原文地址:mp.weixin.qq.com/s/9BYk1ONd3gKTzBW0WnxuJw一、背景与数据来源介绍
新型肺炎作为一种存在潜伏期的传染病,分析其传染关系及接触关系非常有利于疫情的防控,对疫后的研究分析也有帮助。本文将介绍基于图数据库对新型肺炎图谱进行建模与分析的过程及效果。
图数据库(Graph Database)是一种复杂关系数据的处理系统,一种使用顶点、边和属性来表示与存储数据,并以图结构进行语义查询的数据库。图数据库的关键概念是边,通过边将顶点连接在一起,从而进行快速的图检索操作。
图数据库非常适合用于分析此类关联关系数据,此次使用百度开源的HugeGraph图数据库作为分析工具。分析数据数据均来源于各地卫健委或权威网站公开公布,如北京、石家庄、温州、南昌、宜春等城市。分析场景包括:
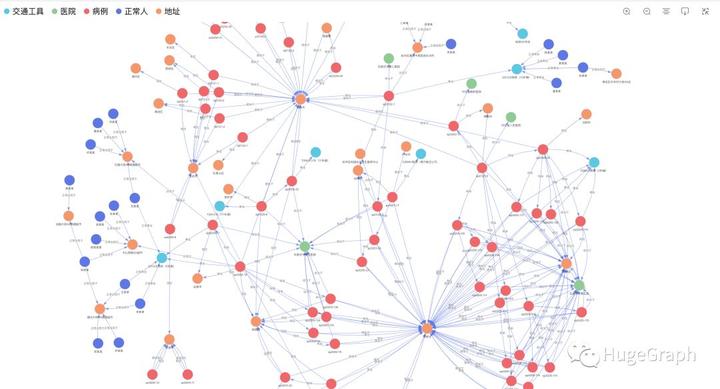
新型肺炎传染图谱
本次演示共导入了5类实体数据:包括正常人、病例、地址、交通工具、医院等数据信息,以及各类实体之间的关联关系,如“病例乘坐某交通工具”关系。
数据导入后效果
导入数据详细介绍如下:
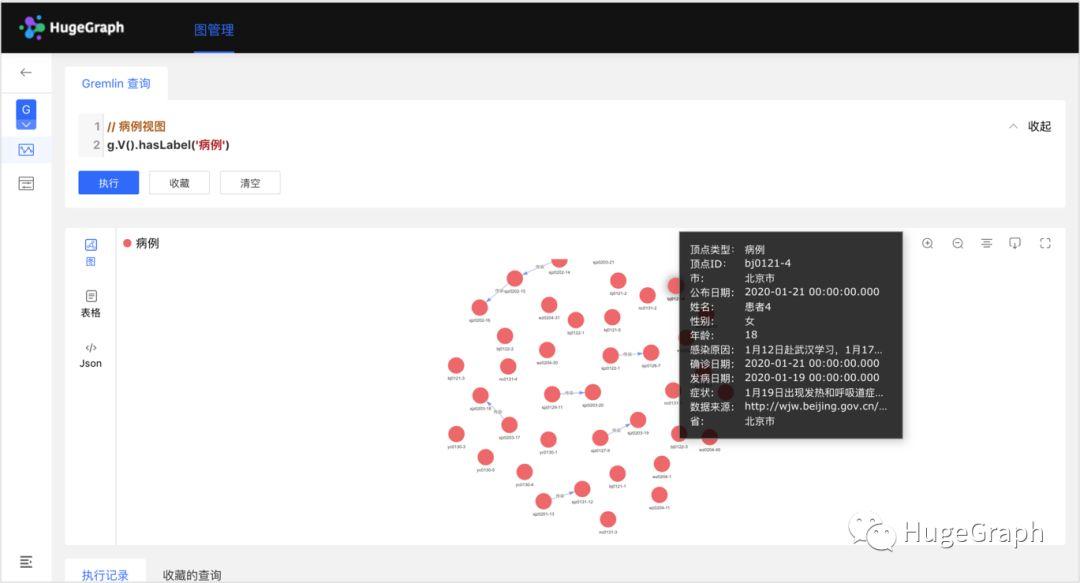
1、病例数据:共导入了43条病例数据,包括病例的年龄、性别、感染原因、症状、确诊日期、省市等信息。
2、地址数据:共导入了32条地址数据,比如“裕华区裕翔社区卫生服务中心”,主要包括上述病例出现过的地址。
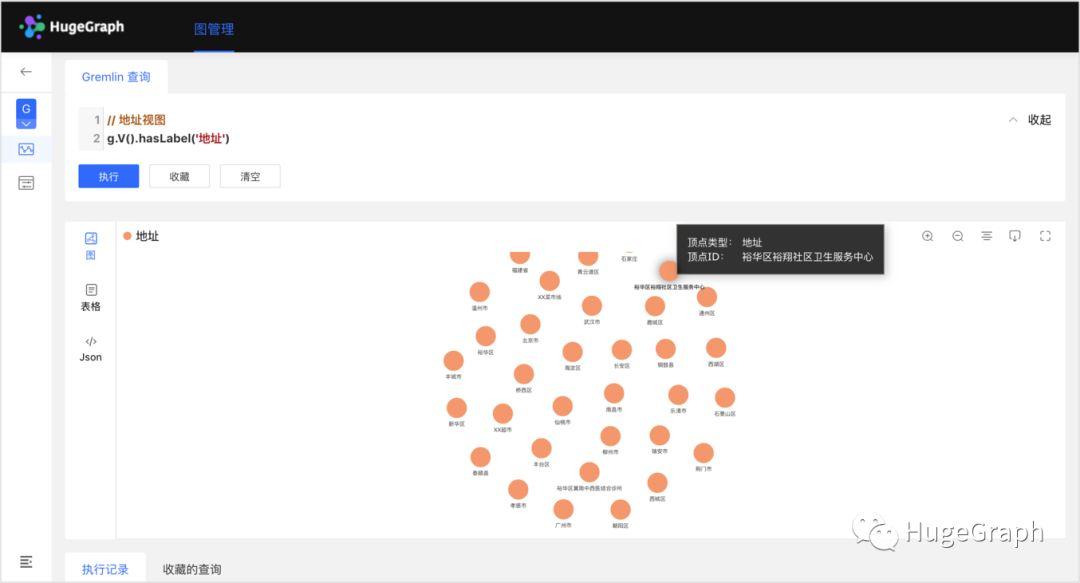
