
日报合辑 | 电子月刊 | 公众号下载资料 | @韩信子
工具&框架 『MedPerf』医疗AI平台
Medperf 是一个使用 Federated Evaluation 的医学人工智能开放基准平台。使医疗机构能够在一个高效和人工监督的过程中评估和验证人工智能模型的性能,而在这个过程中不需要在各机构之间共享任何病人数据。它减少了与数据共享相关的风险和成本,以实现医疗和患者结果的最大化。
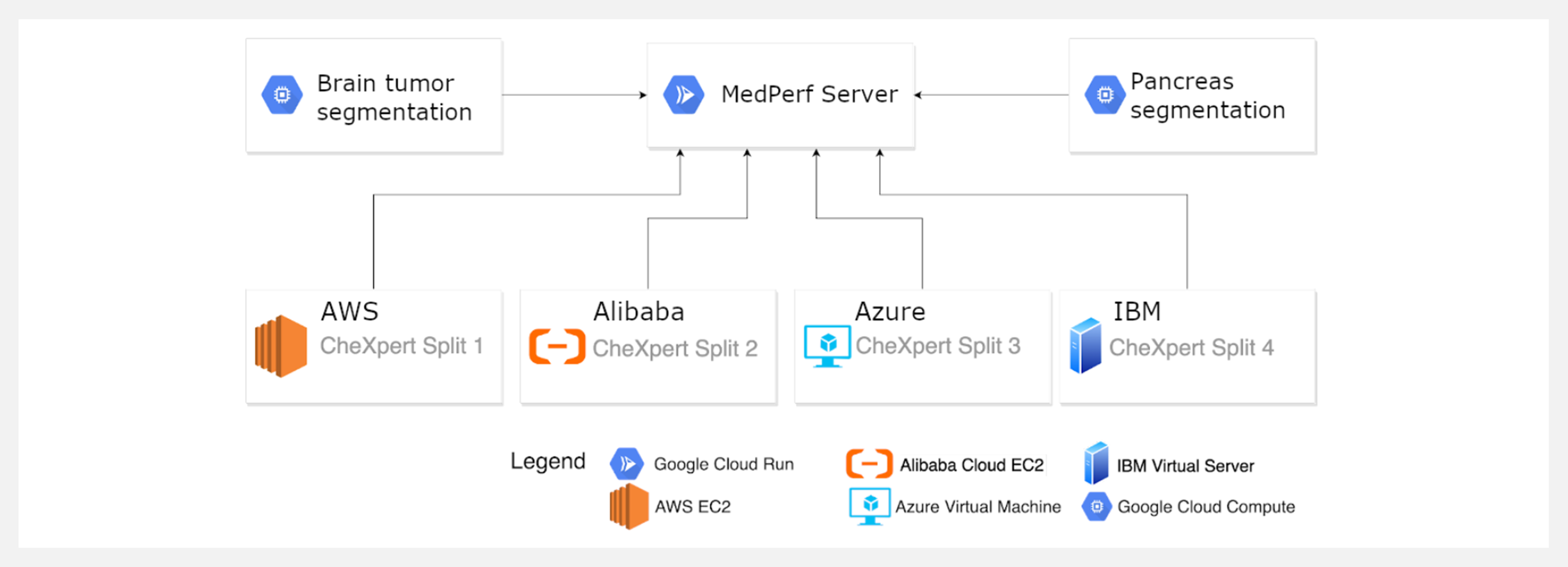
MedPerf 提供了你需要参与的端到端工具链:从组织实验,到执行实验,再到产生结果。我们提供数据库存储、REST API、研究人员使用的工具,以便将算法与任何数据打包运行,以及临床医生的工具,以便在病人数据不带出的前提下轻松运行算法。
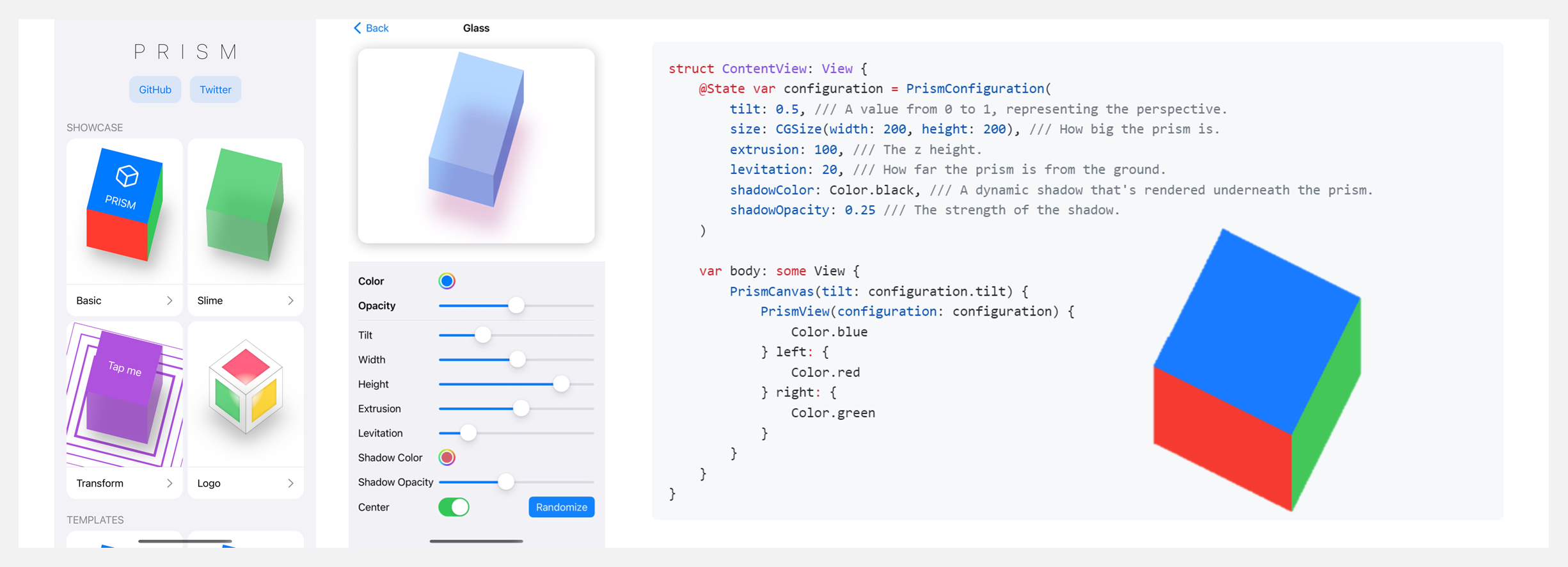
『Prism』3D渲染器
Prism 是一个用于 SwiftUI 的轻量级 3D 渲染器,具备以下特性:

『MegaMolBART』基于SMILES的小分子药物发现和化学信息学的深度学习模型
MegaMolBART 是一个基于 SMILES 的小分子药物发现和化学信息学的深度学习模型。MegaMolBART 使用英伟达的 NeMo-Megatron 框架,该框架是为开发大型 transformer 模型而设计的。
MegaMolBART 依赖 NeMo。NeMo 为开发、训练和部署深度学习模型提供了一个强大的环境。N
