目录
4-数字语音信号处理技术及应用 4.1-数字语音的基本概念 语音(Speech):人们讲话时发出的话语。=声音(Voice)+语言(Language)。比如:人发出嗯嗯啊啊的声音就算不上语音语音的基本声学特性 音强(客观):声音的强度,由声波的振幅决定响度(主观):与音强和频率有关,由人耳听觉特性决定音长:声音时间上的长短音调/音高:主要由基音频率决定。音调随频率的变化基本上呈对数关系
基音频率:发音体的最低振动频率
音色/音质:不同声音相互区别的特征,比如:我们能区别出A和B说的语音。体现了人对不同特性声音的主观感觉。主要由谐波/泛音(数量及强度)决定音色
谐波/泛音:频率为基频的整数倍
语音的基本组成 音素(Phoneme): 语音发音的最小单位。任何语言都有元音(Vowel)和辅音(Consonant)两种音素元音:音节的主干,从时长和能量的角度,在音节中都占主要部分共振峰:元音的重要声学特性,是区分不同元音、不同说话人性别/年龄的重要特征,不同元音对应一组不同频率的共振峰
共振峰产生过程:气流经过声道,声道受到激励而引起共振,使得一部分频率得到强化(产生了尖峰,即为共振峰),另一部分受到衰减
辅音:只出现在音节的前后两端,时长和能量都很小。根据声带的震动与否分清辅音和浊辅音
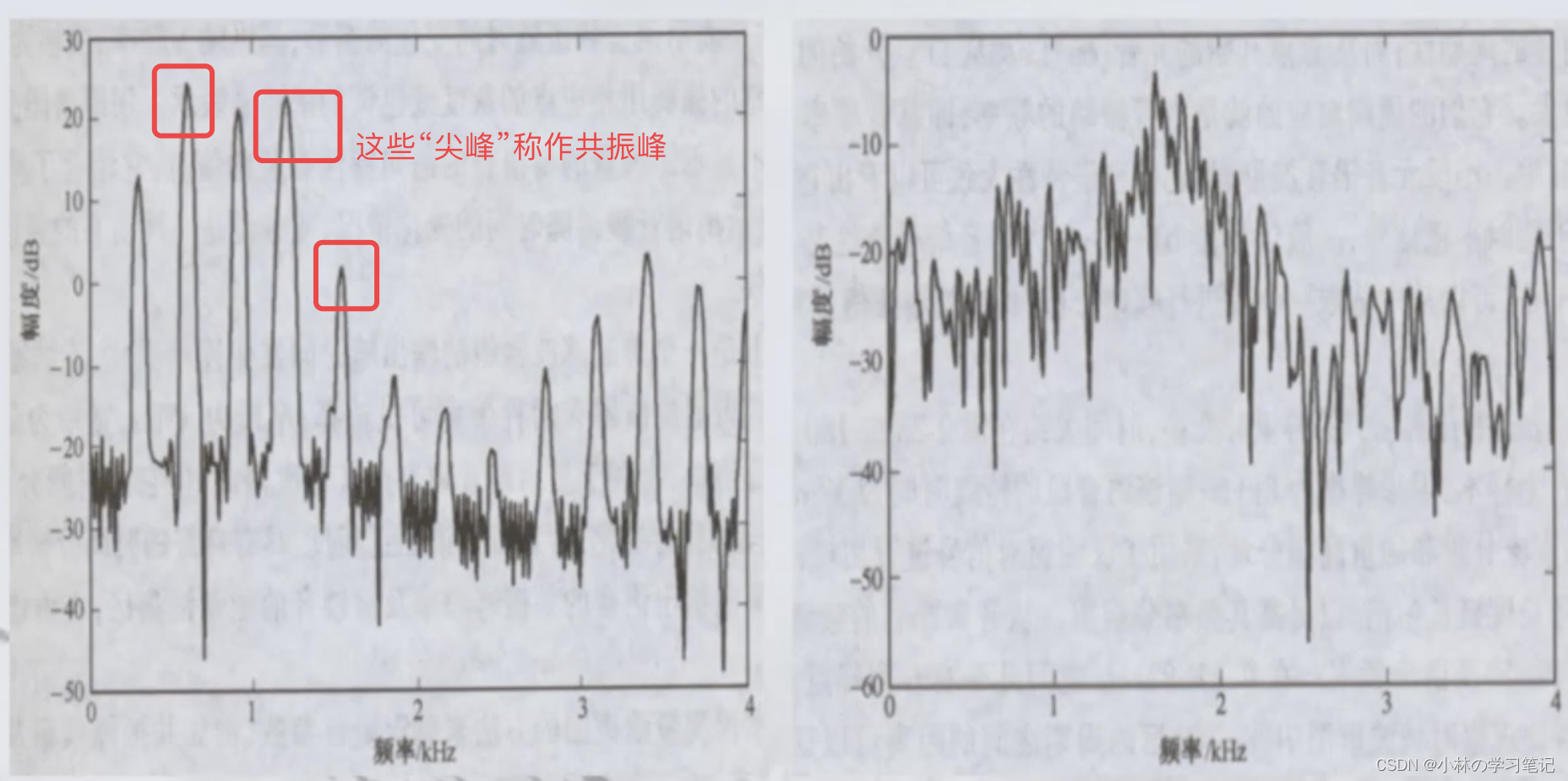
