大数据和Hadoop平台介绍定义
大数据是指其大小和复杂性无法通过现有常用的工具软件,以合理的成本,在可接受的时限内对其进行捕获、管理和处理的数据集。这些困难包括数据的收入、存储、搜索、共享、分析和可视化。大数据要满足三个基本特征(3V),数据量(volume)、数据多样性(variety)和高速(velocity)。数据量指大数据要处理的数据量一般达到TB甚至PB级别。数据多样性指处理的数据包括结构化数据、非结构化数据(视频、音频、网页)和半结构化数据(xml、html)。高速指大数据必须能够快速流入并且能得到快速处理。
大数据发展背景
数据爆炸。伴随信息技术的应用,全球数据量呈几何级数增长。过去几年间的数据总量超过了人类历史上的数据总和。芯片、摄像头、各自传感器遍布世界各个角落,原本不能被感知的事物都可以被监测。软硬件技术的不断进步,也为处理大数据创造的条件。
大数据的应用领域 大数据研究课题 数据获取问题。包括哪些数据需要保存,哪些数据需要丢弃,如何可靠的存储我们需要的数据。数据结构问题。微博博客是没有结构的数据,图像和视频在存储和显示方面具有结构,但是无法包含语义信息进行检索。如果将没有语义的内容转换为结构化的格式,并进行后续处理,是需要面对的另一项挑战。数据集成问题。不同来源数据之间进行关联,才能充分发挥数据的作用。数据分析、组织、抽取和建模如何呈现分析结果科技公司大数据产品 大数据发展趋势 大数据处理一般步骤 数据的收集。第一个方式是抓取或者爬取。例如搜索引擎就是这么做的:它把网上的所有的信息都下载到它的数据中心,然后你一搜才能搜出来。第二个方式是推送,有很多终端可以帮我收集数据。比如说小米手环,可以将你每天跑步的数据,心跳的数据,睡眠的数据都上传到数据中心里面。数据的传输一般会通过队列方式进行,因为数据量实在是太大了,数据必须经过处理才会有用。可系统处理不过来,只好排好队,慢慢处理。数据的存储存储要确保安全,不易丢失,高容错性。数据的处理和分析存储的数据是原始数据,原始数据多是杂乱无章的,有很多垃圾数据在里面,因而需要清洗和过滤,得到一些高质量的数据。对于高质量的数据,就可以进行分析,从而对数据进行分类,或者发现数据之间的相互关系,得到知识。数据的检索和挖掘使想要的信息容易被搜索到。挖掘信息之间的相互关系。开源框架
因为大数据的这些特点,针对其收集、传输、存储、处理分析和检索使用产生了许多开源框架。
功能
框架
文件存储
Hadoop HDFS、Tachyon、KFS
离线计算
