第一部分:学习路径概览
首先是一个概览,这个写的时间有点早了,我在下文中进行了内容补充:
第二部分:学习路径拆分
1. 编程语言
计算机专业的同学大多学的第一门编程语言是 C语言,然后再学 Java语言。除此之外可以学习Scala和Python。
Java至少把Java SE阶段学完,学扎实。大数据领域对Java的要求没有上限,越熟悉越好。
2. Linux Linux需要把基础学完,会用基础的命令,需熟练使用基础命令
3. Mysql 为什么要学习Mysql,主要是学习Sql,因为大数据的计算框架Hive,Spark,Flink等都支持Sql的。Mysql按照课程学就可以
4. 计算机基础
即计算机网络,操作系统,数据结构,计算机组成原理,这几门课非常重要的,虽然大多是纯理论知识,但是这都是底层,校招时,大厂都会问的。
对于计算机基础课,我找了一下读书的时候看过的视频和资源,后面还有工作中看的视频,稍有不同: 1、操作系统 Operating System:
2、数据结构
上:
下:
3、计算机网络
4、计算机组成原理 计算机组成原理(上):
计算机组成原理(下):
这部分的内容还是非常多的,我们必须有重点的学,下面是我圈出的重点内容:
计算机网络(重点看 OSI七层模型 或 TCP/IP五层模型 理解每层含义)数据结构(重点看 数组、栈、队列、链表、树)算法(重点看 各种 排序算法、查找算法、去重算法,最优解算法,多去 LeetCode 刷算法题)操作系统(重点看 进程、线程、IO、调度、内存管理)
好了!假如以上的计算机基础你全部掌握了。那么就可以进入大数据领域的正式学习了。
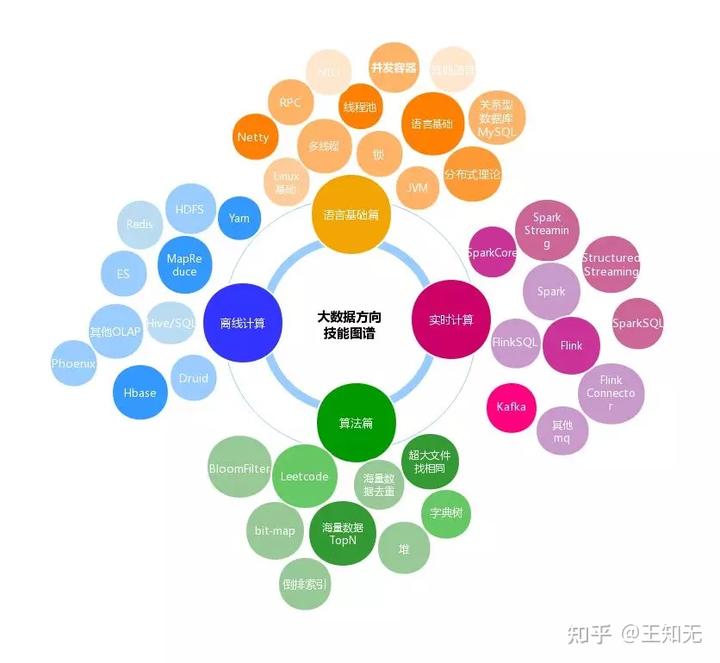
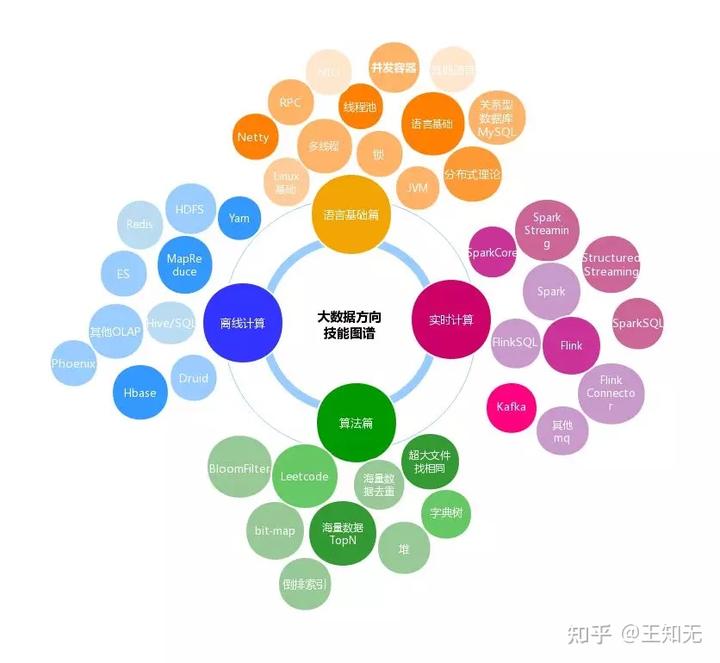
看到上面这个图你脑瓜子是不是嗡嗡的?没关系,跟着我去找重点。
语言基础篇
Java基础篇
整个大数据开发技术栈我们从实时性的角度来看,主要包含了离线计算和实时计算两大部分,而整个大数据生态中的框架绝大部分都是用 Java 开发或者兼容了 Java 的 API 调用,那么作为基于 JVM 的第一语言 Java 就是我们绕不过去的坎,Java 语言的基础也是我们阅读源码和进行代码调优的基础。Java 基础主要包含以下部分:
语言基础锁多线程并发容器(J.U.C)Java 进阶篇
进阶篇部分是对 Java 基础篇的补充,这部分内容是我们熟读大数据框架的源码必备的技能,也是我们在面试高级职位的时候的面试重灾区。
JVM
JVM 内存结构
class 文件格式、运行时数据区:堆、栈、方法区、直接内存、运行时常量池
堆和栈区别
Java 中的对象一定在堆上分配吗?