元音频谱图(左),清辅音频谱图(右)听觉掩蔽效应 概念:当两个频率和响度不等的声音作用于人耳时,响度较高的频率成份会影响人耳对响度较低的颁率成份的感受,使其变的不易察觉应用音频编码(感知编码)信息隐藏(音频水印)
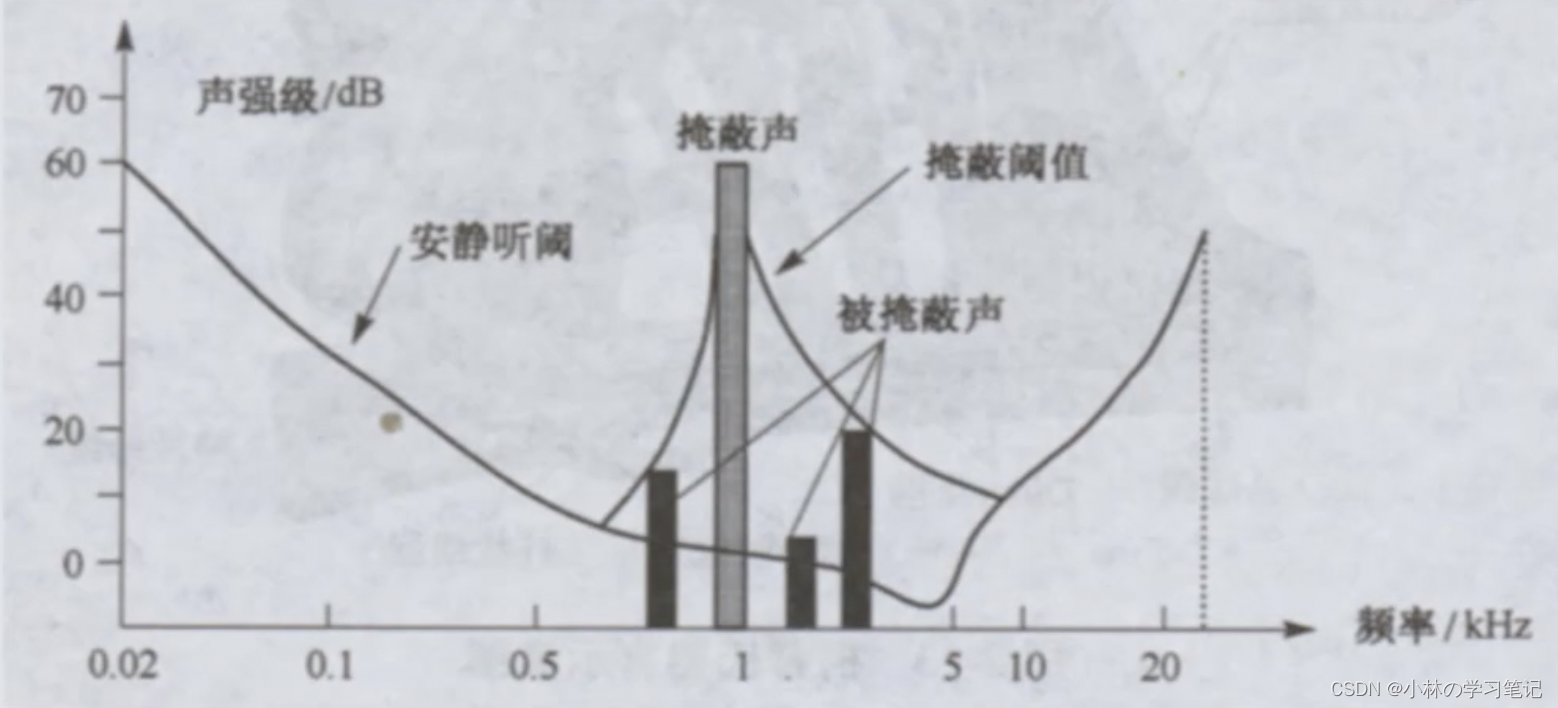
听觉掩蔽效应
4.2-数字语音技术主要研究方向
语音信号处理研究方向
语音识别:语音-->文字-->包含的语义语音合成:文字-->语音声纹识别:语音-->说话人,计算机能够识别出说出这段语音的人是谁情感识别:语音-->提取识别出说话人的情绪情感语音抗噪声技术:“软件+硬件”一