场景
准备换工作开始新的人生道路了:纠结,,,怎么优雅地编写项目经验呢?
简历 基本信息
姓 名 : 彭宇成 年 龄: xx CET-6 : xx Scores
学 历 : 本 科 专 业: 通信工程 毕业院校:xxxx
技术博客: 个人网站:
工作经历: 2012/5-2014/3 **公司 服务器端开发工程师
2014/3-2016/6 **公司 高级软件工程师(大数据spark方向)
工作经验: 3年java服务器端开发经验; 1年+Spark交互式大数据平台开发经验
求职意向: 大数据开发(spark方向) 目前月薪(税前):xxxx 期望月薪:xxxxx
技能点
1、良好的数据结构与算法基础;优秀的英文阅读能力,能顺利阅读英文专业书籍与开源网站; 善于学习并与团队分享新技术;优秀的写作能力。
2、熟悉java,掌握反射、多线程与NIO等java高级特性的使用,并深入理解面向对象编程; 理解函数式编程,迷恋scala并深入理解隐式转换与类型类等scala高级特性。
3、熟悉常用设计模式的使用;掌握并发处理框架akka、Redis缓存、中间件Rabbit MQ等第三方产品的使用。
4、掌握JSP、Servlet、以及SSH(Struts+Spring+Hibernate)框架的使用;了解HTML、CSS、JavaScript,ajax与报表设计器,工作流设计器,表单设计器的使用 。
5、掌握hive、flume与hdfs等hadoop生态技术圈的相关技术的基本使用 ; 理解Spark工作机制,阅读过最新spark(1.6.2)内核源码; 熟练掌握Spark core、Spark sql的开发、了解 Spark Streaming的开发;。
6、理解并熟练掌握spark大数据项目各种性能调优、线上troubleshooting与数据倾斜的解决方案。
7、熟悉mysql/oracle数据库的使用,掌握oracle存储过程的编写;熟悉Linux常用命令的使用,熟悉shell编程。
项目经验
智能家居平台包括三端:app端,数据服务端与家电端,分别由三家公司参与研发。
其中,数据服务端包括两大子平台:数据处理平台 与 交互式大数据家电用户行为分析平台。
数据处理平台:作为手机app端与家电端的数据通信中转站,旨在为用户实现远程操作与监控家里的电器设备,例如,空调、冰箱、洗衣机、电饭煲与小烤箱等提供平台支持:接收并分析用户通过HTTP发送的家电操控指令,进而通过tcp将控制报文下发给家电端。家电端收到报文后,按照自定义的通信协议,解释报文中的相关命令字段,进而对家电进行具体的操控。
家电用户行为分析平台:旨在通过分析用户的家电操控行为数据与家电运行上报数据,深入了解用户的家电操作喜好与监控家电设备的运行状况。为优化公司已有产品提供数据支持,最终为用户提供更好的家电使用体验,提升公司价值。
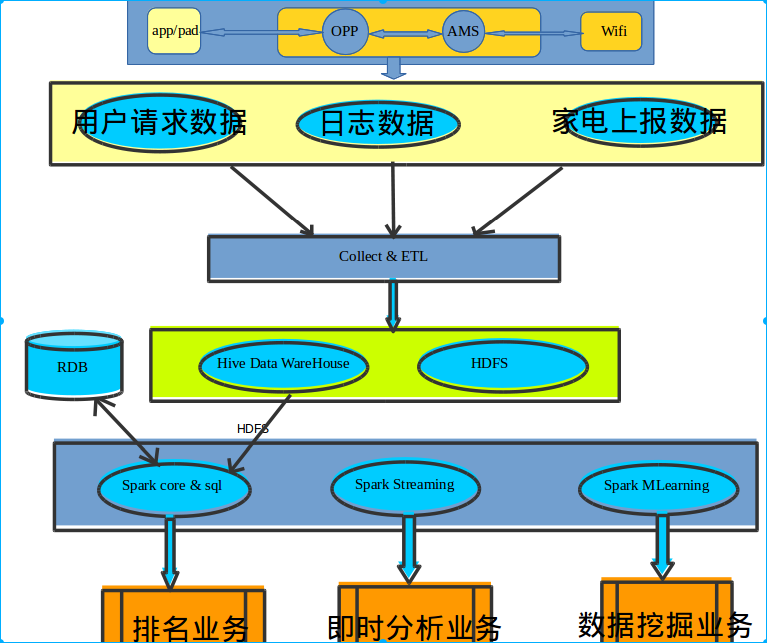
