全文共 4190 字,阅读需要 7 分钟
—— BEGIN ——
2011年起,知乎的百度指数一路上升。
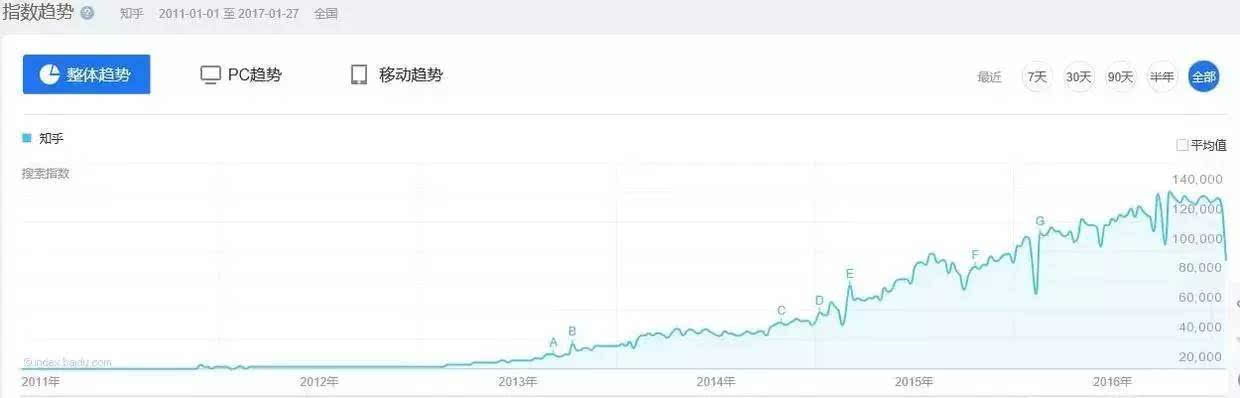
知乎百度指数
Alxea排名显示,知乎已经成为中国的第三十二大网站。而排列 31 名和 33 名的,分别是新华网和 CCTV 。
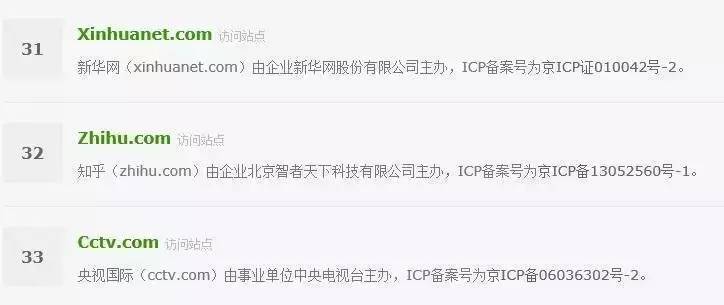
知乎Alxea排名
虽然知乎后来推出了读读日报/知乎日报/知乎 Live /知乎专栏等内容,但最核心的流程仍然是提问和回答。
本文讨论问答的流程。红色框内的流程将在下文详细讨论。

知乎的问答流程
为了优化问题下的回答质量,我们能做什么?
在单个问题下,将优质答案放置于更加明显的位置。让点进问题的用户第一眼就能看见优质回答。而将质量一般的回答放置于底端较不明显的位置。并且将不友善的问题折叠
让优质答案得到更多的曝光。包括得到点赞,推荐到知乎日报,官方微博,发现页面等。
促进交流:让问题发表后可以得到有质量的评论。
激发归属感和认同感:这里有我喜欢的内容/用户,我希望能加入他们。
设置收藏夹、专栏等,将更多的优质内容沉淀下来。而不是随着时间流逝,消失不见。
下面将从产品的角度分析所有提及的优化点:
根据答案的优劣程度排序
将优质答案放置于最明显的位置怎么实现?
要根据答案的优劣程度排序答案,首先要定义 什么是优质答案。
百度知道定义的“优质答案”来自于提问者的选择。只要提问者选择了一个自己心中的优秀答案,问题就会被盖棺定论。未被选择的答案可能会被折叠。如果后人搜索到百度知道的问题,很可能只能看到提问者选择的优秀答案。当然,提问者选择的答案主观性较强,未必是最被认可的答案。
而在知乎,回答好像是以问题为核心的开放性的“命题作文”。大家以问题为中心,各抒己见,更多的是百花争鸣的观点碰撞,而不是将某一个答案作为终极的标准。同时,随着知乎用户量的大幅增加,单个问题下可能会产生成千上万个回答。
当单个问题下答案较多时,根据回答质量来排序答案顺序将是极为关键的。如果点进问题后首先看到的是一些高质量回答,将会极大提高信噪比,提升用户感受。
这类(根据少量样本判断总体情况的问题),非常适合采用威尔逊算法。
旧算法可以简化为:
加权反对数:用户在某个问题下的权重,是根据他过去在相关话题下的回答得到的赞同/反对/没有帮助票数计算的。高权重的投票会对排序有更大的影响。知乎并不计算用户的全局权重,而是分领域计算权重。
旧算法有如下瓶颈:
假如 A 答案有 600 加权赞同,400 加权反对,而 B 答案有 90 加权赞同,10 加权反对。此时 A 答案的赞同率是 60% ,而 B 答案的赞同率是90%。 B 答案赞同率高,被大家认同的概率较大。但是根据旧算法, A 答案的得分高于 B 答案。 具体来说,抖机灵却没有帮助的答案,可能会得到大量赞同和大量反对。但是由于加权赞同数大于加权反对数量,仍然会排列在干货满满但得赞较少的答案前面。
最先产生的答案如果质量不错而获得高票,那么新产生的质量较高的答案,由于票数较少会被排列在最下面,难以得到浏览,从而很难得到点赞而名列前茅。
那么直接计算赞同率合适吗?