体化解决方案语音评测:按照某种标准度进行评分评测,比如测评普通话语音编码(≈语音压缩):尽量高的压缩率、清晰度、还原度进行压缩减少码率语种识别:判断说的语言/方言语音特效
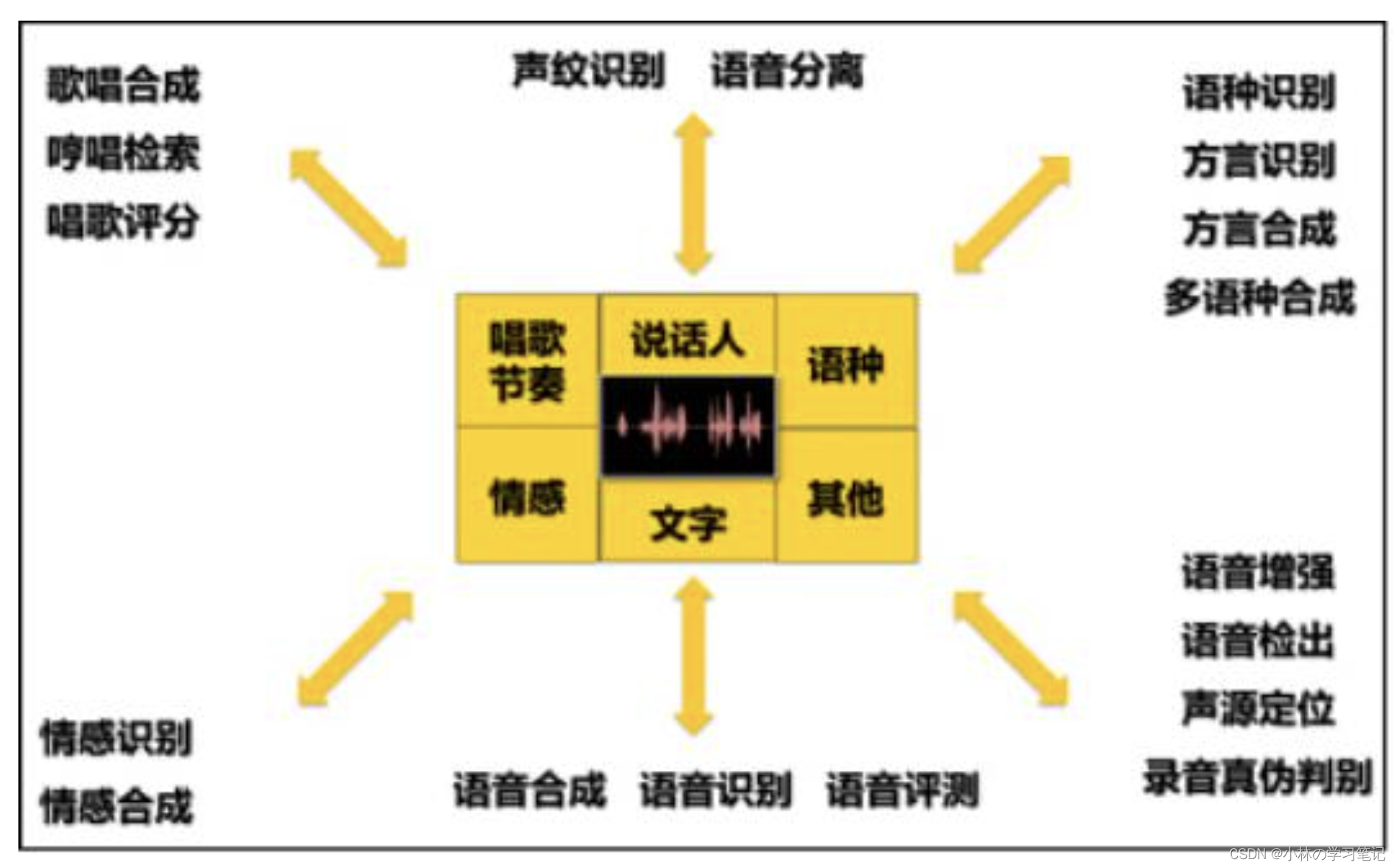
语音信号处理研究方向
4.3-语音识别 基本目标 将语音内容逐词逐句地转换为对应的文字正确理解语音中所包含的语义和要求技术难点 方言/口音背景噪音口语化问题,不遵循语法当前研究重点 即兴口语自然对话多语种同声翻译深度学习对于语音识别的语音模型、语言模型、以及整体处理流程等,都带来了巨大的变化,极大地促进了语音识别技术的产品化与普及化
