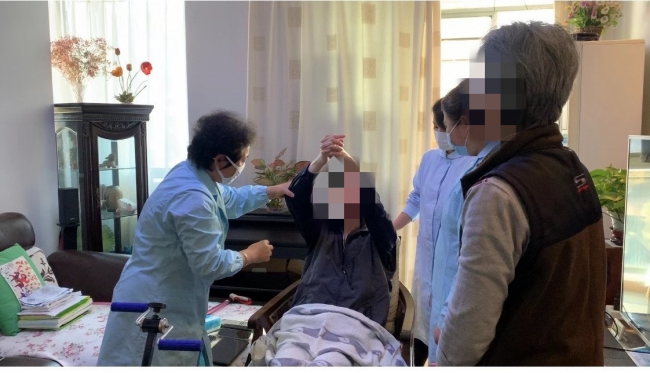
IT之家 12 月 28 日消息,蚂蚁集团今日宣布开源首个医疗专科推理数据集。该数据集由训练、验证、测试三部分组成,包含 2132 个问答对,每个问答对由医生根据临床经验编写的问题、专家提供的回答以及用于帮助推理的上下文构成,病种覆盖了 97.6% 以上的泌尿科就医人群,号称能“真实复刻诊疗场景”。
在医疗行业,通用型语言模型在应对医疗问诊时,会直接给出答案,而医生则会根据专业知识进行反复的症状探讨,才能给出答案。此外,大模型的幻觉问题和推理能力不足,当前高质量的中文医学专科数据集又较为稀缺,这对训练出色的医疗领域大模型提出了挑战。
据介绍,为克服这些难题,蚂蚁集团与上海仁济医院泌尿科专家团队联合研发,基于医生团队临床经验,通过构造模拟病例数据的方式,推出了中文医疗专科问答推理数据集 RJUA-QA,这也是业内首个临床专科数据集。
专业性上,由于医疗行业有超百个科室,每个专科和疾病,都需要专业的调试。蚂蚁集团联合医疗专家共同研发了多模态医疗知识引擎,进一步推动中国专业医疗数据集的构建与开放。
IT之家查询发现,RJUA-QA 已在 GitHub 上开源,README 页面显示“本数据集的病例数据由专业医生的根据临床经验编写而成,因此不涉及任何医患个人隐私”。
广告声明:文内含有的对外跳转链接(包括不限于超链接、二维码、口令等形式),用于传递更多信息,节省甄选时间,结果仅供参考,IT之家所有文章均包含本声明。


![[科普中国]-春季大白菜苗期管理](https://www.aipiwu.com/uploads/20240314/1710388371398_0.png)