Hadoop MapReduce、Spark
流式、实时计算
Storm、Spark Streaming、S4、Heron
K-V、NOSQL数据库
HBase、Redis、MongoDB
资源管理
YARN、Mesos
日志收集
Flume、Scribe、Logstash、Kibana
消息系统
Kafka、StormMQ、ZeroMQ、RabbitMQ
查询分析
Hive、Impala、Pig、Presto、Phoenix、SparkSQL、Drill、Flink、Kylin、Druid
分布式协调服务
Zookeeper
集群管理与监控
Ambari、Ganglia、Nagios、Cloudera Manager
数据挖掘、机器学习
Mahout、Spark MLLib
数据同步
Sqoop
任务调度
Oozie
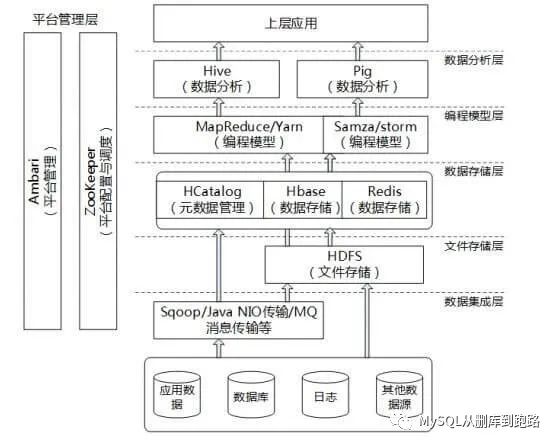
一般大数据平台的框架如下图
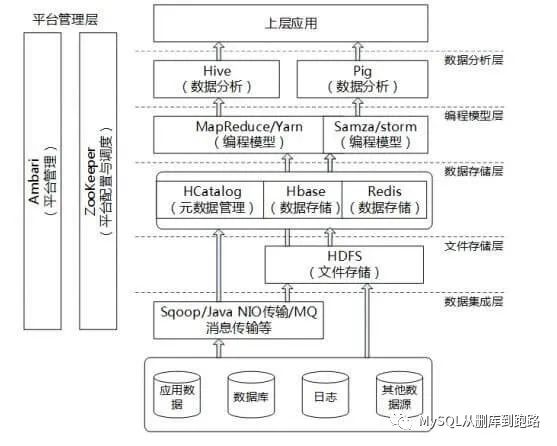
Hadoop HDFS和Hadoop MapReduce作为大数据存储和处理的开山鼻祖,大数据平台上都处于核心位置。下面介绍一下两个框架的基本原理。
Hadoop HDFS基本原理
HDFS全称Hadoop Distributed File System。HDFS是一个分布式文件系统,可以部署在一个服务器集群上。Java语言开发,可以部署在任何支撑java的机器上。HDFS有几个基本概念NameNode、DataNode和block。NameNode负责整个分布式文件系统的元数据管理,也就是文件路径名,数据block的ID以及存储位置等信息。还要记录一些事情,比如哪些节点是集群的一部分,某个block有几份副本等。
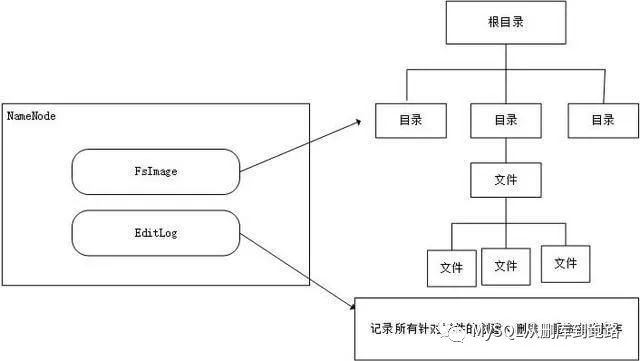
DataNode是实际存储文件数据的节点。DataNode会通过心跳和NameNode保持通信,如果DataNode超时未发送心跳,NameNode就会认为这个DataNode已经失效,立即查找这个DataNode上存储的block有哪些,以及这些block还存储在哪些服务器上,随后通知这些服务器再复制一份block到其他服务器上,保证HDFS存储的block备份数符合用户设置的数目,即使再有服务器宕机,也不会丢失数据。
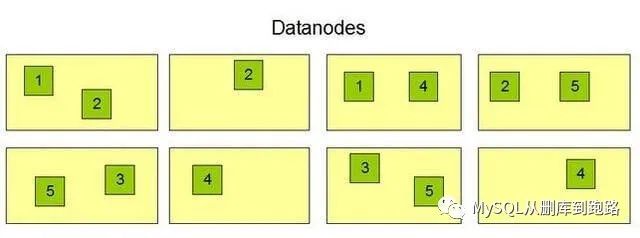