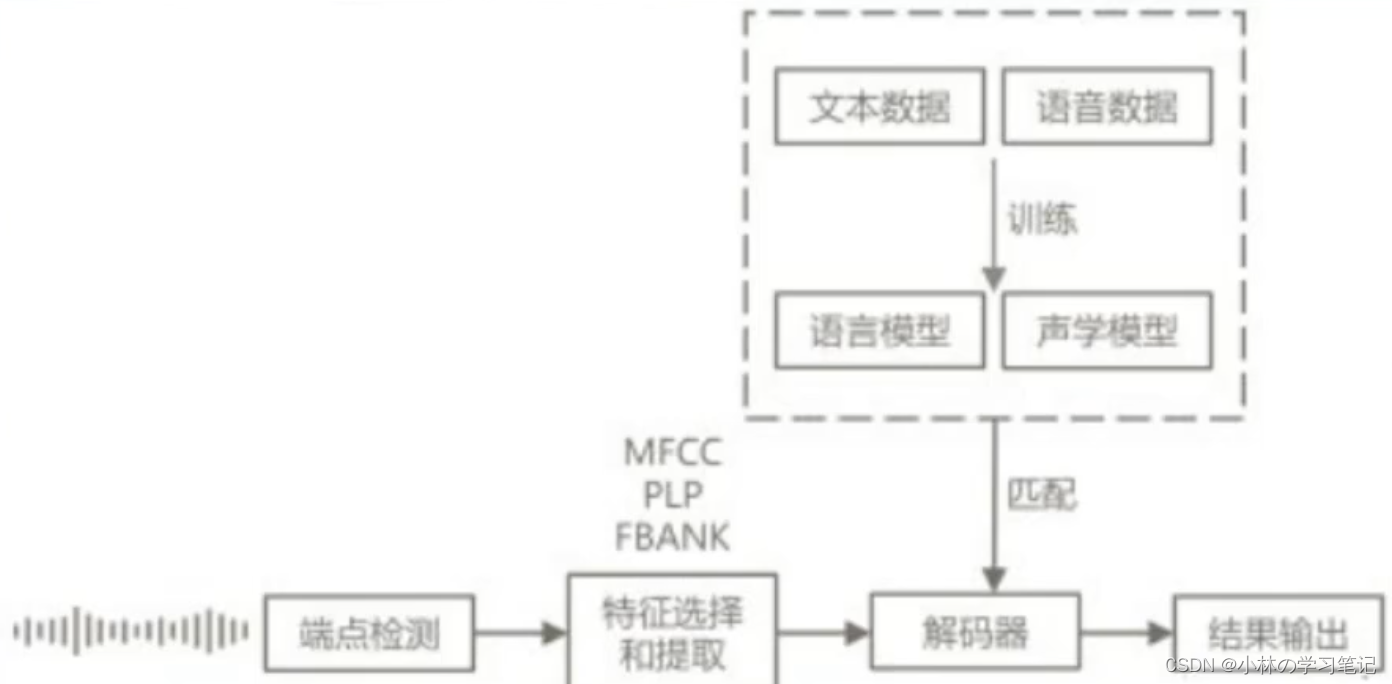
语音识别基本流程
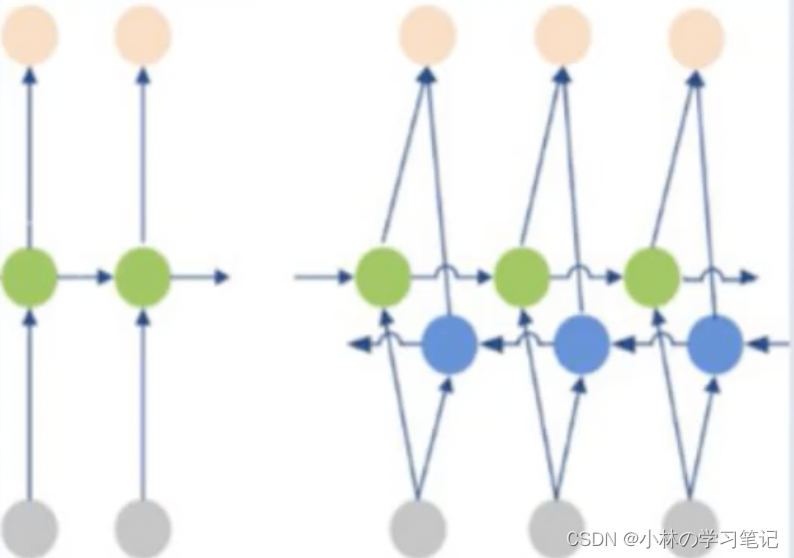
4.4-声纹识别与语音合成
声纹识别
目标:识别是哪个人说的研究重点:找出说话人声音的个性因素,强调不同人之间的特征差异类别按说话人判定说话人辨认:基于一/多段语音识别语音是哪个人说的说话人确认:确认某段语音是否是指定的某个人说的按语音内容是否限定判定文本相关操作:所有用户预先读出规定内容,并为每个用户建立声纹模型 --> 