3、交通工具数据:共导入了6条交通工具数据,如高铁、航班、公交地铁等信息,主要包括上述病例乘坐过的交通工具。(这个数据较少省市公布)
4、医院数据:共导入了10条医院数据,如“北医科大学第四医院”,主要包括上述病例收治的医院。

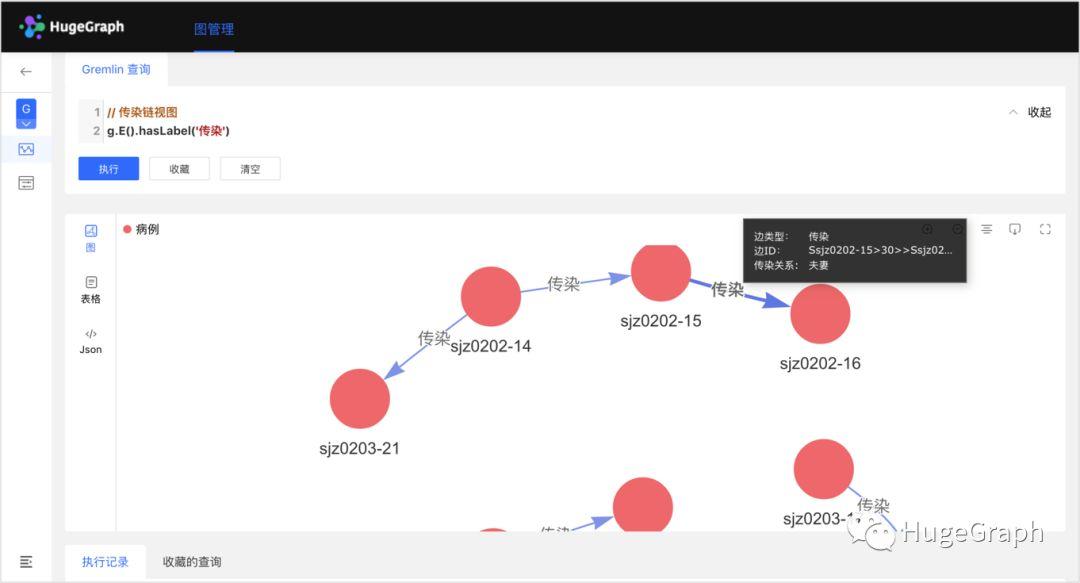
5、“传染链”视图:共导入了8条传染数据,如“病例甲传染了病例乙”,主要包括上述病例和疑似病例的传染关系。
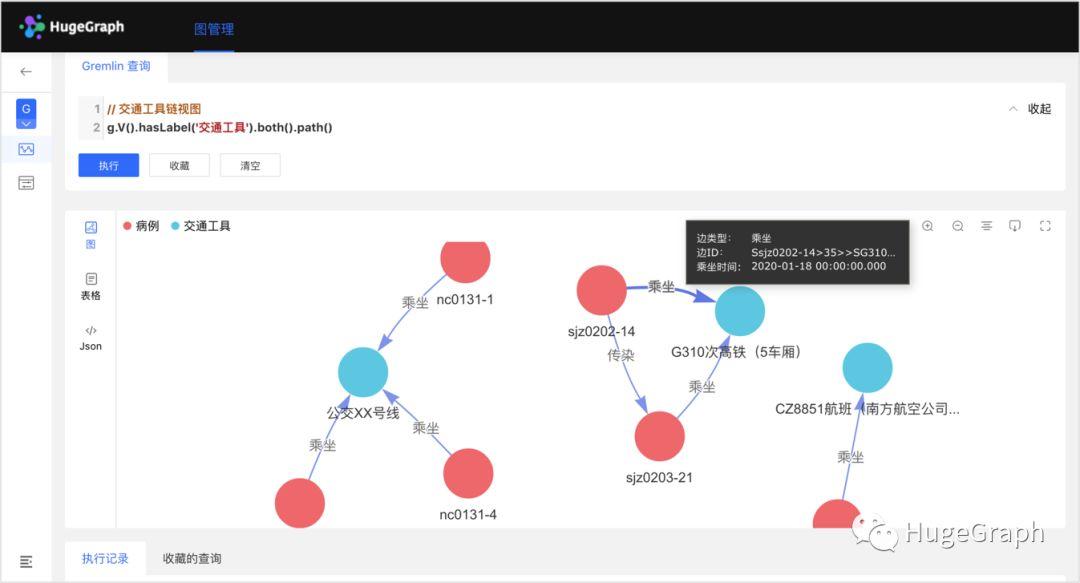
6、“交通工具链”视图:共导入了8条交通工具乘坐信息数据,比如“病例甲在1月18日乘坐了G310次高铁”,主要包括上述病例和疑似病例的乘坐关系。
7、“出现于场所”视图:共导入了9条病例、19条正常人出现的场所地址信息数据,比如“病例甲在1月21日10点到过XX超市”,主要包括上述病例和正常人的出现的地址关系。
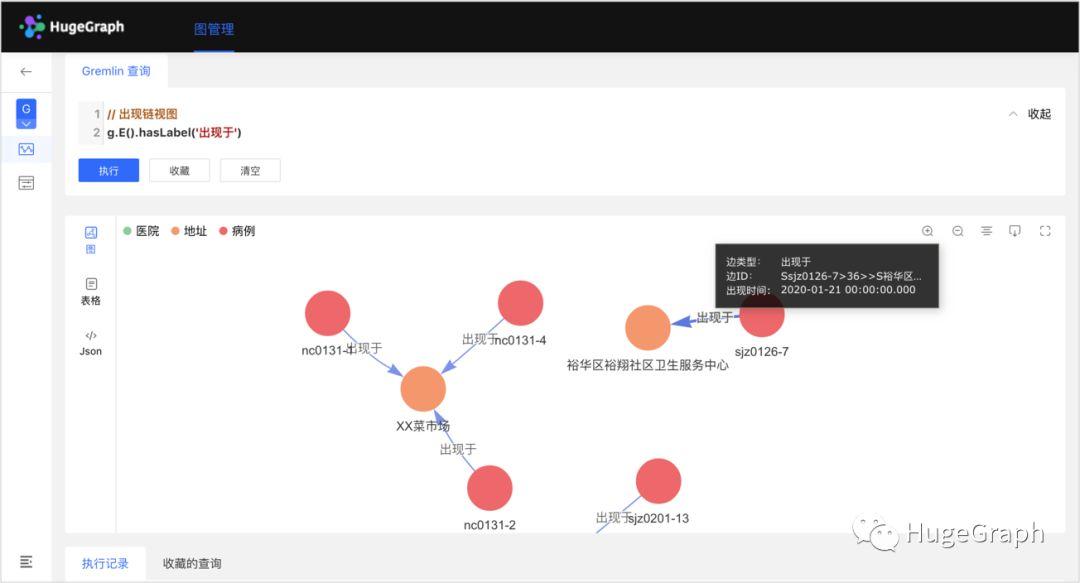
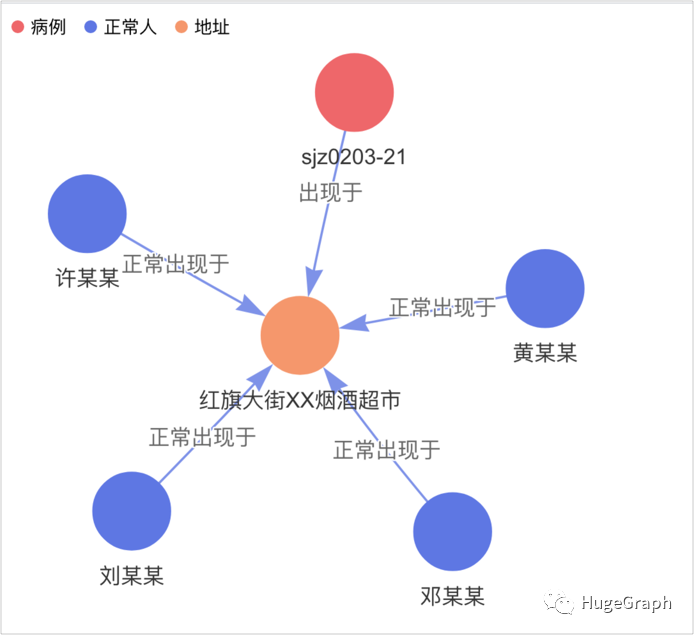
8、某个病例关系链视图:除上述关联关系外,还导入了“感染于”、“现住”、“常住”、“收治于”等关系,主要包括上述病例和疑似病例的各种其它关系。
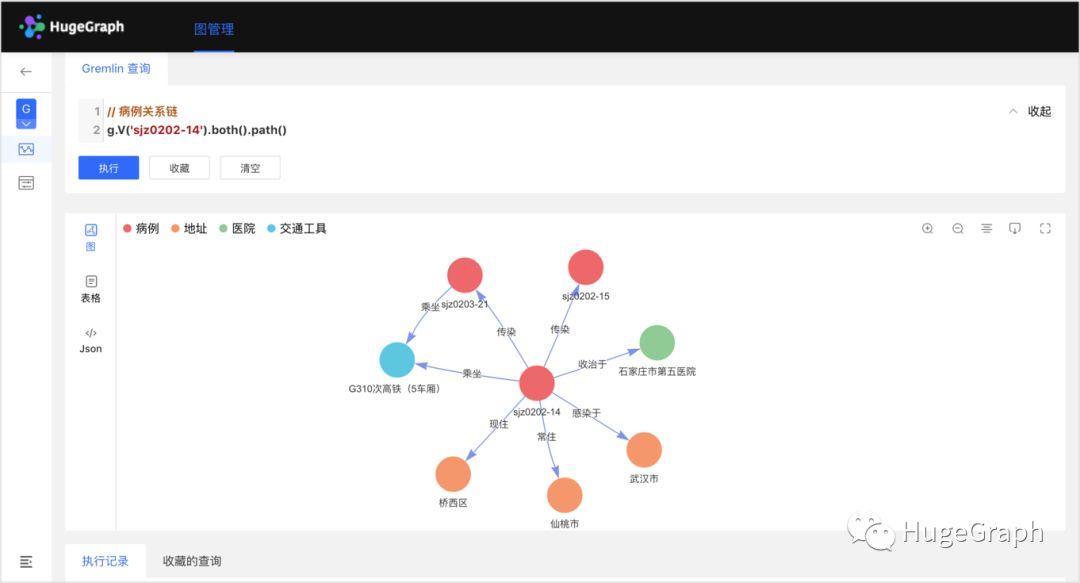
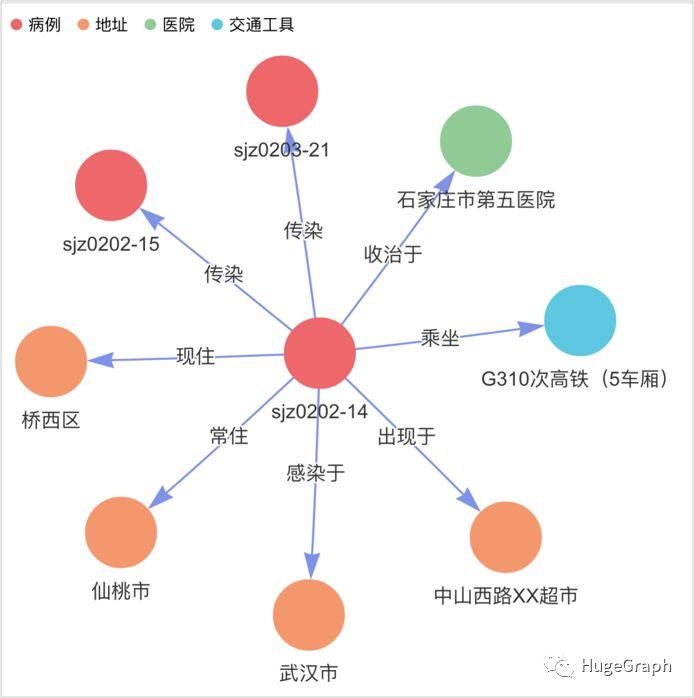
9、“正常人”数据:共导入了22条正常人数据,包括姓名、年龄、性别、详细地址等信息;另外还导入了28条正常人的轨迹信息,如“某个正常人在1月19日乘坐过G512次高铁”、“某个正常人在1月20日10点到过XX超市”。(注意:正常人数据并不准确,仅供演示参考)