Block是HDFS中的存储单元,文件被写入HDFS时,会被切分成多个block块,默认的块大小是128MB,每个数据块默认会有三个副本。
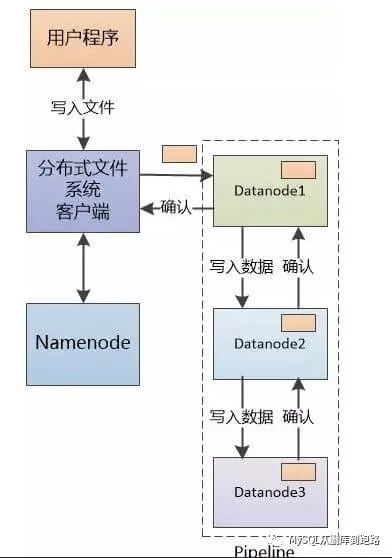
数据写入:首先将文件分成多个block,每个block会被写入三个DataNode中,写入哪三个DataNode中是由NameNode指定的,写入完成,NameNode会记录这些信息。同一个文件中不同的block可能会被写入完全不同的DataNode中。
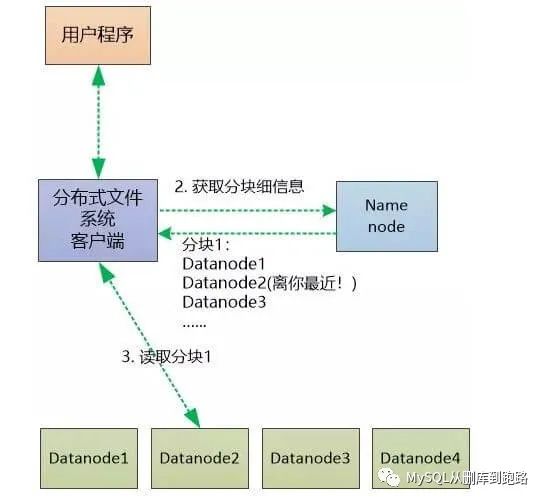
数据读取:数据读取时按block读取。每一个block时,会从NameNode获取信息,知道从哪个DataNode中读取,一般是就近原则。所有该文件的block读取完成,构成完整的文件。客户端和Datanode是同一个机器:距离为0 ,表示最近客户端和Datanode是同一个机架的不同机器 :距离为2 ,稍微远一点客户端和Datanode位于同一个数据中心的不同机架上 :距离为4,更远一点
Hadoop MapReduce基本原理
Hadoop MapReduce是一个分布式计算框架,其中的运算都可以在多个机器上并行进行。使用者只需要完成运算本身的编码,不需要关心并行计算的底层细节。MapReduce背后的思想很简单,就是把一些数据通过Map来归类,通过Reduce来把同一类的数据进行处理。Map和reduce的过程都是利用集群的计算能力并行执行的。计算模型的核心是Map和Reduce函数,两个函数由用户自行实现。

把原始大数据集切割成小数据集时,通常小数据集小于等于HDFS的一个block的大小,这样一个小数据集位于一个物理机上,便于本地计算。Map和reduce各自的启动任务数量可以由用户指定。
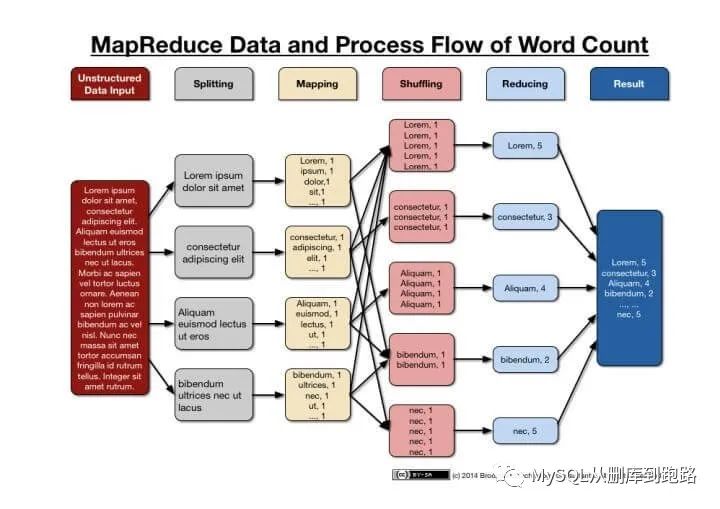
上图表示一个MapReduce统计单词出现次数的过程,原始数据分割为4个子文件,对每个子文件按照用户的Map函数会产生的形式的结果。然后把相同单词的组合在一起构成的形式,作为Reduce函数的输入,相同的k2一定分发给相同的Reduce任务处理,例如单词lorem的所有计算都由第一个Reduce任务来完成。按照这个思想,即使要统计的文件数量上千万个,单词数量有几千个,但是通过MapReduce框架,只要集群机器数量够多,也是可以在可接受时间内计算完成的。
大数据行业应用 推广使用面临的挑战