在识别时,仍要读出规定内容优点:技术实现简单,高识别率缺点:应用场景受限文本无关操作:建立声纹模型和识别时都不限定语音内容优点:应用场景灵活缺点:技术实现难度高语音合成技术 目标:将任意生成的文本转换为机器生成的语音,TTS技术研究重点提升端到端(一整个神经网络)的合成速度与可控性提升合成语音的情感表现,更加拟人化进一步提升合成语音的自然度语音识别 说话人识别 语音识别:语音-->文字说话人识别语音 --> 判定是谁说的,但是不翻译内容语音 --> 判定是否是某个人/特定几个人说的应用:语音门禁系统-->说话人识别,判定是否是某一个人说的
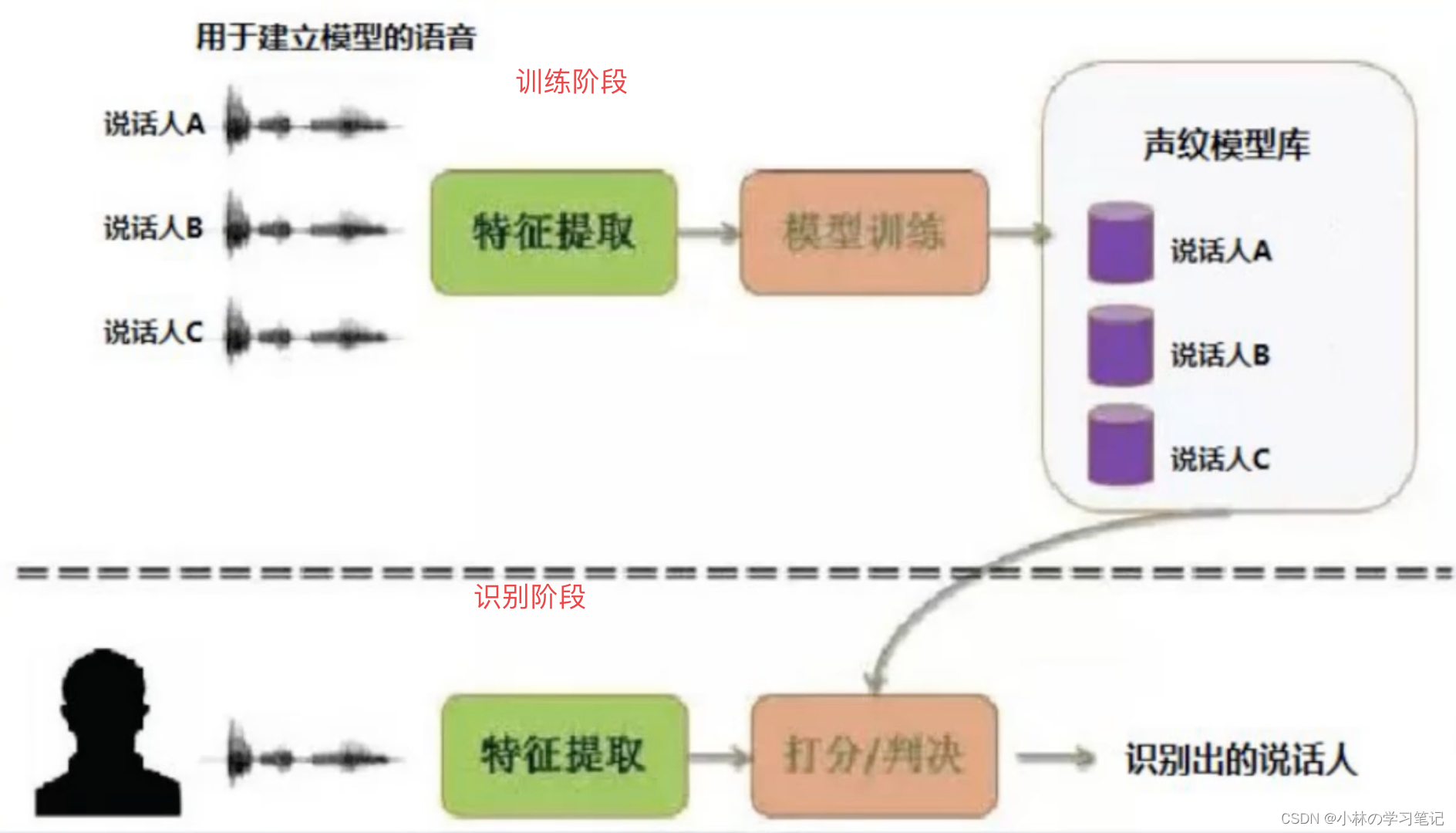
声纹识别整体流程|和机器学习流程相似,分为训练阶段和识别阶段