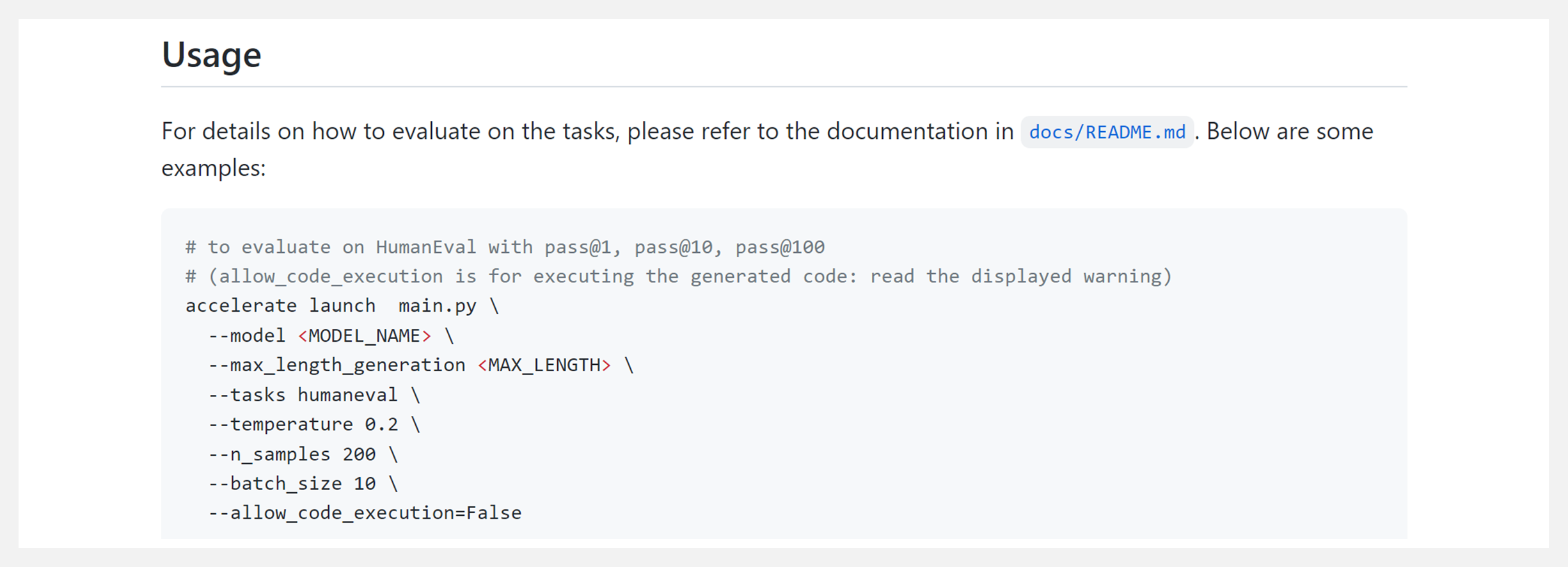
『Code Generation LM Evaluation Harness』代码生成语言模型评估工具
这是一个评估自回归代码生成语言模型的框架,是 BigCode 项目的一个正在进行的部分。框架具有下述特性:
『TorchEx』Pytorch 自定义算子
TorchEx 包含用于个人项目的 PyTorch 自定义算子 operator 集合,支持以下 operator 的 GPU 计算:
博文&分享 『AI Research Experiences - Learn to do applied deep learning research』Harvard哈佛 CS197 · AI研究经验课程
在本课程中,您将学习应用深度学习工作所需的实践技能,包括模型开发的实践经验。您将学习应用 AI 研究所需的技术写作技巧,包括撰写完整研究论文的不同元素的经验。

『Model Predictive Control and Reinforcement Learning』弗莱堡大学·模型预测控制与强化学习课程
为期8天的课程,面向工程、计算机科学、数学、物理学和其他数学科学领域的硕士和博士生,目的是让参与者了解模型预测控制 (MPC) 和强化学习 (RL) 的主要概念以及这两种方法之间的异同。在动手练习和项目工作中,他们学习将这些方法应用于科学和工程中的实际最优控制问题。