到此,数据建模与导入介绍完毕。接下来基于此数据集进行各种分析场景的演示。
二、分析场景演示
场景1:基本统计信息
本场景中包含了7种基本的统计分析,分别是:分析确诊病例的城市分布情况、病例的省份分布情况、病例的确诊日期分布情况、病例的平均年龄、病例的年龄段分布情况等。(注意:这些统计信息仅仅是基于上述导入数据集计算的)
1、病例的城市分布情况
注:表格部分展示了分析结果,表格底部灰色部分展示了分析计算的查询语句,查询语句使用的是HugeGraph提供的标准Gremlin图查询语言,下同。
g.V().hasLabel('病例').groupCount().by('市')
.unfold().order().by(values,desc)2、病例的省份分布情况
g.V().hasLabel('病例').groupCount().by('省')
.unfold().order().by(values,desc)3、病例的确诊日期分布情况(Top3)
g.V().hasLabel('病例').groupCount().by('确诊日期')
.unfold().order().by(values,desc).limit(3)4、病例的平均年龄
g.V().hasLabel('病例').values('年龄').mean()5、病例的年龄段分布情况
g.V().hasLabel('病例')
.filter{it.get().property('年龄').isPresent()}
.groupCount().by(values('年龄')
.math('floor(_/10)*10')).unfold()
.order().by(values,desc)6、最容易的感染传染方式(Top3)
g.V().hasLabel('病例')
.filter{it.get().property('感染原因').isPresent()}
.groupCount().by('感染原因').unfold()
.order().by(values,desc).limit(4)7、家人亲密接触方式感染的传染关系分布情况
g.E().hasLabel('传染').groupCount().by('传染关系')
.unfold().order().by(values,desc)场景2:与确诊病例直接接触过的人(1层关系)
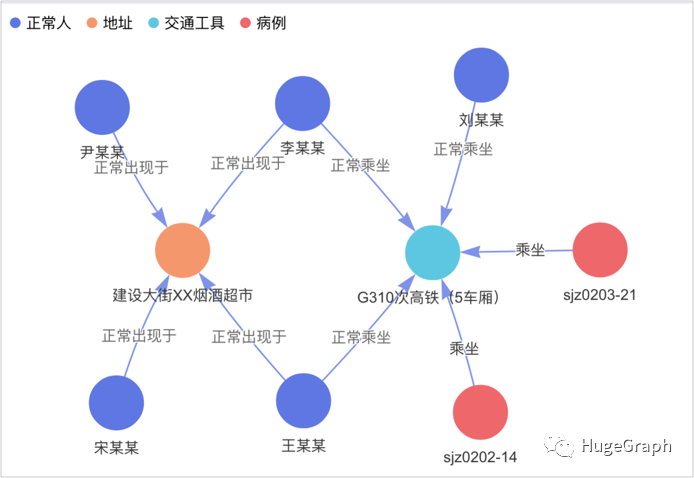
下图中的3个红色点代表已确诊病例,深蓝色点代表正常人,这些人与病例有过接触,有感染风险:
场景2:与病例直接接触过的人
查询语句:
g.V().hasLabel('病例')
.union(out('乘坐').in('正常乘坐').simplePath(),
out('出现于').in('正常出现于').simplePath())
.hasLabel('正常人').path()注:查询语句使用的是HugeGraph提供的标准Gremlin图查询语言,下同。
场景3:与确诊病例间接接触过的人(2层关系)
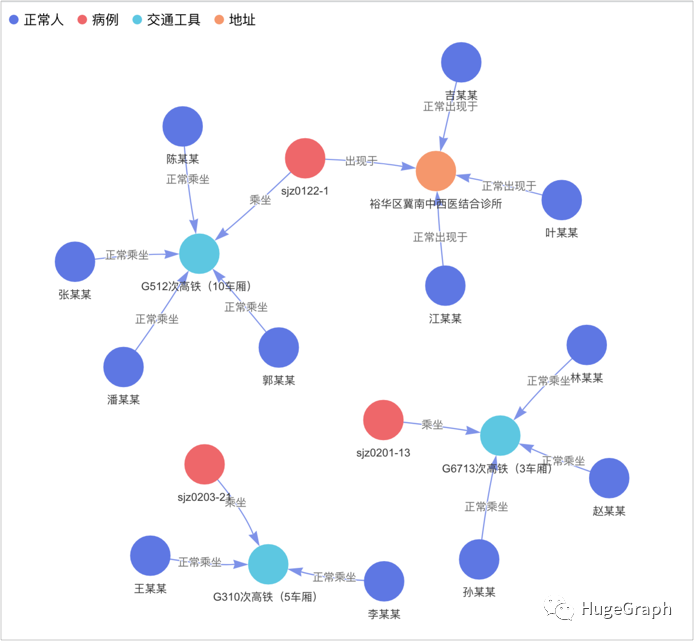
