)、CMU、Stanford、UCSD的充满热情且能力强劲的学生们紧密合作(此外MBZUAI提供了部分资源),共同实现了这一卓越的成就。出于一些合理的原因(正文会详细描述),我们使用 GPT-4比较并评估了我们的模型——Vicuna-13b 和其他模型在“开放式”问题上的性能差距。GPT-4 给我们模型的“总分”最终达到了ChatGPT的90%(最终怎么界定这个评分取决于不同的标准,我们会在正文中解释)。并且相对于Alpaca-13b 等模型,GPT-4在绝大多数问题上偏向于我们的 Vicuna,并且给出了令人信服的详细归因解释。我们团队的长远目标之一是能够以合规,廉价和高效的方式做出真正意义上和ChatGPT-3.5 相当的开源版本ChatGPT,这次是我们的一小步。
这个项目涉及许多复杂环节,如数据收集、基础模型选择、训练、推断、评估设计、可视化、风险评估、风险防范、服务架设、内部测试以及公开测试等。在接下来的内容中,我将详细地分享我们在这个过程中的一些具体经验和收获,希望能为开源社区做出贡献。如果你觉得我的回答很有帮助或者很有启发,欢迎评论,点赞并转发。
也请给我们的开源项目点赞 :GitHub - lm-sys/FastChat: The release repo for "Vicuna: An Open Chatbot Impressing GPT-4。近期我们会以合规的方式公开模型参数。
我们有一个网站,展示了各个模型之间的区别(目前只包括英文问题,后续会增加中文等语言):vicuna.lmsys.org/eval/
此外,感兴趣的读者可以看我们的英文blog,或者在hackernews 上(如果可以访问)和我们互动。
我们有一个在线的demo,虽然我们的服务能力和模型的中文能力有限,但是欢迎大家测试(移动端有时会遇到问题,不过刷新一下很多时候可以解决)。
Part I - 训练ChatGPT水平的对话模型的三座大山
如果你的目的不是训练一个吉祥物,而是勇敢地向 ChatGPT (3.5) 的水平和实用性发起冲击,那么接下来,你就要克服三座大山:
1. 基础模型
一个广为(业内)人知的经验观察是,一个大型对话语言模型的质量,很大程度上基于它的“预训练”模型的质量以及大小(虽然两者有相关性,比如相同的数据一致的训练方法下,更大的模型质量更高)。这类预训练模型又被称为基础模型(foundation model)。基础模型为了保证质量,会使用整个互联网规模的数据进行预训练,其开销不是开源社区所能承担的。有幸的是,Meta 向公众发布了一套名叫 LLaMA 的预训练模型,可以通过申请取得。开源对话语言模型的先驱者 Alpaca 便是在 LLaMA-7b 的基础上“微调(finetuning)”得到的。
微调所需的计算资源,和模型的大小基本成正比。上文的 LLaMA-7b 是含有70亿参数(1b=10亿)的模型,也是最小的一个。我们早期同时训练了一个7b的模型和13b的模型,初步人工评测显示13b的模型要好不少。因此我们决定使用13b的模型。注意这不是一个严格的的结论,而只是一个经验观察。不过我个人认为这个观察很可能是对的,因为有相关但未经证实的消息声称,ChatGPT 3.5的最新模型,gpt-3.5-turbo,很可能是一个 20b 左右的模型。我考虑到 gpt-3.5-turbo 的推断价格只有 Davinci (大小未知,但极大概率~175b)的1/10,这个 20b 的声称是有道理的。综上,以 LLaMA-13b 为基础模型,是平衡微调成本且尽可能接近 ChatGPT-3.5 模型大小的一个综合决定。
2. 对齐数据
回到上文的“微调”。上文所谓的“微调”专指在预训练模型的基础上,用优质的数据去对齐(align)模型的输出,使得其回答和交互符合人类的规范,成为一个“合格”且“有用”的聊天机器人。
然而要如何获得这些用于“对齐”的数据呢?“巧妇难为无米之炊“,高质量数据对于训练的重要性不言而喻,而高质量对齐数据又不同于一般的高质量语言数据。高质量对齐数据是“高质量的问题”+“高质量的解题过程(可选)”+“高质量解答”的完整组合。这里举一个并不完全恰当但是可以意会的例子:爱因斯坦的文章是高质量数据,而爱因斯坦写文章的背景问题,动机,写文章的思路,最后写出的文章,这些组合在一起,才是高质量对齐数据。
所以,高质量的对齐数据一般来说比高质量的数据更加稀少。有一部分人怀疑,Google 虽然能够搞出 PaLM 这种非常厉害的基础模型,但是近期推出的 Bard 却无法和 ChatGPT 竞争的原因之一便是缺少高质量对齐数据。这种数据实在太难清理和收集了,即使以Google的体量,收集清理出这些数据也绝非易事。这种怀疑也促进了最近一则未经证实的爆料的转播。这则未经证实的爆料中一位离职的AI研究员声称 Google 在使用 ShareGPT (一个ChatGPT 数据共享网站,用户会上传自己觉得有趣的ChatGPT回答) 的数据进行训练,而ShareGPT恰恰就是一个高质量的对齐数据来源。我个人无法鉴别真伪也不提供态度,但是这足以体现对齐数据的重要性和紧迫性。