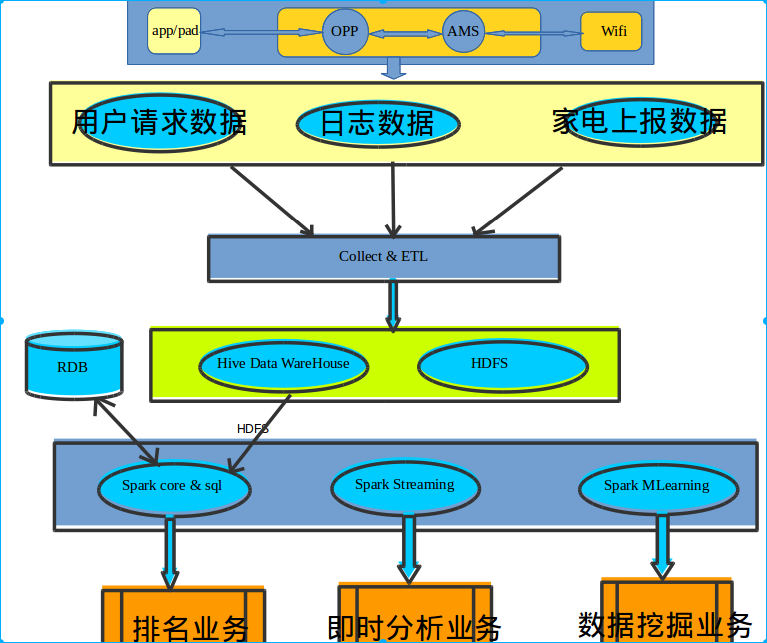
家电用户行为分析大数据平台 概念架构图
数据处理平台
1、项目基于servlet+hibernate3.x+spring3.x架构,缓存基于Redis结合Spring AOP实现;中间件采用Rabbit MQ处理业务日志、家电状态上报与推送等消息类型。
2、包括6大子系统SOPP、SAMS、STPP、SPUSH、STPS、SQTS 以及SManager。其中SOPP负责处理本平台用户的请求、TPP负责处理第三方平台用户的请求 、SAMS负责分析用户的请求指令并下发至家电端、PUSH子系统负责处理非用户的家电操作业务、SQTS负责作业的调度 eg、定时清除相关临时表中的数据 ;SManager子系统负责查询统计分析类业务:接收用户的查询统计请求,通过Java Runttime API执行关联的spark作业,完成家电用户行为分析,并将执行结果,与分析出来的数据写入mysql供前台展示用。
家电用户行为分析大数据平台
基于spark1.3.x为计算引擎,具体概念架构图如上图所示。目前已经实现排名类业务,即时分析与数据挖掘类业务处于预研阶段。排名类业务包括用户操作家电行为分析 与 家电运行状态分析两大子业务。
前期主要负责SOPP与SAMS子系统基础组件:安全组件、分布式session组件与核心业务模块;核心业务模块包括:获取家庭组家电列表、家电应用数据透传、与服务器握手等的开发;后期主要负责 大数据平台 用户操作家电行为分析子业务模块的开发。主要的功能点包括 :
a、按条件筛选session
比如,获取出近一周内某个城市操作家电类型为空气净化器的用户session。
b、统计筛选session的访问时长占比
统计出符合条件的session中,访问时长在1s~3s、4s~6s、7s~9s、10s~30s、30s~60s、1m~3m、3m~10m、10m~30m、30m以上各个范围内的session占比;功能步长在1~3、4~6、7~9、10~30、30~60、60以上各个范围内的家电功能点切换占比。 (注 功能步长值:用户在某一家电类型的功能点之间切换的次数)
c、按时间比例随机抽取1000个session
d、获取具体家电类型操作量排名前3的功能点
e、对于排名前3的功能点,分别获取其最常设置的前3个值
模块开发中用到的主要spark技术点包括:spark core常用算子的使用,自定义累加器、广播大变量的使用;二次排序,分组取TopN算法; spark sql自定义函数 UDF 与 UDAF、常用开窗函数的使用(eg、row_num实现分组取topN)等的使用。同时,积累了包括RDD持久化、shuffle调用、使用Kryo序列化、使用fastutil优化数据存取格式等在内的性能调优方法 及常见的线上troubleshooting与数据倾斜解决办法。
总结
God bless me