下图中的左上角红色点代表已确诊病例,深蓝色点代表正常人,这些正常人与病例有过直接接触(如田某某),或者间接接触(其它蓝色点,如李某某与田某某在建设大街XX烟酒超市接触过),均有感染风险:
场景3:与病例间接接触过的人
查询语句:
g.V().hasLabel('病例')
.union(out('乘坐').in('正常乘坐').simplePath().out('正常乘坐').in('正常乘坐').simplePath(),
out('出现于').in('正常出现于').simplePath().out('正常出现于').in('正常出现于').simplePath())
.hasLabel('正常人').path()
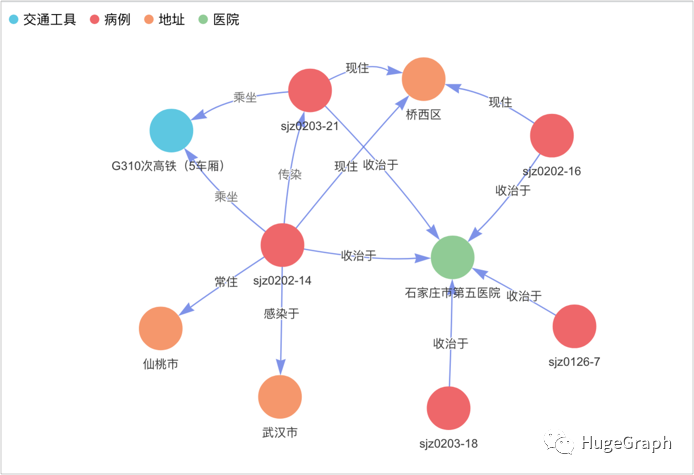
场景4:某个正常人是否与确诊病例直接或间接接触过
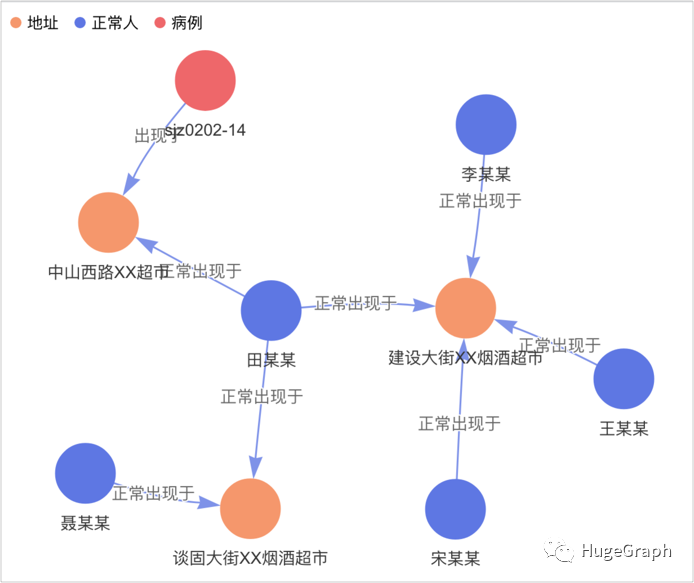
换一个角度,以正常人为中心来考虑并进行分析。下图中的左上角蓝色点是一个正常人“黄某某”,查看他是否有直接或间接和红色点所代表的已确诊病例关系,从图中可以看出,他与病例“sjz0203-21”有直接接触,且与病例“sjz0202-14”有间接接触。
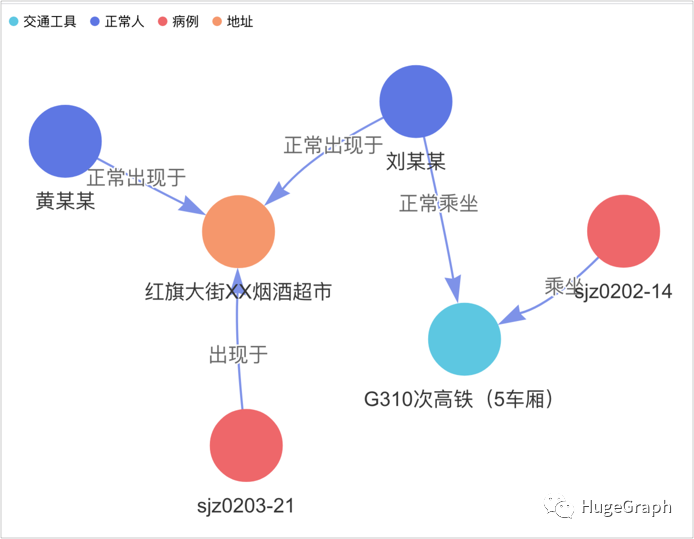
场景4:某个正常人是否与病例有接触
查询语句:
g.V('黄某某').repeat(out('正常乘坐','正常出现于')
.in('正常乘坐','正常出现于','乘坐','出现于').simplePath())