『Mathematics for Computer Science』MIT麻省理工 6.042J · 计算机科学的数学基础课程
MIT 6.042J 是顶级院校麻省理工出品的工科基础优质课程,围绕计算机科学方向,构建所需的数学体系内容,包含函数、离散数学、概率论、图和树结构,以及部分算法(例PageRank)。不同于枯燥的理论数学,本课程的数学知识都有计算机科学方向的延展应用,是工科方向同学值得一学的基础课程。

课程覆盖范围分为三部分:数学的基本概念、离散结构、离散概率理论。学完6.042J后,你能够解释和应用计算机科学中离散(非连续)数学的基本方法,并在算法设计和分析、可计算理论、软件工程、计算机系统等领域得到充分应用。

ShowMeAI 对课程资料进行了梳理,整理成这份完备且清晰的资料包(点击 这里 获取这份资料包):
『Deep Learning: Designing, Visualizing and Understanding Deep Neural Networks』Berkeley伯克利 CSW182 · 深度神经网络设计、可视化与理解课程
CSW182/282A 是全球顶校 UC Berkeley 开设的 AI 专项课程,课程以深度学习的典型方法、模型设计、可视化与模型理解为主题,讲解了自然语言处理、计算机视觉、强化学习等领域的AI模型全域知识。学生将学习设计原则和最佳实践,可视化与理解深度网络。并通过可视化工具探索深度网络的训练和使用方法。


