随着移动端增长红利趋于减少,各媒体、搜索引擎的在线流量竞价不断走高。现如今,单纯的在线展示广告获客成本愈发透明,效果增长乏力。随着大数据的兴起与机器学习技术的不断提升,集奥聚合通过自身丰富的客户画像标签体系,结合业界先进的机器学习技术,突破传统广告的局限性(仅通过人为主观精心设计的统一广告页来吸引客户),实现多元优化及精准需求预测,提升各流转环节,达到精准营销。本文诣在通过真实营销项目案例与大家共同探讨学习。
项目背景
如果说2013年是互联网金融元年的话,那么2016年无疑是普惠金融的爆发年,伴随着大数据行业的逐步发展,FINTECH技术的日趋完善,普惠金融的竞争也愈演愈烈。这种竞争最终直接演变为了各家公司获客能力及风控能力的全面比拼。集奥聚合作为一家大数据创新应用服务公司,对于如何利用大数据技术以及多年积累的运营经验,帮助企业对于其目标客群进行挖掘及营销有着自己独特的理解和实践。
在本文介绍的案例中,取得的效果为:预约率提升为其他渠道的2.5倍左右,投资回报率较其他方式提升64%。
项目流程
1、双方基于业务需求进行客户匹配,返回脱敏客户标识到集奥聚合进行数据贴标;
2、通过分析信贷类产品的客户画像对客户进行需求&价值分析,筛选出高需求高价值客户,给到合作企业进行客户需求调研(可根据不同层级客户匹配不同触达方式及权益等营销方案设计);
3、根据合作企业实时性数据反馈,进行筛选维度调整,不断优化迭代模型,提升各环节转化率。
如图:
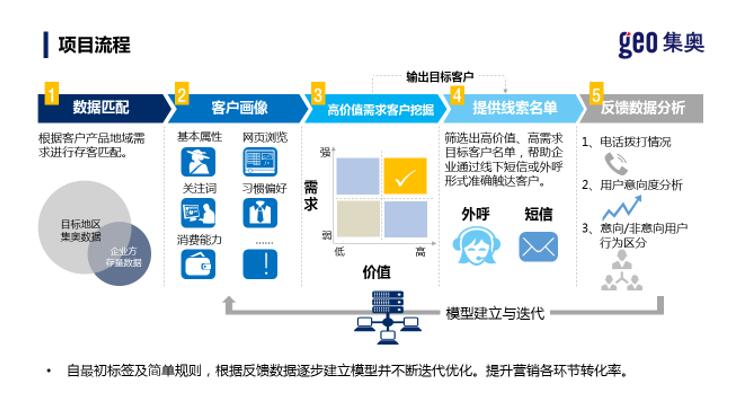
需求预测模型介绍
集奥聚合通过标签数据与模型相结合,筛选出最优质客户帮助企业进行触达,在提升响应率前提下,达到提升业务收入同时节约合作企业各项成本的目标。
1、基于标签数据的触发推荐
提取有对应信贷产品标签访问的客户作为触发推荐基础目标客户,根据需求强度不同(本品->竞品->关键词->相关衍生品)逐步扩大触发人群基础规模。同时根据不断反馈迭代,扩充相似高转化标签,去除低转化标签,优化触发规则。
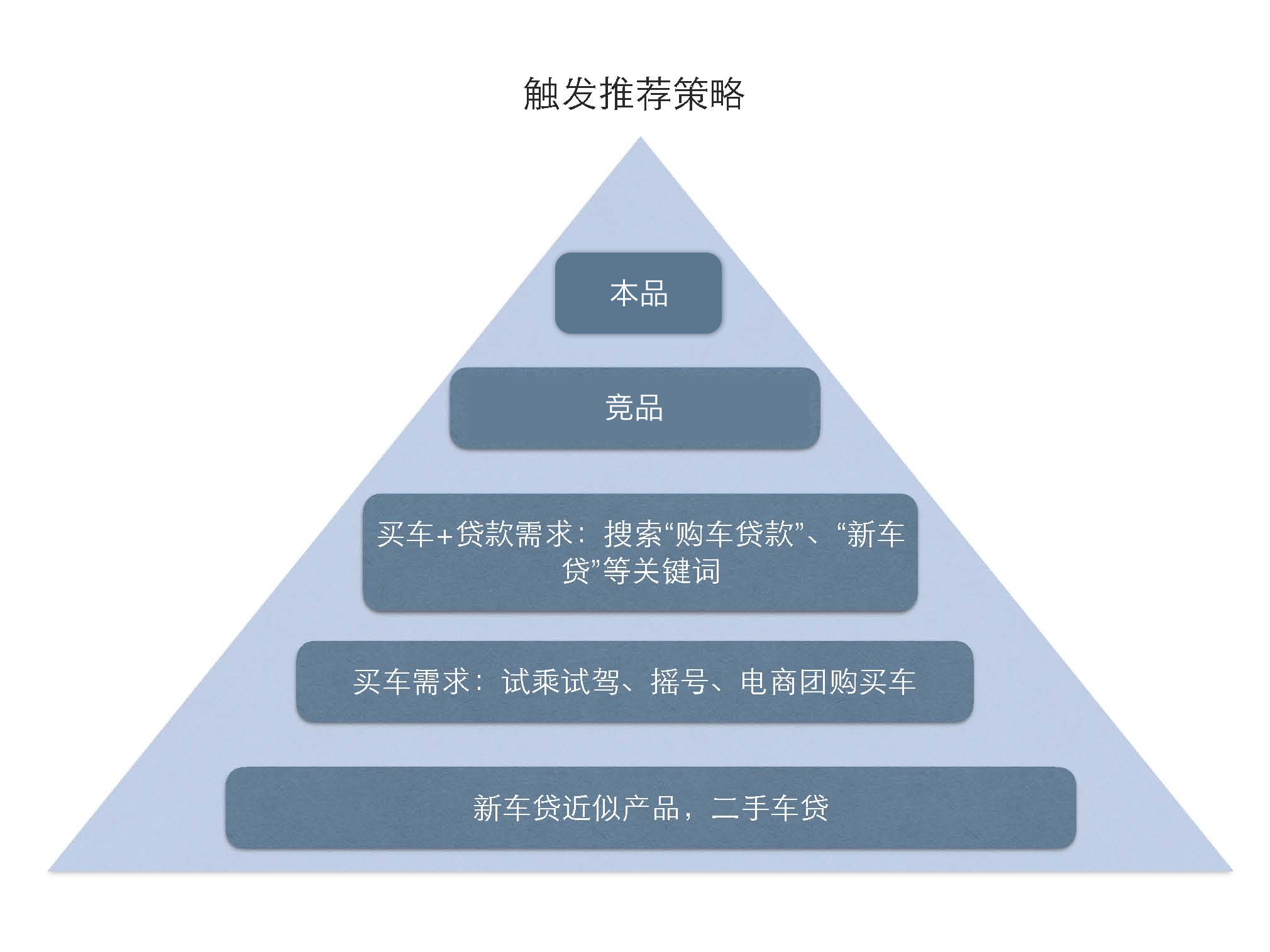