.times(2).emit(hasLabel('病例'))
.hasLabel('病例').path()场景5:找出所有的超级传播者
我们要从所有的病例里面找到超级传播者,这里假设一个病例若传染了5个以上的人则定义为超级传播者,下图中心的红色点“sjz0202-14”病例即是找出来的超级传播者(传染了“sjz0202-15”和“sjz0203-21”等5个人)。
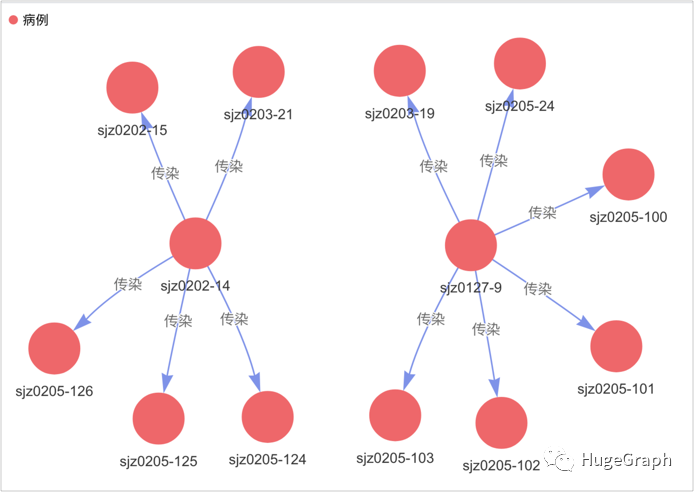
场景5:找出超级传播者
查询语句:
g.V().hasLabel('病例').where(outE('传染').count().is(gte(5)))
.order().by(outE('传染').count(),desc).limit(10)场景6:找出超级传播者接触过的人(包括已确诊病例和正常人)
一般来说,超级传播者的风险比较高,与超级传播者接触过的人风险也是比较高的,下图展示了如何找到这些高风险的人:中心的红色点是超级传播者,周围的红色点和蓝色点所代表的人是高风险的人。
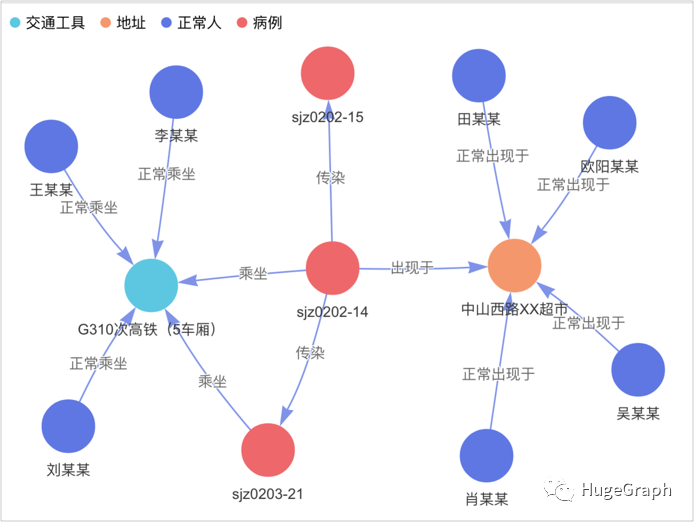
场景6:超级传播者接触过的人
查询语句:
g.V().hasLabel('病例').where(outE('传染').count().is(gte(5)))
.order().by(outE('传染').count(),desc).limit(10)
.both().choose(hasLabel('病例'),identity(),both('乘坐','出现于','正常乘坐','正常出现于').simplePath())
