dide
手动配置
30
教程简介
阿里云DataWorks基于多种大数据引擎,为数据仓库、数据湖、湖仓一体等解决方案提供统一的全链路大数据开发治理平台。
本教程通过DataWorks,联合云原生大数据计算服务MaxCompute,使用大数据AI公共数据集(淘宝、飞猪、阿里音乐、Github、TPC等公共数据),指导您如何快速进行大数据分析,快速熟悉DataWorks的操作界面与最基础的数据分析能力。DataWorks的更多建模、集成、开发、治理等全链路的数据能力可前往官方文档进行查看。
我能学到什么
操作难度
低
所需时间
30分钟
使用的阿里云产品
所需费用
准备环境和资源
开始教程前,请按以下步骤准备环境和资源:
开通大数据开发治理平台DataWorks。
访问阿里云免费试用。单击页面右上方的登录/注册按钮,并根据页面提示完成账号登录(已有阿里云账号)、账号注册(尚无阿里云账号)或实名认证(根据试用产品要求完成个人实名认证或企业实名认证)。
成功登录后,即可进入申请免费试用DataWorks页面,单击大数据开发治理平台 DataWorks产品的立即试用。
在弹出的购买试用DataWorks产品的面板上选择开通地域为华东2(上海),勾选服务协议后单击立即试用。
准备MaxCompute环境。
创建工作空间并绑定引擎
创建DataWorks工作空间。
登录DataWorks控制台,单击左侧导航栏的工作空间列表,选择工作空间地域为华东2(上海)后,单击创建工作空间。在创建工作空间面板,配置工作空间信息后单击提交。其中核心配置参数如表所示,其他参数可自定义配置或保持默认值即可。
参数
描述
工作空间名称
可自定义工作空间名称。由于工作空间名称需要全局唯一,如果后续操作时提示名称已存在,可更换名称。
本案例设置工作空间名称为doc_test_santie001。
生产、开发环境隔离
本教程选择:是。即将开发和生产隔离。
【扩展知识】
DataWorks的工作空间分为简单模式和标准模式:
详情请参见。
绑定MaxCompute引擎。