非常可惜的是,目前已知的“有效”和“合规”的获取高质量对齐数据的方式,是非常有限的。要以低成本获取对齐数据,目前已知的方法有 1. 直接用 ChatGPT 根据你准备的一套问题去生成数据,因为ChatGPT本身就是高度对齐的模型 2. 让用户主动上传和公开和ChatGPT 的聊天,然后获得用户上传的数据。这两套方法都是“灰度”的,因为它们都潜在地违反了 OpenAI ChatGPT 的使用协议:用 ChatGPT的输出对 OpenAI 产生竞争。
目前使用方法1的项目有先前提到的 Alpaca 和 最近比较火的 GPT4All. 后者甚至直接用 ChatGPT API 生成了 800k 数据。
而我们的项目使用了方法2,即使用 ShareGPT 的数据。个人认为这种方法不容易产生争议,基于的事实是(1)OpenAI的所有产品也是基于公开数据训练的,很大程度上来自于用户自愿公开的数据,无论数据的来源;ShareGPT数据也属于用户自愿分享的公开数据(2)用户公开的数据中,问答的问题部分是用户创作的 (不是API调用者自己生成的),且用户自愿公开上传数据,因此产权不属于 OpenAI(3)作为开源项目,并没有与OpenAI 产生直接的商业竞争,我们在 blog 中也声称了不能用于商业目的。Google Bard 使用 ShareGPT 的传闻造成负面影响的最重要原因就是 Google 是商业公司,即使使用间接生成的数据在商业竞争上也是非常敏感的。
权衡之后,我们决定 Vicuna 仅使用 ShareGPT 等公开数据,而不是我们自己调用ChatGPT API 生成数据。不过 ShareGPT 数据的获取很大程度上决定于 ShareGPT 维护者的意愿。出于各类原因,维护者目前已经关闭了公开获取数据的接口,基于 ShareGPT 维护者的意愿,我们仅公开模型和训练方法,而不会公开和ShareGPT相关的训练数据。
最后讨论一下使用 ShareGPT 等公开用户数据对模型微调的利弊:
3. 开放式评测
训练过程中(或者结束后)一个非常重要的问题便是:我的模型性能如何?这对控制模型训练至关重要。在传统的NLP方法中,评测往往通过某种“标准化考试”决定。然而,这种方法并不适合ChatGPT这种为对话设计的通用语言模型(虽然有点讽刺的是,ChatGPT这种通用模型也把这些问题的榜单刷爆了),因为大家更看重它们的通用的可以变通的对话能力,回答翔实独到,而不是把它们当作只会做特定类型题目,且不知变通的答题机器。
先前 Alpaca 等工作主要用了 “self-instruct” 等方法,本身具有一定的开放性。但是我们尝试后发现这些问题虽然开放,但是还不够开放,正如名字所示,问题强烈的倾向于“指令”类的问题。我们可以观察到这种训练导致的bias: 训练出的模型的一大特征是回复比较短且缺乏细节,这很可能因为其回复的目的被人为设定成“解决指令提出的要求”,而不是“有趣,有深度,有特点的回答”。
我们试了self-instruct中的一些问题,发现我们的模型回答的都很好,甚至很多很难和ChatGPT的回答分出高下。这当然并不意味着我们的模型真的达到ChatGPT的水平了,毕竟Alpaca也声称了类似的结果,然而显然它离ChatGPT 还有很大距离。所以结论其实是这类问题对于在评估更高水平的聊天机器人的水平上缺乏区分度。
所以我们决定使用更加开放更加有挑战性的问题来评估这些聊天机器人的性能。参见我们的网站:vicuna.lmsys.org/eval/
这些问题包括以下类别:
写作:一些复杂场景和要求的写作,比如说 Compose an engaging travel blog post about a recent trip to Hawaii, highlighting cultural experiences and must-see attractions. 这里的写作就有很多要求,并且不少要求是“开放”的:(1)形式是一个博客(2)主题是旅行(3)地点是夏威夷(4)内容要“引人入胜“ (5)要突出文化体验和必玩景点 (6)因为夏威夷有很多岛,所以一个隐含的要求是博文中展示的行程是合理的角色和场景:综合考虑AI处理角色和场景的能力,比如说:You are a mountain climber reaching the summit of Mount Everest. Describe your emotions and the view from the top. 这里的场景是珠峰顶部,角色是一个登山者,要求是描述这个角色的情感和山顶看到的景色。常识解释问题:要求聊天机器人解释日常现象,你会发现这些“常识”并不简单。比如说:How can you determine if a restaurant is popular among locals or mainly attracts tourists, and why might this information be useful? 你怎么分辨一个餐馆主要是在当地人中很火,还是主要是在旅客中很火呢?哪些信息会很有用?费米问题:非常困难的数量级估计问题,非常考验物理上的估计,常识,和综合知识水平。