.path()场景7:病例传染链分析(如疫情后病毒变异分析)
为了在疫情后进行病毒变异分析,需要分析一个病例的上游传染链,即某病例是被谁传染的,上一个人又是被谁传染的,找到直到源头,形成一条传染链。有了传染链之后可以对链上的每个病例的病毒信息进行比对分析(假设每条病例数据里面存储了病毒的身份签名信息)。下图展示了最左边的病例“sjz0205-123”的传染链,传染源头则是最右边的病例“sjz0127-9”。
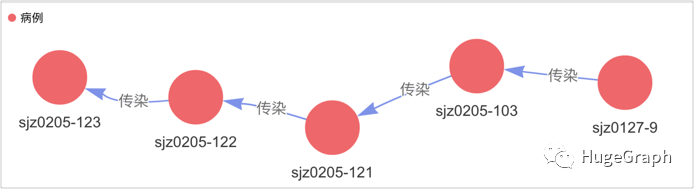
场景7-1:病例的传染链
查询语句:
g.V('sjz0205-123').repeat(__.in('传染'))
.until(__.not(__.in('传染'))).path()下一步计算链上的病毒变异次数,也就是比对链上病例的病毒签名,计算去重之后病毒的种类数量。如下图示例中的结果是变异3次。
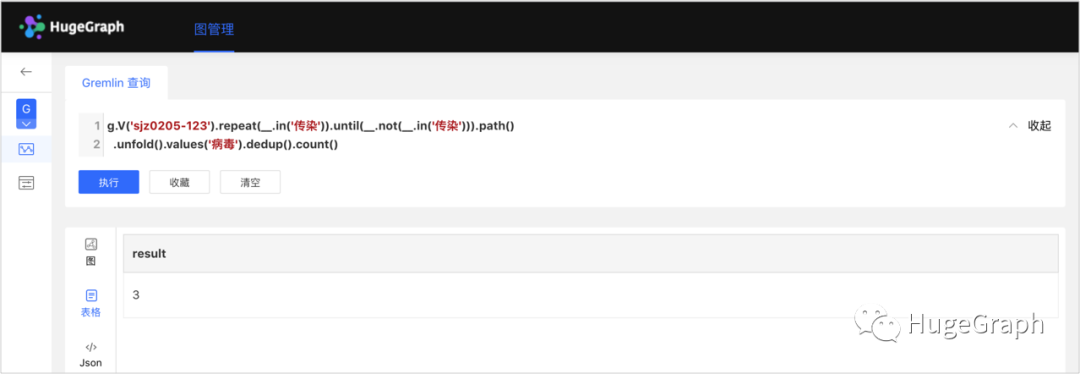
场景7-2:传染链的病毒变异次数
查询语句:
g.V('sjz0205-123').repeat(__.in('传染'))
.until(__.not(__.in('传染'))).path()
.unfold().values('病毒').dedup().count()每个病例都有一条传染链,为了分析所有病例的传染链的病毒变异情况,比如找出变异次数最多的那条链,那么需要先找到所有的传染链,然后计算每条链的变异次数,最后比较各条链,找出变异次数最多的一条链。下图展示了所有的传染链。