Java 内存模型
计算机内存模型、缓存一致性、MESI 协议、可见性、原子性、顺序性、happens-before、内存屏障、synchronized、volatile、final、锁
垃圾回收
GC 算法:标记清除、引用计数、复制、标记压缩、分代回收、增量式回收、GC 参数、对象存活的判定、垃圾收集器(CMS、G1、ZGC、Epsilon)
JVM 参数及调优
-Xmx、-Xmn、-Xms、Xss、-XX:SurvivorRatio、-XX:PermSize、-XX:MaxPermSize、-XX:MaxTenuringThreshold
Java 对象模型
oop-klass、对象头
HotSpot
即时编译器、编译优化
虚拟机性能监控与故障处理工具
jps、jstack、jmap、jstat、jconsole、 jinfo、 jhat、javap、btrace、TProfiler、Arthas
类加载机制
classLoader、类加载过程、双亲委派(破坏双亲委派)、模块化(jboss modules、osgi、jigsaw)NIORPCLinux 基础分布式理论篇大数据框架网络通信基石——Netty
Netty 是当前最流行的 NIO 框架,Netty 在互联网领域、大数据分布式计算领域、游戏行业、通信行业等获得了广泛的应用,业界著名的开源组件只要涉及到网络通信,Netty 是最佳的选择。关于 Netty 我们要掌握:
离线计算
Hadoop 体系是我们学习大数据框架的基石,尤其是 MapReduce、HDFS、Yarn 三驾马车基本垫定了整个数据方向的发展道路。也是后面我们学习其他框架的基础,关于 Hadoop 本身我们应该掌握哪些呢?MapReduce:
HDFS:
Yarn:
OLAP 引擎 Hive
Hive 是一个数据仓库基础工具,在 Hadoop 中用来处理结构化数据。它架构在 Hadoop 之上,总归为大数据,并使得查询和分析方便。Hive 是应用最广泛的 OLAP 框架。Hive SQL 也是我们进行 SQL 开发用的最多的框架。关于 Hive 你必须掌握的知识点如下:
列式数据库 Hbase
我们在提到列式数据库这个概念的时候,第一反应就是 Hbase。HBase 本质上是一个数据模型,类似于谷歌的大表设计,可以提供快速随机访问海量结构化数据。它利用了 Hadoop 的文件系统(HDFS)提供的容错能力。它是 Hadoop 的生态系统,提供对数据的随机实时读/写访问,是 Hadoop 文件系统的一部分。我们可以直接或通过 HBase 的存储 HDFS 数据。使用 HBase 在 HDFS 读取消费/随机访问数据。HBase 在 Hadoop 的文件系统之上,并提供了读写访问。HBase 是一个面向列的数据库,在表中它由行排序。表模式定义只能列族,也就是键值对。一个表有多个列族以及每一个列族可以有任意数量的列。后续列的值连续地存储在磁盘上。表中的每个单元格值都具有时间戳。总之,在一个 HBase:表是行的集合、行是列族的集合、列族是列的集合、列是键值对的集合。关于 Hbase 你需要掌握:
实时计算篇
分布式消息队列 Kafka
Kafka 是最初由 Linkedin 公司开发,是一个分布式、支持分区的(partition)、多副本的(replica)的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于 Hadoop 的批处理系统、低延迟的实时系统、Spark 流式处理引擎,Nginx 日志、访问日志,消息服务等等,用 Scala 语言编写,Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源项目。Kafka 或者类似 Kafka 各个公司自己造的消息'轮子'已经是大数据领域消息中间件的事实标准。目前 Kafka 已经更新到了 2.x 版本,支持了类似 KafkaSQL 等功能,Kafka 不满足单纯的消息中间件,也正朝着平台化的方向演进。关于 Kafka 我们需要掌握:
Spark
Spark 是专门为大数据处理设计的通用计算引擎,是一个实现快速通用的集群计算平台。它是由加州大学伯克利分校 AMP 实验室开发的通用内存并行计算框架,用来构建大型的、低延迟的数据分析应用程序。它扩展了广泛使用的 MapReduce 计算模型。高效的支撑更多计算模式,包括交互式查询和流处理。Spark 的一个主要特点是能够在内存中进行计算,即使依赖磁盘进行复杂的运算,Spark 依然比 MapReduce 更加高效。Spark 生态包含了:Spark Core、Spark Streaming、Spark SQL、Structured Streming 和机器学习相关的库等。学习 Spark 我们应该掌握:
(1)Spark Core:
(2)Spark Streaming:
(3)Spark SQL:
Spark SQL 的优化策略:内存列式存储和内存缓存表、列存储压缩、逻辑查询优化、Join 的优化(4)Structured StreamingSpark 从 2.3.0 版本开始支持 Structured Streaming,它是一个建立在 Spark SQL 引擎之上可扩展且容错的流处理引擎,统一了批处理和流处理。正是 Structured Streaming 的加入使得 Spark 在统一流、批处理方面能和 Flink 分庭抗礼。我们需要掌握:
Spark Mlib:本部分是 Spark 对机器学习支持的部分,我们学有余力的同学可以了解一下 Spark 对常用的分类、回归、聚类、协同过滤、降维以及底层的优化原语等算法和工具。可以尝试自己使用 Spark Mlib 做一些简单的算法应用。
Flink
Apache Flink(以下简称 Flink)项目是大数据处理领域最近冉冉升起的一颗新星,其不同于其他大数据项目的诸多特性吸引了越来越多人的关注。尤其是 2019 年初 Blink 开源将 Flink 的关注度提升到了前所未有的程度。那么关于 Flink 这个框架我们应该掌握哪些核心知识点?
SQL 中最常见的两个问题:1.双流 JOIN 问题,2.State 失效问题也是我们关注的重点。
大数据算法篇
本部分的算法包含两个部分。第一部分是:面试中针对大数据处理的常用算法题;第二部分是:常用的机器学习和数据挖掘算法。我们重点讲第一部分,第二部分我们学有余力的同学可以去接触一些,在面试的过程中也可以算是一个亮点。常见的大数据算法问题:
两个超大文件找共同出现的单词海量数据求 TopN海量数据找出不重复的数据布隆过滤器bit-map堆字典树倒排索引第三部分:视频&书籍推荐
万能的B站!Orz...
计算机网络:
2. 数据结构与算法
3. 编译原理
4. 操作系统
接下来计算机专业应用:
Java 这里推荐尚硅谷的宋红康老师的零基础入门 Java。
MySQL
Linux
接下来进入大数据的世界,请按照顺序学习:
Hadoop
2. Hive
3. HBase
4. Kafka
5. Scala
6. Spark
7. Flink
8. 项目 学完框架之后,一定要自己动手写一个项目,一方面能让自己对大数据的框架应用场景有了解,增长项目经验,另一方面也能巩固前面学的框架技能,结合真实场景运用大数据技术去解决,记忆更加深刻。
第四部分:面试题&电子书&视频资源下载
同学们,我真的不敢相信,你们居然看到这里了!我感觉到大厂的offer已经在向你们招手了。最后一关【面试关】!
这部分内容太多了,不仅来源于我自己的输出,还有网络资源的整理。相信大家已经迫不及待了。
你也可以直接参考这篇文章,我个人原创&汇总了大量面试PDF文档可以下载。
这部分会保持持续更新,请持续关注下面的文章。
汇总部分专题部分
Hadoop系列
Hive
Hbase
ES等
Kafka/消息队列
Spark
Flink
数据仓库/数据湖
后端相关
不便分类的其他
面试综合系列
简历系列