比如:How many atoms are in a grain of salt? Try to explain your answer. Your explanation should take the reader through your reasoning step-by-step. 这里要求估计一粒盐里面有多少个原子,并逐步解释回答。反事实问题:考验逻辑水平和历史知识,需要将两者结合回答。比如说:What if the Internet had been invented during the Renaissance period? (如果互联网在文艺复兴时期产生会怎么样?)聊天机器人需要综合考虑历史背景,互联网的作用,以及做出互联网在那个时代存在带来的反事实结论。代码和数学问题:这部分我们增加了难度,特别是不提供示例和指引。略。一般性问题:比如压力管理,环境保护等“网红”问题,基本是送分题,我们用这些题目来测试校准我们的评估者。知识问题:要求对领域类知识有深入了解,比如 Explain the process of gene editing using CRISPR-Cas9 technology, and discuss its potential applications and ethical implications. 这个问题要求解释 CRISPR-Cas9 基因编辑技术的过程,探讨潜在的应用和伦理问题。
非常显然的,这些问题的回答会非常有区分度,但是其回答也会极其开放。那我们仍然可以用人类来评估这些问题吗(比如比较两个问题的回答)?我们觉得面对这种开放问题,人类评估者的缺陷被放大了:
如此开放的回答,会导致评分的不稳定,主要是个人的背景和立场不同可能会产生潜在的偏见,这种偏见在评估开放问题时可能是不易察觉的。我们希望所有的评估者都有一样的设置,都尽可能被设置的客观中立,并且有一个过程持续地校正偏见。会不会之前题目的问题和回答潜在地影响了人类评估者之后的决定?在相对不开放的问题评估中,由于评估要素较少,所以一般而言没有问题;但是这种复杂问题的评估就很难说了。我们希望评估者没有之前问题的任何记忆。很多问题是如此之难,超过了平均人类评估者的知识范围,我们需要一个百科全书式的评估者。我们希望对每一个问题有详尽的分析,但是你很难指望人类评估者以一致的分析方式和笔触给每个问题写详细分析,因为写几百个评估,人很容易厌烦。
但是很巧的是,这些都是GPT-4的强项——一个中立的,没有记忆的,百科全书式的,不厌其烦的评论员。
我们在GPT-4之前试过让GPT-3.5作为评测员,但是很快放弃了,原因是:
我们在评测中包含了GPT-3.5,这样一来就变成了自己评估自己回答,虽然它没有记忆,但是这样感觉有点像是作弊。GPT-3.5 对回答的顺序有强烈偏见,当比较两个题目时它强烈倾向于给后面一个题目高分。GPT-3.5 的知识水平不够。
而如果我们给 GPT-4一些精心设计的prompt(这部分需要很多对GPT-4或者prompt技术的理解), GPT-4 可以胜任评估任务(根据我们的观察,结果基本不受长度、顺序等的影响),其评测结果令人惊讶。下面是我们的prompt 的一部分,用于评估“通用”的回答(我们还有一些专用的prompt针对代码或者数学能力的评测,我会在之后的文章中分享经验):
We would like to request your feedback on the performance of two AI assistants in response to the user question displayed above.
Please rate the helpfulness, relevance, accuracy, level of details of their responses. Each assistant receives an overall score on a scale of 1 to 10, where a higher score indicates better overall performance.
Please first output a single line containing only two values indicating the scores for Assistant 1 and 2, respectively. The two scores are separated by a space.
In the subsequent line, please provide a comprehensive explanation of your evaluation, avoiding any potential bias and ensuring that the order in which the responses were presented does not affect your judgment.