CSW182 课程由深度学习核心内容讲解、4次编程作业、2次期中测试和1个大项目构成,并公开了相关资料。ShowMeAI 对课程资料进行了梳理,整理成这份完备且清晰的资料包(点击 这里 获取这份资料包):
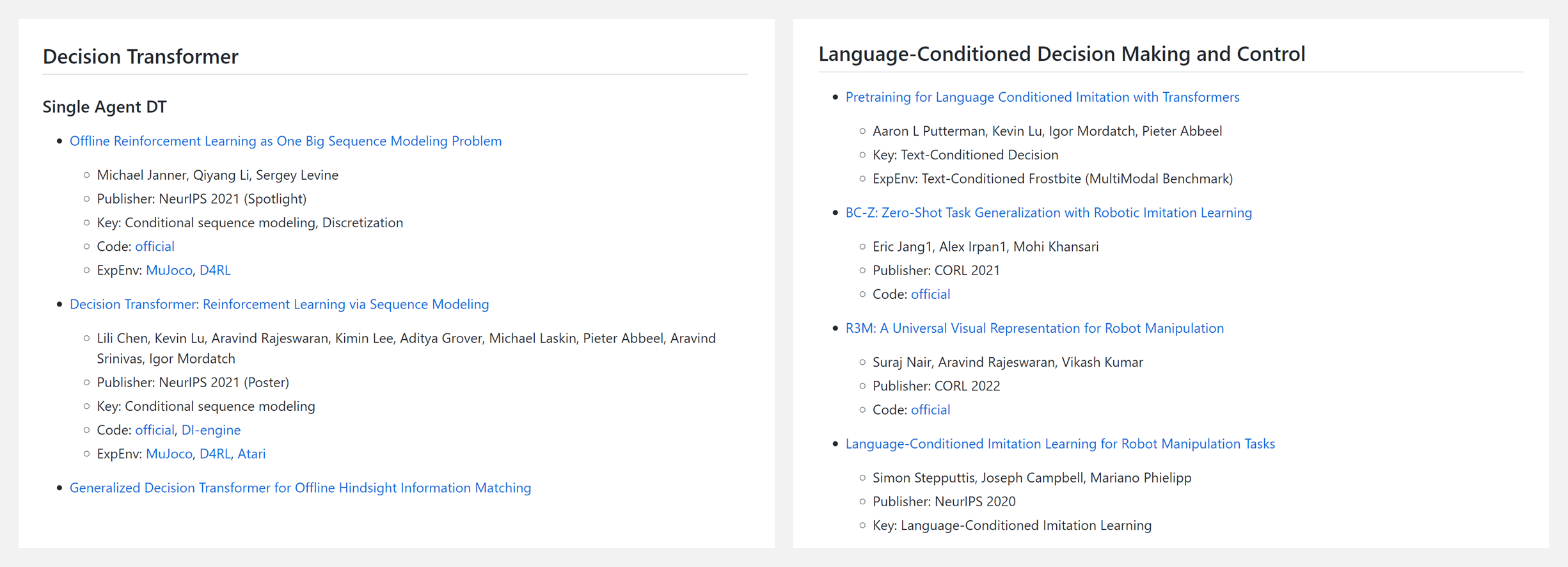
数据&资源 『Pretrained Model for Decision Making and Control』面向决策和控制的预训练模型相关文献列表
Transformer as a world model(Transformer 模型)Language-Conditioned Decision Making and Control(语言条件的决策和控制)Direct Language Planning via Pretrained Language Model(通过预训练语言模型直接进行语言规划)
研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
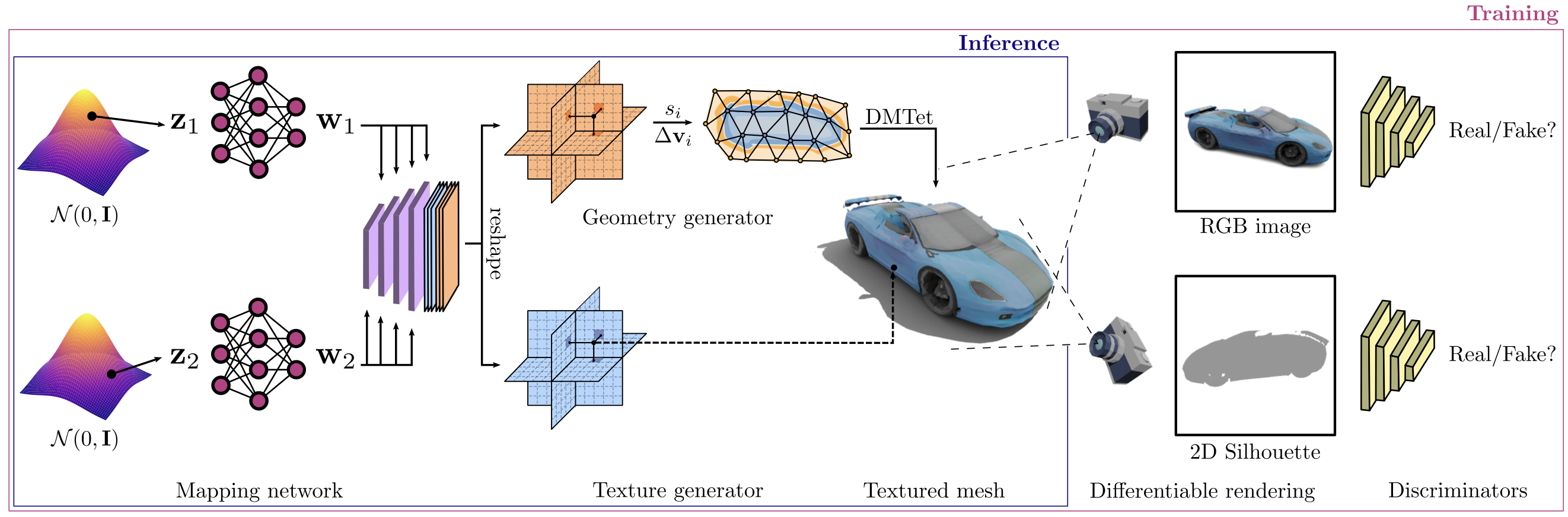
⚡ 论文:GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images
论文时间:22 Sep 2022
领域任务:计算机视觉
论文地址:
代码实现:
论文作者:Jun Gao, Tianchang Shen, Zian Wang, Wenzheng Chen, Kangxue Yin, Daiqing Li, Or Litany, Zan Gojcic, Sanja Fidler
论文简介:As several industries are moving towards modeling massive 3D virtual worlds, the need for content creation tools that can scale in terms of the quantity, quality, and diversity of 3D content is becoming evident./随着一些行业正朝着大规模3D虚拟世界建模的方向发展,对能够在3D内容的数量、质量和多样性方面进行扩展的内容创建工具的需求变得很明显。
论文摘要:随着一些行业正朝着建立大规模3D虚拟世界的方向发展,对能够在3D内容的数量、质量和多样性方面进行扩展的内容创建工具的需求也变得很明显。在我们的工作中,我们的目标是训练高性能的三维生成模型,合成可直接被三维渲染引擎使用的纹理网格,从而立即可用于下游的应用中。之前的三维生成模型工作要么缺乏几何细节,要么在它们能够产生的网格拓扑结构方面受到限制,通常不支持纹理,或者在合成过程中使用神经渲染器,这使得它们在普通三维软件中的使用变得不那么简单了。在这项工作中,我们介绍了GET3D,这是一个生成模型,可以直接生成具有复杂拓扑结构、丰富几何细节和高保真纹理的显性三维网格。