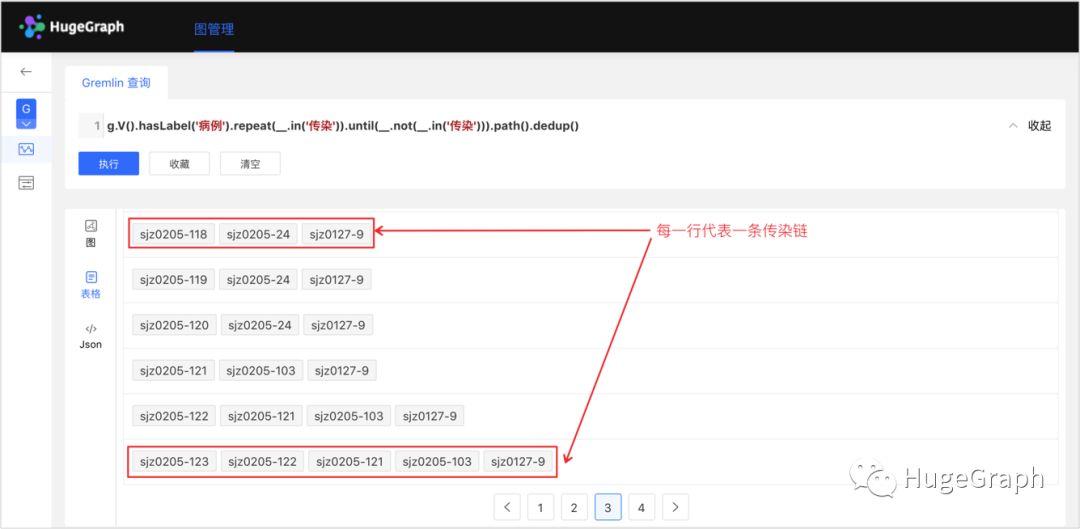
场景7-3:找出所有传染链
查询语句:
g.V().hasLabel('病例').repeat(__.in('传染'))
.until(__.not(__.in('传染'))).path().dedup()下图展示了所有传染链的病毒变异次数。
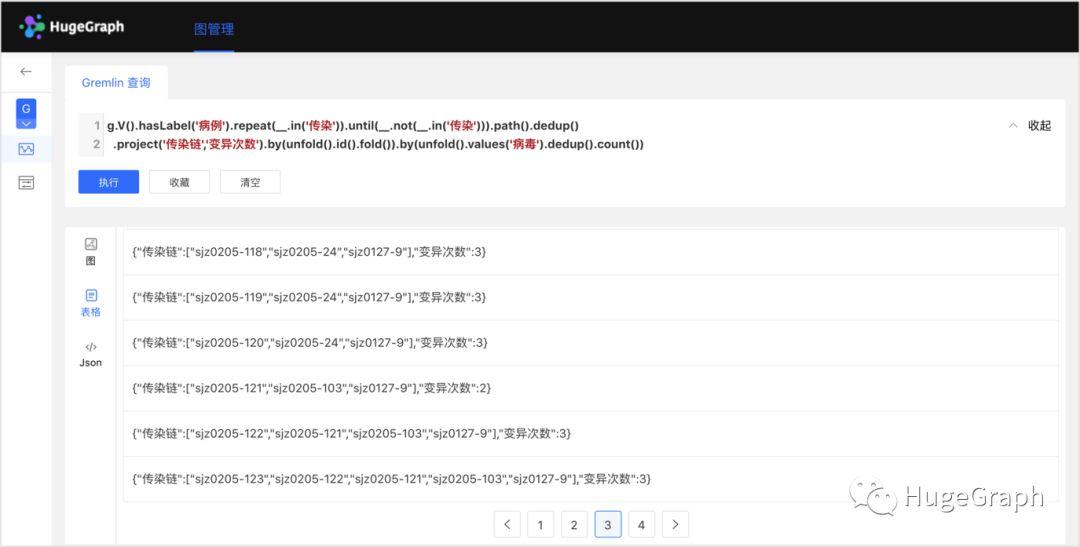
场景7-4:找出所有传染链的病毒变异次数
查询语句:
g.V().hasLabel('病例').repeat(__.in('传染')).until(__.not(__.in('传染'))).path().dedup()
.project('传染链','变异次数').by(unfold().id().fold()).by(unfold().values('病毒').dedup().count())场景8:病例传染环分析
在疫情早中期,对于某个病例来说,随着病毒传染更多的人,往往会在该病例的周围形成一圈一圈的传染环,比如某病例传染了3个人,假设被传染的人又每个传染3人,则第一层环上包括3人,第二层环上包含9人。为了分析某一层环上病例的病毒变异情况,需要找到该层环上的病例,然后对环上的每个病例的病毒信息进行比对分析。下图展示了病例“sjz0127-9”的第一层和第二层传染环。
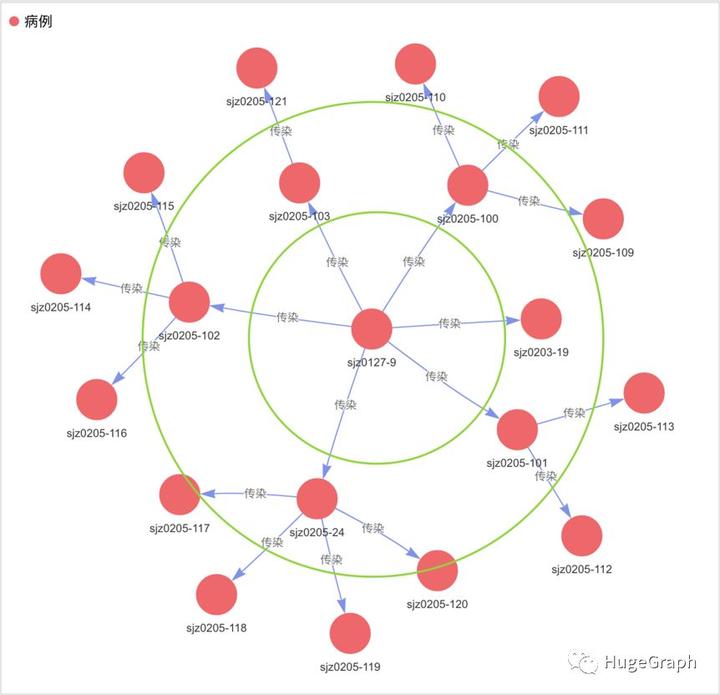
场景8:病例的传染环
查询语句:
g.V('sjz0127-9').repeat(out('传染')).times(2).emit().path()