
项目背景
数据显示,在发达国家市场,汽车制造与销售的利润约占整个汽车产业利润的20%,零部件供应利润约占20%,其他60%的利润是在服务领域中产生的。由于目前我国的汽车销售利润占比依然很高,按照业界每1元购车消费会带动0.65元汽车售后服务的惯例来看,我国汽车后市场潜力巨大。从2014年到2016年,各大经销商纷纷投入重金,以增强维修保养的盈利成长性。据汽车工业协会统计,2014年中国汽车后市场获得的风险投资多达67次,是2013年的十倍。显然汽车厂商、经销商和服务商等主体的关注点也从新车销售逐渐转向汽车后市场。而随着行业竞争的加大,消费者理性消费意识增强,汽车后市场主体的利润空间不断受到挤压,全国20000多家4S店的经营状况愈发恶化,亏损面不断加大。店内的精细化管理、信息化也更加受到重视,有了大量的数据如何运用?是否能建立科学管理标准体系化管理流程?已经成为汽车业内人士的课题。
近年来,随着大数据应用和人工智能机器学习技术的不断成熟和应用,使得汽车后服务市场的精细化管理和数据化管理成为可能。本文从内审合规角度探讨如何运用大数据技术和机器学习技术实时和探查4S店内售后服务薄弱环节,帮助经销建立数据驱动服务、数据内控合规、防止跑冒滴漏、优化经销商服务体系、达到实时监控自身服务质量和管理质量的目的,通过对标行业整体发展的水平,不断优化和提升管理效果,进而实现增加利润的目的。
传统审计模式
(1)人工审核
很多经销商通过一定的标准对大金额的事故维修、保险定损进行人工审核。向较于数据化分析工具,传统审计方法的痛点主要包括:
a、这种方式需要审核人员具有财务、审计、售后服务管理、客户关系管理等多维度专业经验。但实际情况是汽车经销商集团往往是多个品牌经营,一个人往往不能完全掌握多领域经营以及每个车型的配件特点。
b、人工审核的往往也会出现舞弊问题。
c、与现代技术的应用相比,往往审计时间长,效率低。
(2)基于规则的系统识别
大经销商集团往往有自己的财务系统(金蝶、用友),CIO往往希望在系统中部署业务规则,例如:车型常规配件的出库规则(车型应该出几个火花塞、标准机油是多少)等等,将触犯规则的工单推送到人工再次复核。这种方式的优点就是基于人工的经验查找已知的案件有效,但无法对新的欺诈案件自动更新,而且时间长了往往容易具有抗药性。
基于机器学习的反欺诈系统
大数据和机器学习的应用,将使得经销商在售后服务更加高效和降低人员投入。在售后业务反欺诈业务中可以利用数据分析和机器学习的算法,针对每个工单进行多维度的精准评分,从而帮助经销集团提高管控能力。随着时间的推移,机器学习算法可以学习越来越多的判断标准和风控经验。
大数据和机器学习算法可针对不同售后类型的欺诈行为均能体现出效果,可针对车型历史维修数据、维修人员维修记录、配件出库数据规则等进行多维度综合分析。同时,这种混合分析方案可以对每个类型的工单进行逐条审核、判断,帮助人工审核人员更加高效的专注于高风险案件,避免窝案的产生,提高欺诈案件的识别率,并且降低工单的欺诈案件的产生率,提高管理运营水平。

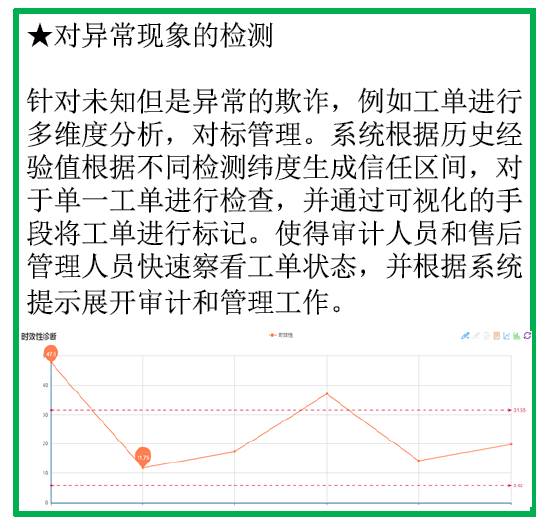
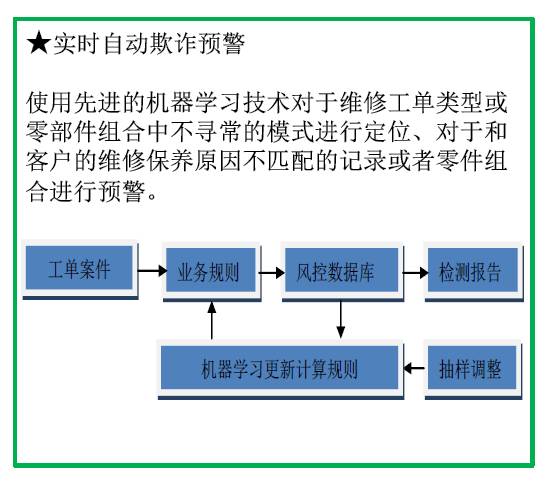
机器学习的反欺诈算法
★ 自动算法:关联分析
关联分析是从大量数据中发现项集之间有趣的关联和相关联系。关联分析的一个典型例子是购物篮分析。该过程通过发现顾客放人其购物篮中的不同商品之间的联系,分析顾客的购买习惯。通过了解哪些商品频繁地被顾客同时购买,这种关联的发现可以帮助零售商制定营销策略。其他的应用还包括价目表设计、商品促销、商品的排放和基于购买模式的顾客划分。而现在的应用场景是维修类型出库配件的关联性分析,通过出库记录频次分析异常配件出库现象,例如与车型不匹配的异常保养件出库等。
★ 异常值检测算法---最小二乘法
最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。经过数据的整理采用最小二乘法拟合出各种类型、人员的最佳函数匹配,针对异常值进行实时监测上报。
★ 聚类算法K-MEANS
k-means 算法接受输入量k;然后将n个数据对象划分为k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的。k-means 算法的工作过程说明如下:首先从n个数据对象任意选择k个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。