我们利用最近在可分化表面建模、可分化渲染以及二维生成对抗网络方面取得的成功,从二维图像集合中训练我们的模型。GET3D能够生成高质量的三维纹理网格,范围包括汽车、椅子、动物、摩托车和人类角色以及建筑物,与以前的方法相比,取得了重大改进。

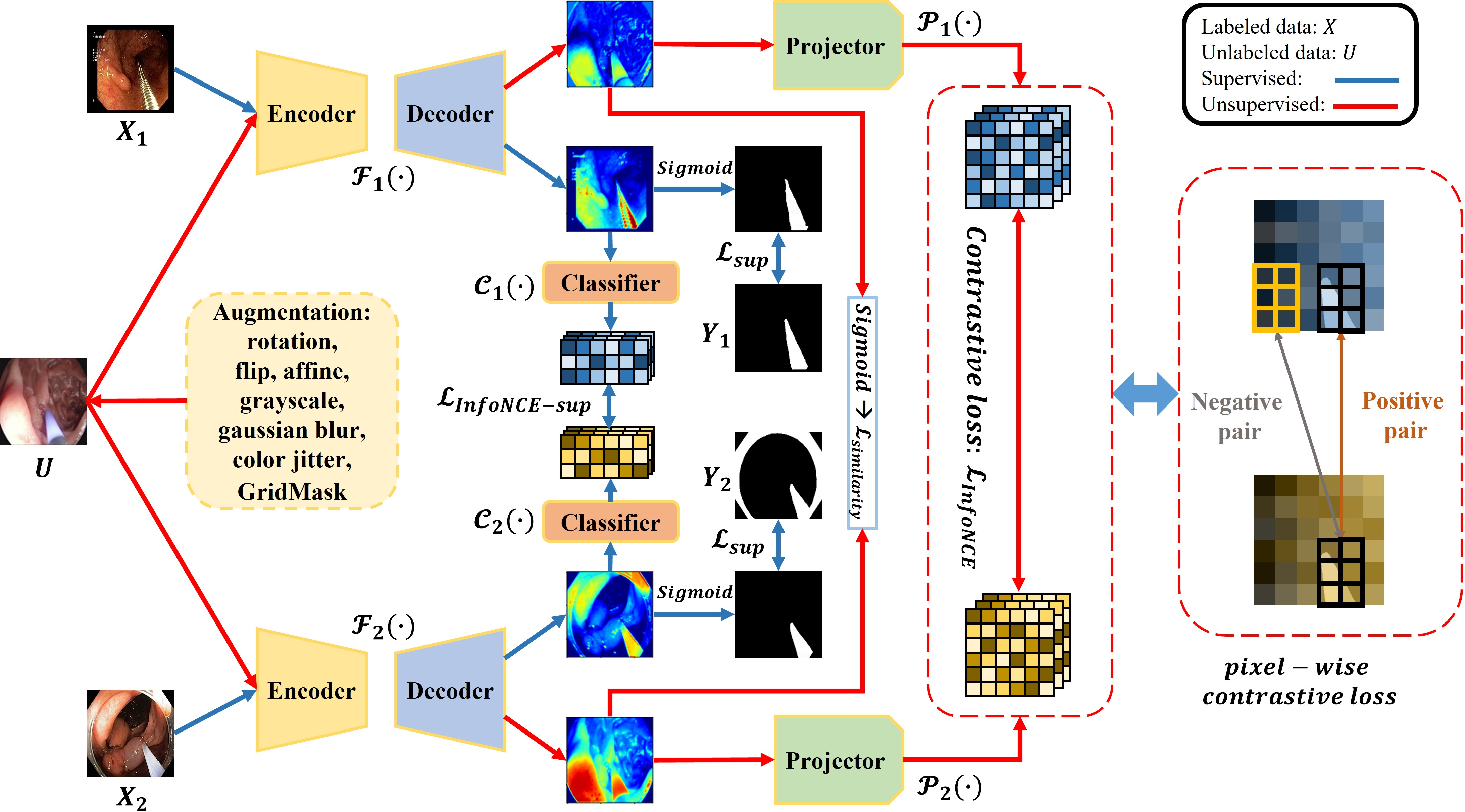
⚡ 论文:Min-Max Similarity: A Contrastive Semi-Supervised Deep Learning Network for Surgical Tools Segmentation
论文时间:29 Mar 2022
领域任务:Contrastive Learning, Video Segmentation, 对比学习,视频分割
论文地址:
代码实现:
论文作者:Ange Lou, Kareem Tawfik, Xing Yao, Ziteng Liu, Jack Noble
论文简介:To address this issue, we proposed a semi-supervised segmentation network based on contrastive learning./为了解决这个问题,我们提出了一个基于对比性学习的半监督性分割网络。
