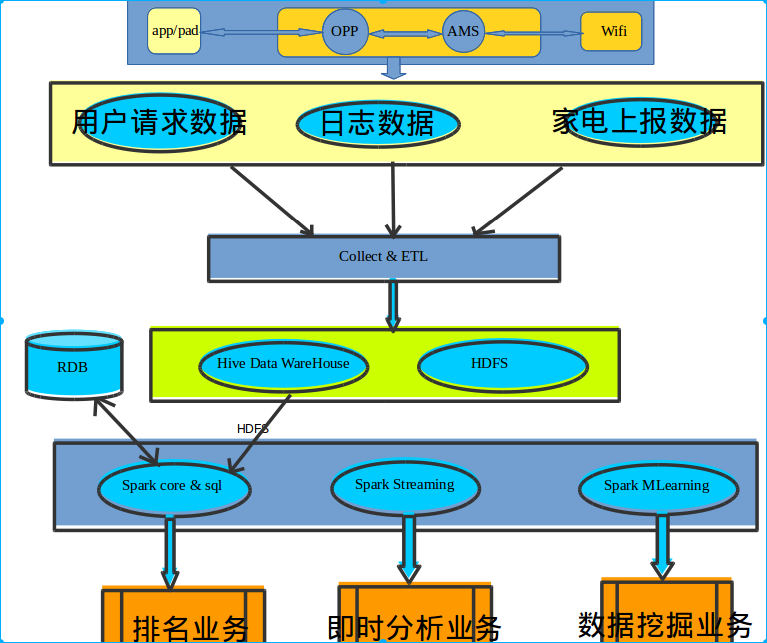
当谈到大数据开发工程师面试题时,这里有一些常见问题和示例答案供参考:1. 请解释什么是大数据(Big Data)?大数据是指无法在一定时间范围内用传统的数据处理工具进行捕捉、管理和处理的大规模数据集。它通常包含了结构化、半结构化和非结构化的数据,并且具有高速度、高卷度和高多样性的特点。2. 请介绍一下大数据处理的常见技术栈。大数据处理的常见技术栈包括:- 分布式存储系统:如Hadoop Distributed File System(HDFS)、Amazon S3等。- 分布式计算框架:如Apache Spark、Apache Hadoop MapReduce等。- 数据流处理平台:如Apache Kafka、Apache Flink等。- 数据仓库:如Apache Hive、Apache HBase等。- 数据可视化工具:如Tableau、Power BI等。3. 请解释一下MapReduce的工作原理。MapReduce是一种用于并行计算的编程模型。它将任务划分为两个阶段:Map和Reduce。在Map阶段,输入数据被分割为若干个独立的片段,并由多个Map任务并行处理。在Reduce阶段,Map任务的输出结果被合并和排序,然后由多个Reduce任务并行处理并生成最终的输出结果。4. 请解释一下Hadoop和Spark的区别。Hadoop和Spark都是用于大数据处理的工具,但它们有一些区别。Hadoop是一个分布式计算框架,主要基于MapReduce模型进行数据处理。而Spark是一个快速、通用、内存计算引擎,可以处理更复杂的数据处理任务,并且支持多种计算模型,如批处理、流处理和机器学习。5. 请介绍一下数据仓库和数据湖的区别。数据仓库是一种用于存储结构化数据的中心化存储系统,通常采用关系型数据库来管理和查询数据。而数据湖是一种存储大规模原始和未处理数据的中心化系统,通常采用分布式文件系统来存储数据。数据仓库侧重于处理结构化数据,而数据湖则更适合存储和处理各种类型的数据,包括结构化、半结构化和非结构化数据。这些问题只是大数据开发工程师面试中的一小部分,希望对你有所帮助。如果你有其他特定的问题,请告诉我,我将很乐意为你解答。