2、基于客户相似度的模型排序推荐
本项目诣在预测客户对借贷产品的需求程度从而进行个性化营销推荐
(1)模型选择
目标变量的样本反馈为真实的有无借款需求,即二分类问题。本项目通过不断尝试,最终选择深度学习技术进行模型发现。
(2)特征变量选取及相关算法
机器学习中,首要就是找出相关特征(特征选择与特征提取)。业界流传名句之一:数据和特征决定了机器学习的上限,而模型和算法调整只是为了无限逼近这个上限而已。故此,数据与特征工程是机器学习中的重中之重一环。由于集奥聚合亿级标签数据的高维度、稀疏性等特性,在工程上选用了大约2.5万个特征变量作为输入进入模型。
(3)模型效果检验
为有效检验模型效果,并兼顾模型泛化、防止过拟合,将样本数据进行分割,分为训练集和测试集,比例为7:3。
效果检验指标采用训练集及测试集AUC(Area under ROC)。
以下三图分别为:欠拟合,适度拟合及过度拟合效果示意图。欠拟合会出现训练集及测试集效果均不佳的表现;过度拟合模型结果泛化性差,容易出现训练集结果好,测试集结果差的情况出现。
营销效果
1、根据某信贷机构反馈数据新定制化借贷需求预测模型结果训练集AUC为0.82,测试集0.75。原有贷款模型AUC为0.63,定制化后效果提升AUC为之前的1.19倍;
2、客户预约率为其他渠道的2.5倍左右;
3、通过有效的触达方式,核算成按CPS方式,运营成本较其他项目下降节省39%。
大数据与机器学习紧密相连,但是大数据并不等同于机器学习,机器学习也不完全等同于大数据。随着数据量的提升,大数据中包含分布式计算、内存数据库、多维分析等多种技术。机器学习只是大数据分析中的一种而已。但机器学习与大数据的深度结合使数据可以产生更大的价值。基于丰富的数据以及机器学习技术两方面才能更加精确的进行数据“预测”。两者相乘才能发挥出数据的更多价值。
对知识的深刻理解一定是建立在真正应用时。通过实践才可以对机器学习理解更近一层。成功的机器学习应用不是拥有最好的算法,而是拥有更多的数据!所以,欢迎各位希望证实自己研究价值的有志之士加入集奥聚合,一起在数据的海洋中探索技术与数据相结合的价值之美。