这个基础的评分用的prompt设计的技巧在于:
首先完整的陈述任务:(1)你需要写的是反馈(2)评价对象是两个AI助手(3)评价内容是它们的回复的表现(4)回复的对象是上面列着的用户的问题。给出评价的标准:(1)有帮助(不是车轱辘话,且考虑回复的对象是人类用户,生成的回答要让人类可以理解)(2)相关(不能偏题)(3)准确(不能胡说八道)(4)详尽(不能太空太高或者回避细节)给出评分范围:1-10给出评分的意义:越高代表综合表现越好给出评分的第一行的输出格式:必须在第一行输出两个数字,分别代表给两个AI assistant的评分。用空格分隔评分给出评分的其余行的输出:要求提供一个详尽的分析给出更多评分限定条件:避免任何偏见;避免回答顺序影响结果
此外,在这个评测过程中,我们仍然是 human-in-the-loop 的,我们会查看 GPT-4的评估是否有道理,并总结各个模型的优缺点,而这个过程比人类直接生成评估要高效的多。虽然无法科学地证实这一点,但是可以感觉到GPT-4对不少答案的评估结果要好于一般人类。我们公开了所有的评估结果,各位可以去 vicuna.lmsys.org/eval/ 查看。
最后我们以这样的方式记分:我们让 Vicuna 和其他模型的回答以匿名的方式合并在一起,让GPT-4 比较它们,给每一个模型 1-10的评分。然后我们对每一对模型回答的所有问题的所有评分各自求和,得到总分。在这个条件下,我们达到了ChatGPT-3.5 性能的90%。此外我们如果我们只是统计比较中得分的差距,我们还可以得到一张“胜率”图(在这个指标下,我们的胜率甚至超过了Google Bard!):
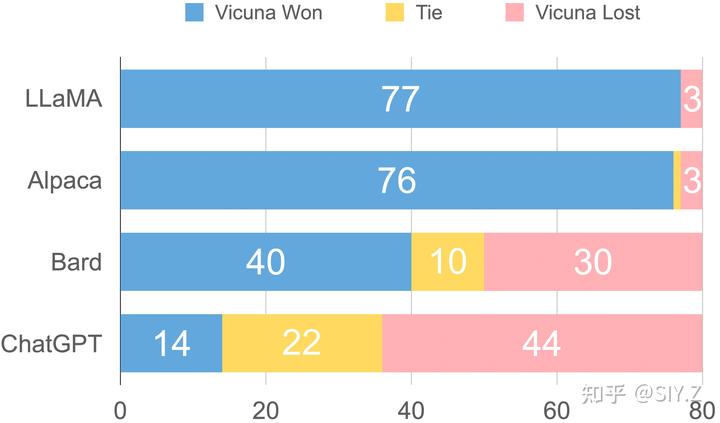
当然,GPT-4 的评估不是没有缺陷的,比如说,即使我们进行了深度的 prompt engineering 和各种调节, GPT-4仍然非常不擅长评估数学答案。我们在先前模型对比的网站中保留了相关的回复,供大家分析。
最后,我想回答一个很可能有人问到的问题,就是我们的评估不“严谨”。这里作为个人,我想说的是,新的问题需要新的解决方法。很多严谨的方法和体系,不是一天形成的,而是长期积累和试验的结果。其实我们的评测方法和这篇最近有名的论文非常类似:Sparks of Artificial General Intelligence: Early experiments with GPT-4,都是在以更加困难和开放,但是有目的性的问题摸索AI能力的边界,理解AI的优势和局限性。论文中的MSR大佬们很多有理论计算机的背景,可以说是世界上最严谨的一批人了,但是他们意识到,对于现在的接近通用型的AI,旧的评估方法和框架已经不适用了,新的一套方法称为“Physics of AI” (AI 的物理学)。这是因为现在的AI的黑箱性质,和物理学有类似之处:(1)原理上我们只能观测到现象,所以我们要做各种试验(2)我们希望这些试验是“不平凡”的,甚至是“破坏性”的,比如只有在极高的速度或者极低的温度下,才能发掘到新的现象,这些新的现象将会开拓或者补充现有的物理模型;对于AI来说,这些实验可能包括一些困难的或者奇怪的开放问题(3)我们要像物理学那样提出假设,用实验验证假设。这边贴上 Sébastien 大佬的原话:
We propose an approach to the science of deep learning that roughly follows what physicists do to understand reality: (1) explore phenomena through controlled experiments, and (2) build theories based on toy mathematical models and non-fully- rigorous mathematical reasoning.