论文摘要:图像的分割是医学人工智能中的一个热门话题。这主要是由于难以获得大量的像素级注释数据来训练神经网络。为了解决这个问题,我们提出了一个基于对比学习的半监督性分割网络。与之前的最先进技术相比,我们引入了最小-最大相似性(MMS),这是一种双视图训练的对比学习形式,通过采用分类器和投影仪分别建立全负例、正负例特征对,将学习问题表述为解决最小-最大相似性问题。全负例对被用来监督从不同视图中学习的网络,并确保捕获一般特征,而未标记的预测的一致性是通过正负对之间的像素对比损失来衡量的。为了定量和定性地评估我们提出的方法,我们在两个公开的内窥镜手术工具分割数据集和一个人工耳蜗手术数据集上进行了测试,我们对手术视频中的人工耳蜗进行了人工标注。分割性能(dice coefficients)表明,我们提出的方法始终优于最先进的半监督和完全监督的分割算法。而且我们的半监督分割算法可以成功地识别未知的手术工具并提供良好的预测。此外,我们的MMS可以达到每秒40帧(fps),适合处理实时视频分割。
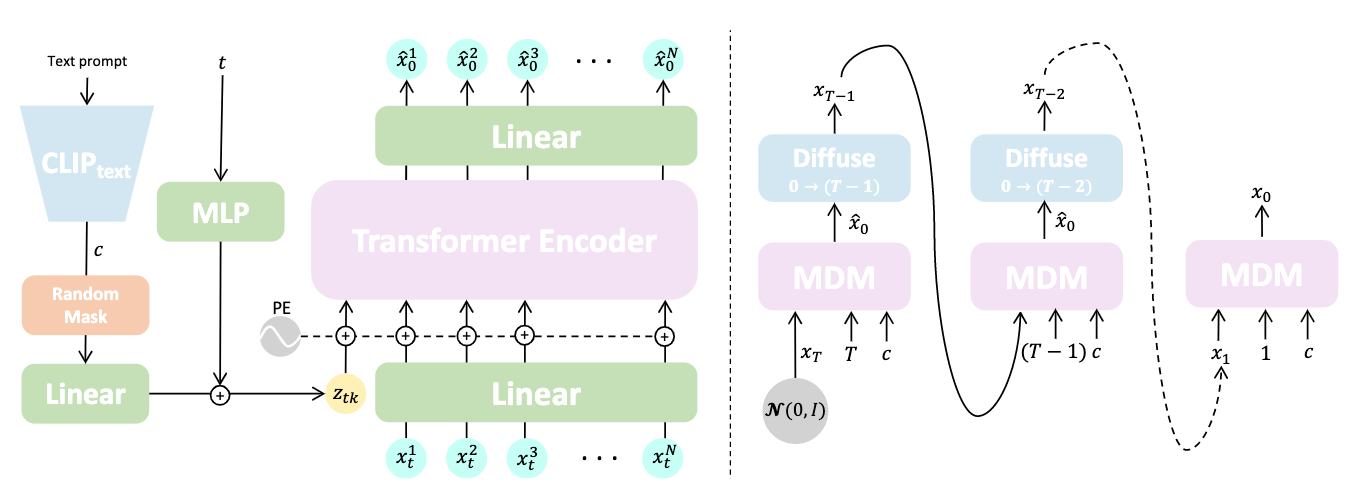
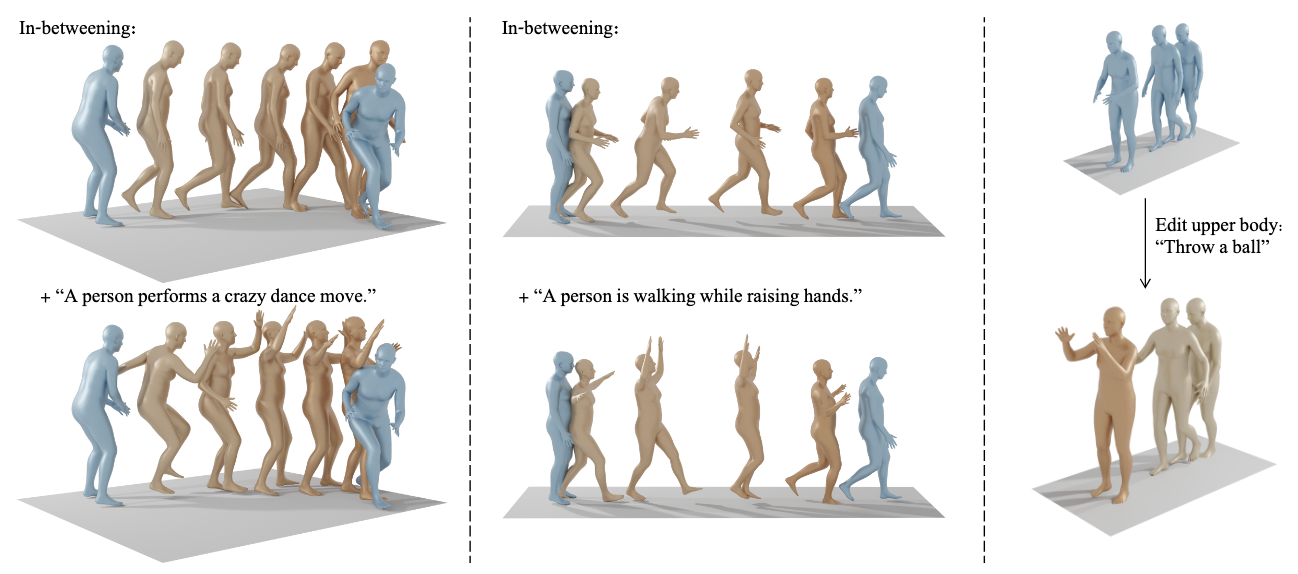
⚡ 论文:Human Motion Diffusion Model
论文时间:29 Sep 2022
领域任务:Motion Synthesis,动作同步
论文地址:
代码实现:
论文作者:Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, Amit H. Bermano
