1 什么是池化
pooling,小名池化,思想来自于视觉机制,是对信息进行抽象的过程。

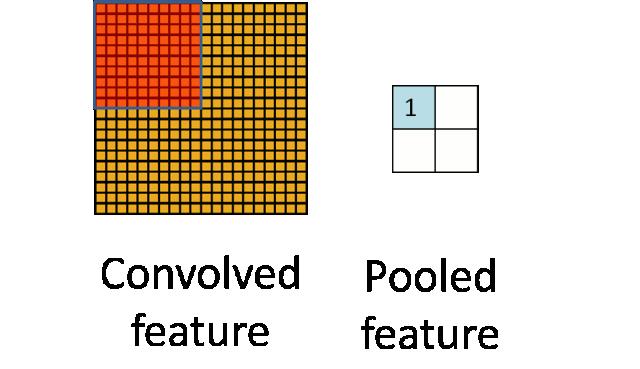
上图就是一个池化的示意图,用了一个10*10的卷积核,对20*20的图像分块不重叠的进行了池化,池化之后featuremap为2*2的大小。
pooling有什么用呢?或者说为什么需要pooling呢?原因有几个:
1、增大感受野
所谓感受野,即一个像素对应回原图的区域大小,假如没有pooling,一个3*3,步长为1的卷积,那么输出的一个像素的感受野就是3*3的区域,再加一个stride=1的3*3卷积,则感受野为5*5。
假如我们在每一个卷积中间加上3*3的pooling呢?很明显感受野迅速增大,这就是pooling的一大用处。感受野的增加对于模型的能力的提升是必要的,正所谓“一叶障目则不见泰山也”。
2、平移不变性
我们希望目标的些许位置的移动,能得到相同的结果。因为pooling不断地抽象了区域的特征而不关心位置,所以pooling一定程度上增加了平移不变性。
3、降低优化难度和参数
我们可以用步长大于1的卷积来替代池化,但是池化每个特征通道单独做降采样,与基于卷积的降采样相比,不需要参数,更容易优化。全局池化更是可以大大降低模型的参数量和优化工作量。
2 池化有哪些
1、平均池化和最大池化


这是我们最熟悉的,通常认为如果选取区域均值(mean pooling),往往能保留整体数据的特征,较好的突出背景信息;如果选取区域最大值(max pooling),则能更好保留纹理特征。
2、stochastic pooling/mixed pooling
stochastic pooling对feature map中的元素按照其概率值大小随机选择,元素被选中的概率与其数值大小正相关,这就是一种正则化的操作了。mixed pooling就是在max/average pooling中进行随机选择。
3、Data Driven/Detail-Preserving Pooling
上面的这些方法都是手动设计,而现在深度学习各个领域其实都是往自动化的方向发展。
我们前面也说过,从激活函数到归一化都开始研究数据驱动的方案,池化也是如此,每一张图片都可以学习到最适合自己的池化方式。
此外还有一些变种如weighted max pooling,Lp pooling,generalization max pooling就不再提了,还有global pooling。
完整解读可移步:龙鹏:【AI初识境】被Hinton,DeepMind和斯坦福嫌弃的池化(pooling),到底是什么?