无论是用GPT-4评测其他更“弱”的AI的回答,还是试图充分理解和评测接近 ChatGPT 性能的对话模型,都是史无前例的,哪怕提前几个月都是不可想象的事情。在这片荒芜的土地上,作为研究者,我愿意迈出这一步,逐渐从平地构建起一个严格的评测通用AI的体系,并浪漫的相信希尔伯特所坚信的——我们必须知道,我们必将知道。
总结
以上内容是我们这个系列的 Part I,之后还会陆续发blog,介绍我们更多的评测结果;我们的training (我们如何仅仅用$300就完成了更大的模型在更大的数据集上的训练);我们的serving (我们是如何用有限的资源尽可能保证serving的稳定的);我们我们如何深度结合GPT-4进行项目开发等等更多信息;以及更多的相关知识。欢迎大家关注我。
花絮 - I
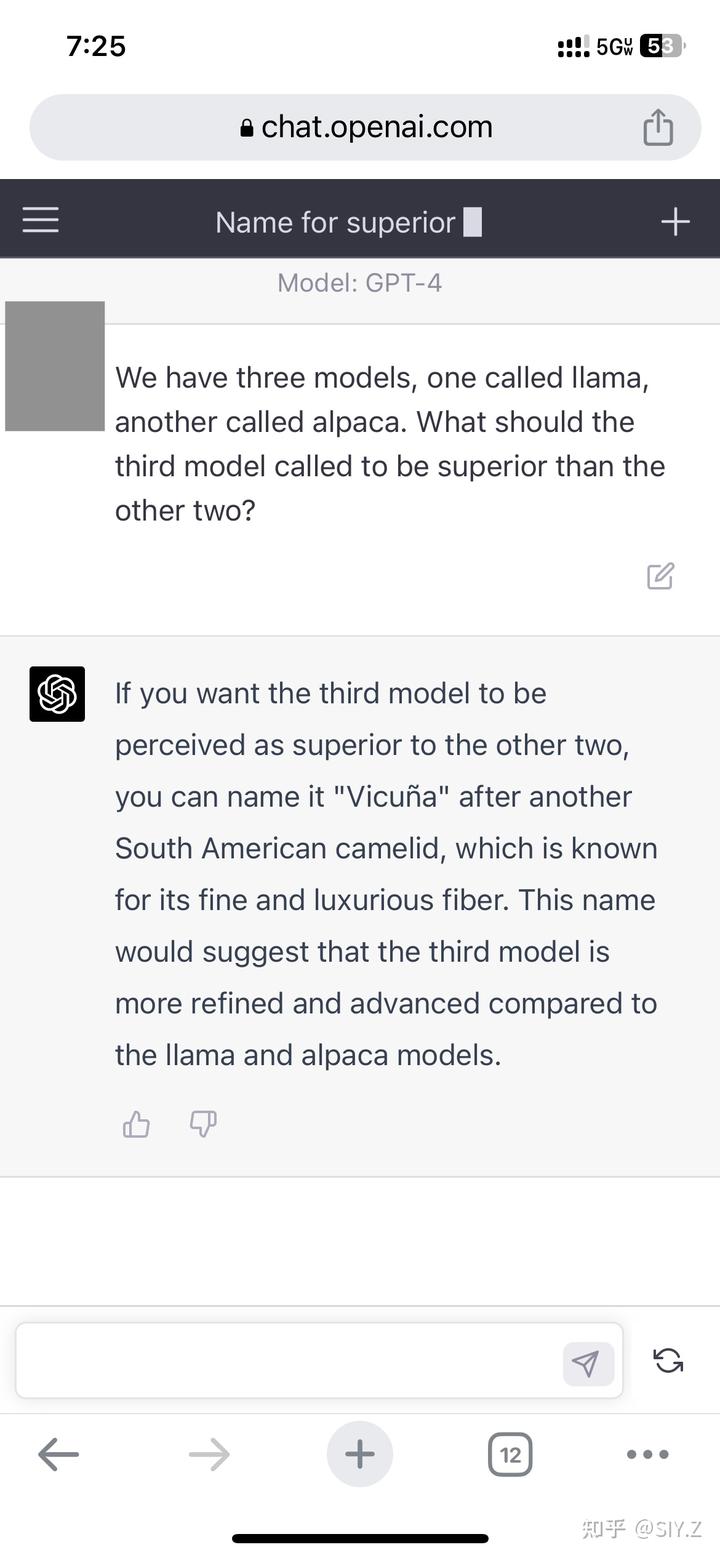
Vicuna 这个名字的来源是继承了 LLaMA 和 Alpaca 的 “羊驼命名”,是一种皮毛珍贵的小羊驼,我们独立于 GPT-4 起了这个名字,没想到 GPT-4 想出了同样的名字还给了理由。震惊。