论文简介:In this paper, we introduce Motion Diffusion Model (MDM), a carefully adapted classifier-free diffusion-based generative model for the human motion domain./在本文中,我们介绍了运动扩散模型(MDM),这是一个经过精心调整的基于无分类扩散的人类运动领域的生成模型。
论文摘要:自然而富有表现力的人类运动生成是计算机动画中一项具有挑战性的任务,由于可能的运动的多样性,人类对运动的感知敏感性,以及准确描述运动的难度。因此,目前的生成解决方案要么质量不高,要么表现力有限。扩散模型由于其多对多的性质,已经在其他领域显示出了显著的生成能力,是人类运动生成的有希望的候选者,但它们往往是资源匮乏的,而且难以控制。在本文中,我们介绍了运动扩散模型(MDM),这是一个经过精心调整的用于人类运动领域的无分类器扩散生成模型。MDM是基于transformer的,结合了运动生成文献的见解。一个值得注意的设计选择是在每个扩散步骤中对样本的预测,而不是对噪声的预测。这有利于使用既定的关于运动位置和速度的几何损失,如脚部接触损失。正如我们所证明的,MDM是一种通用的方法,可以实现不同的调节模式和不同的生成任务。我们表明,我们的模型是用轻型资源训练的,但在文本到运动和动作到运动的主要基准上取得了最先进的结果。项目可以在 查看。
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。