【得分=赞同数/(赞同数+反对数)】
当投票量较大的时候,这样做是合理的;当投票量较小的时候,这样就不合适了。
假如 A 问题质量较高,得到 9900 赞同 100 反对,赞同率 99% ,而 B 问题质量较差,只有 1 个赞同。将 B 答案放置在 A 答案之前显然是不合理的。
如果算法能够弥补投票量较小时候得到的赞同率不准确这一缺点就好了。
1927 年,美国数学家 Edwin Bidwell Wilson 提出了一个修正公式,被称为“威尔逊区间”,很好地解决了小样本的准确性问题(以下内容涉及一部分数理统计知识):
用户的答案有什么特点呢?
用户只有赞同和反对两个选项。(设赞同数=u,反对数=v,总票数n=u+v)
用户之间投票行为独立。
当投票量增加的时候,样本赞同率(u/n)逐渐趋近总体赞同率(n等于无穷大时候的u/n)。
很显然,用户的投票是二项分布。根据用户投票,可知样本赞同率和样本赞同率的置信区间。 置信区间的宽窄,取决于样本的数量。计算置信区间的方法有很多(大学教材中计算置信区间的方法是”正态区间法“,但是这种方法不适用于小样本的置信区间计算),威尔逊算法能够很好的计算小样本情况下的准确度。
具体来说:
900 赞同,100 反对的 A 回答,赞同率 90% ,有 95% 的把握可以断定,赞同率在 [89%,91%] 之间。而 9 赞同,1 反对的 B 回答,赞同率 90% 。有 95% 的把握可以断定,赞同率在 [85%,95%] 之间。 B 回答的赞同率下界 85% 低于 A 回答赞同率的下界 89% ,所以 B 回答应该放置在低于 A 回答的位置。
知乎的算法步骤:
计算赞同率(总投票数可能较小,所以将实际赞同率看作样本赞同率,通过样本赞同率,估算可能的总体赞同率)
计算赞同率的置信区间下界,得到得分(计算公式如下图)
根据得分排序(只需要在有用户投票时候重新计算)
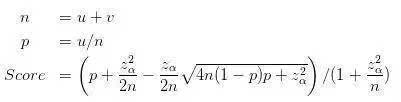
如果在wiki查威尔逊区间,会发现下图公式。知乎算法采用的是威尔逊区间的下界。
新算法有什么影响呢?
01 旧算法下,排名反应的是加权赞同数和加权反对数的差。而新算法下,排名反应的是经过修正的赞同比。
也就是说,一些赞同数远大于反对数,但是赞同比较低的答案将会被放置在靠后的位置上。
算法克制了争议性较强的问题。类似的情况包括:
抖机灵爆照但没有帮助,煽动性较强但没帮助,大 V 用户的低质量回答,攻击性回答(这些问题自带很多赞同和很多反对,赞同比较低)
争议性话题下的优质回答(话题天然争议性较强,明确表达自己观点的回答)自带大量赞同和反对,从而被放置在不明显的位置。而较为中庸却没有输出任何实际内容的回答,却被放置在了明显位置(对于百家争鸣类型的讨论,这样到底合适吗?)
某种程度上鼓励了“知乎政治正确”。一些符合知乎政治正确但是并不客观的回答被置顶,而真正客观理性的回答被放置在不明显的位置(之前写快手分析报告的时候去知乎查资料,很希望看到一些客观的讨论,但发现倾向性非常强的答案放置在顶端,而较为客观又干货满满的回答被放置在底端)
02 普通用户也许更愿意答题了。
知乎的首页 timeline 来自用户关注的人。以前知乎大 V 出场自带 500 赞(当然可能也自带 500 反对)。而新算法按照赞同比排序。即使已经有了几千个回答,几个赞同仍然能让新的优质答案被放置在顶端。小透明也不怕被无视了。
03 专业领域下大 V 的作用更明显了
新算法本就加强了用户投票对排名的影响,拥有专业领域下投票加权的大v的投票可能更为关键。很可能大v点一次反对,顶端的答案立马下沉,底端的答案瞬间置顶。
总而总之:新算法是有利有弊的,但更多应该是利大于弊。
其他采用威尔逊算法的网站还有:reddit、yelp、digg(我怀疑虎扑步行街评论,网易云音乐评论也是类似算法,但是没有证据……)