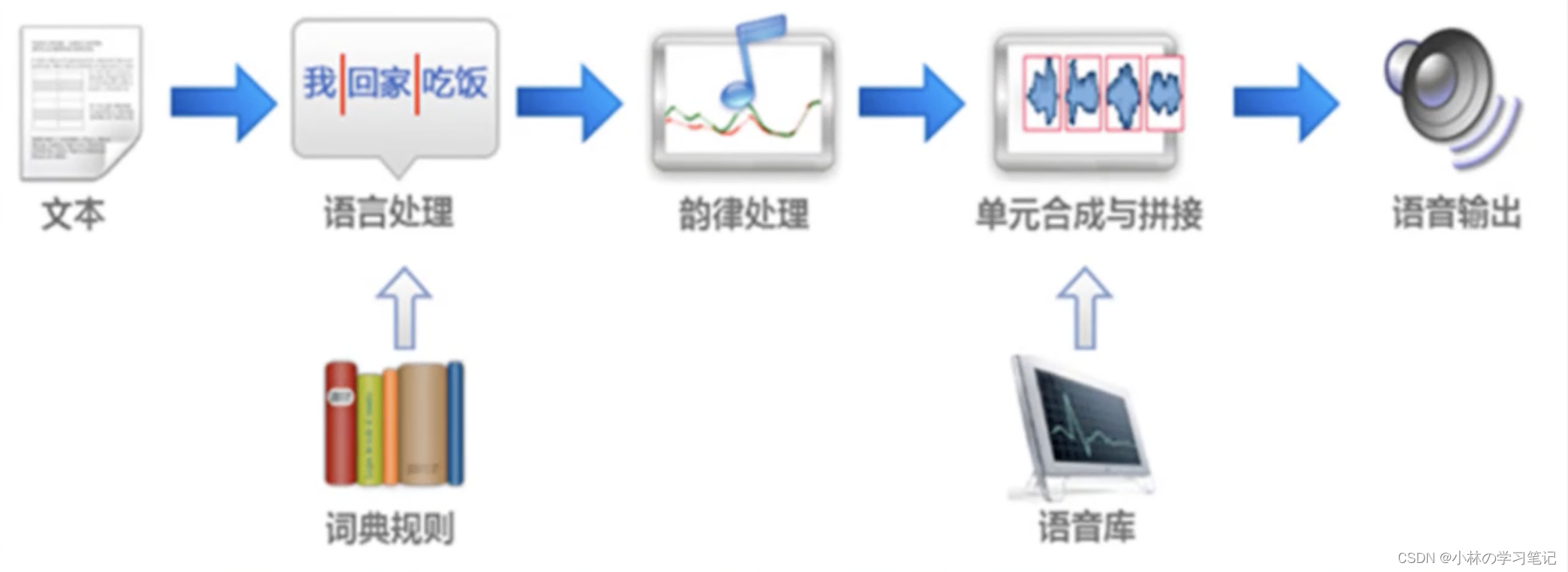
语音合成整体流程|step2利用自然语言处理技术进行分词、语言处理
若笔记存在记录错误,请批评指正!
学习视频来源⬇️
数字媒体技术概论_中国传媒大学_中国大学MOOC(慕课)数字媒体技术概论,spContent=以数字媒体、网络技术与计算机技术相融合而产生的数字媒体技术,已经成为最热门的研究领域之一。如果你想了解数字媒体技术的奥妙,并想从事数字媒体技术相关的工作,请加入我们吧!让我们一起共同领略数字媒体技术的魅力,打下坚实的数字媒体技术基础。,中国大学MOOC(慕课)