在工作空间创建成功界面的大数据优质引擎推荐区域,单击MaxCompute引擎后的立即绑定。根据界面指引配置引擎绑定信息。其中核心配置参数如表所示,其他参数保持默认值即可。
参数
描述
资源显示名称
自定义。由于资源显示名称需要全局唯一,如果后续操作时提示名称已存在,可更换名称。
本案中设置资源显示名称为doc_test。
付费模式
选择按量付费。
【说明】:如果您无法选择按量付费,说明您在上海地域没有开通按量付费的MaxCompute,您可返回上述步骤,参考准备MaxCompute环境的内容,准备好上海地域的MaxCompute环境。
Quota组
选择默认后付费Quota。
生产环境
开发环境
保持默认即可。
完成MaxCompute引擎绑定后,您就可以在DataWorks上使用MaxCompute引擎开始后续的数据分析操作了。
数据分析:阿里电商公共数据
通过本步骤您将体验DataWorks的数据分析的基础能力,除了阿里电商公共数据之外,DataWorks还为您提供了Github等其他公共数据,您可以根据实际情况使用其他数据进行数据分析功能体验。
【注意】:体验各个数据集的数据分析任务时,也会一样占用MaxCompute资源,请您务必评估好资源使用量,避免产生额外的费用。
登录并进入。
首次登录时界面会为您展示大数据基础服务使用声明,您可阅读后勾选服务协议并单击确认,即可进入数据分析页面。
在欢迎页面的阿里电商数据集模块,单击前往分析,选择MaxCompute引擎,打开默认的临时SQL文件。
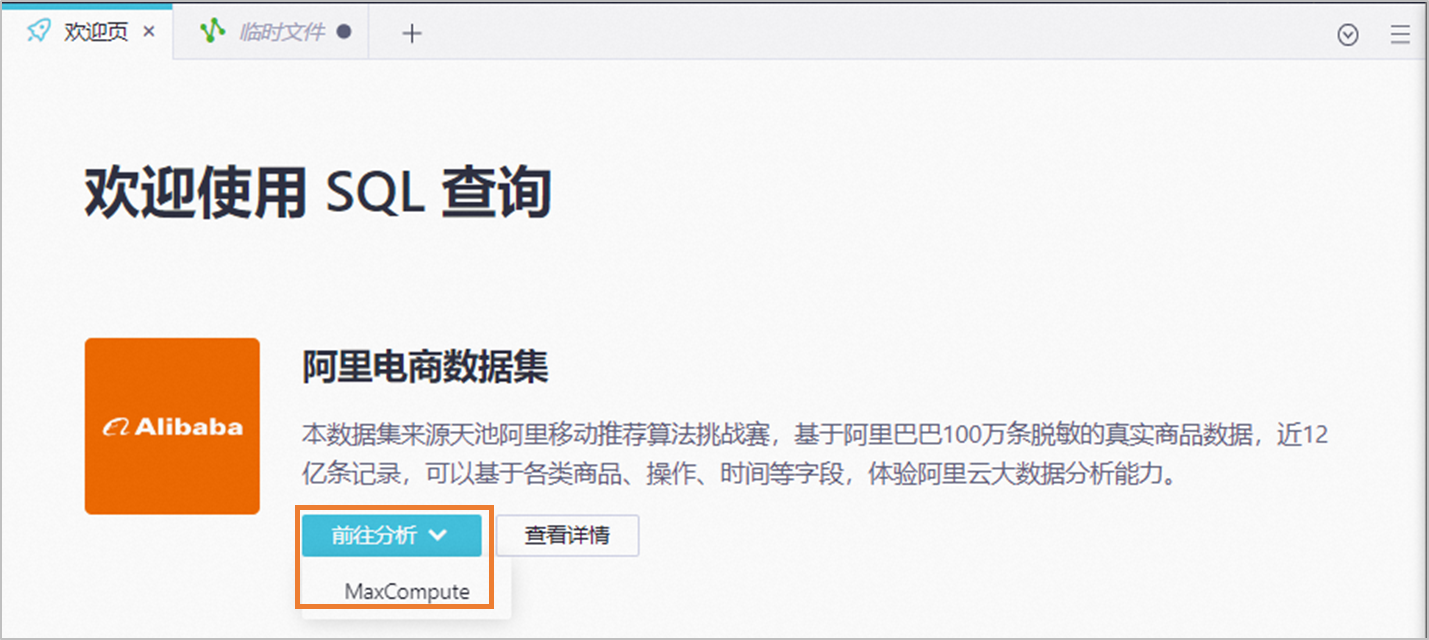
运行阿里电商数据集的数据分析SQL文件。
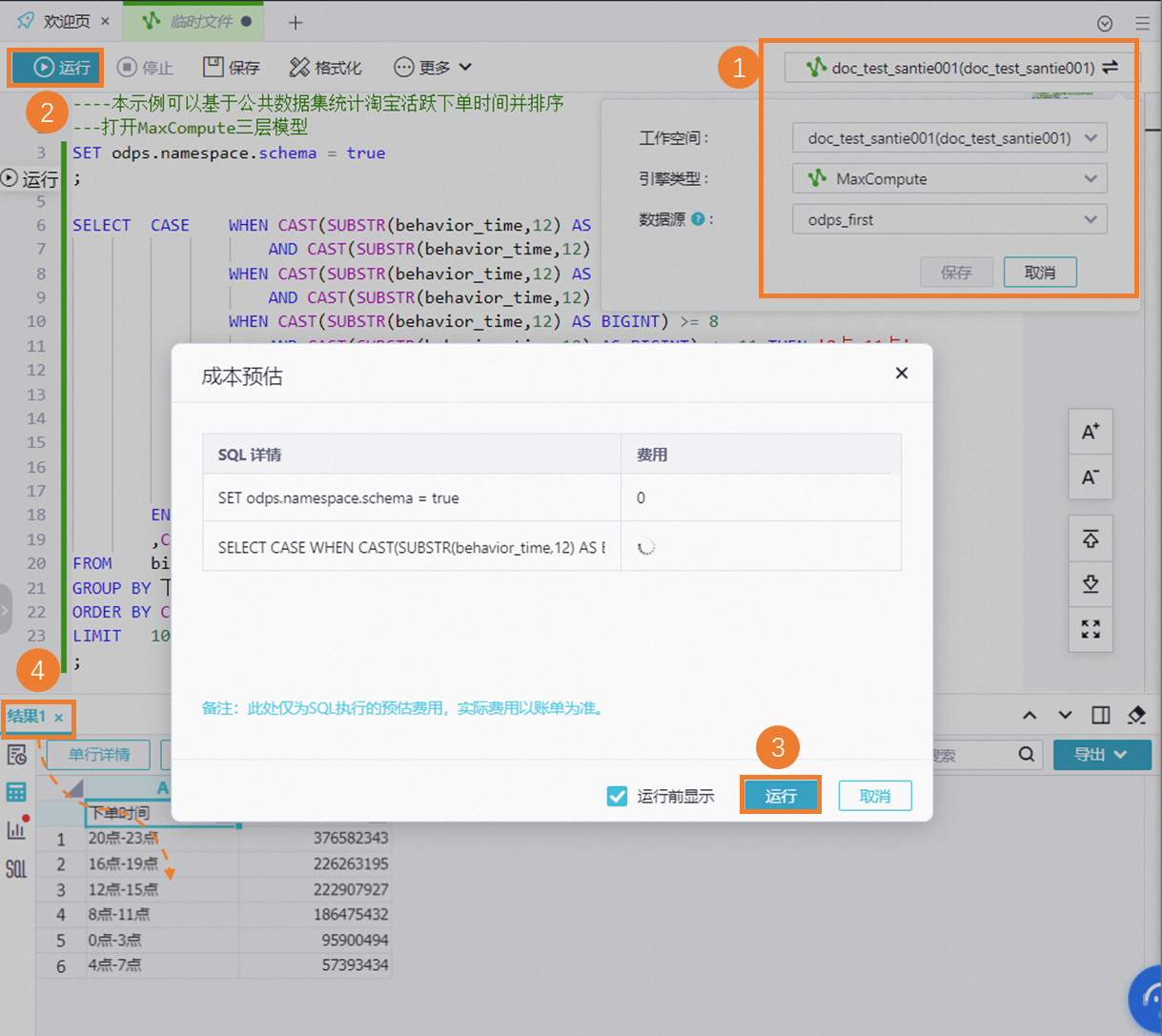
单击SQL文件右上角数据源配置,确认数据源工作空间为上述步骤中创建的工作空间,引擎类型为MaxCompute,数据源为odps_first,然后单击保存。
在SQL文件的顶部单击运行按钮,在弹出的成本预估页面中单击运行,开始运行阿里电商数据集的数据分析任务。
当数据分析任务运行完成后,您可在下面结果页面看到查询结果。
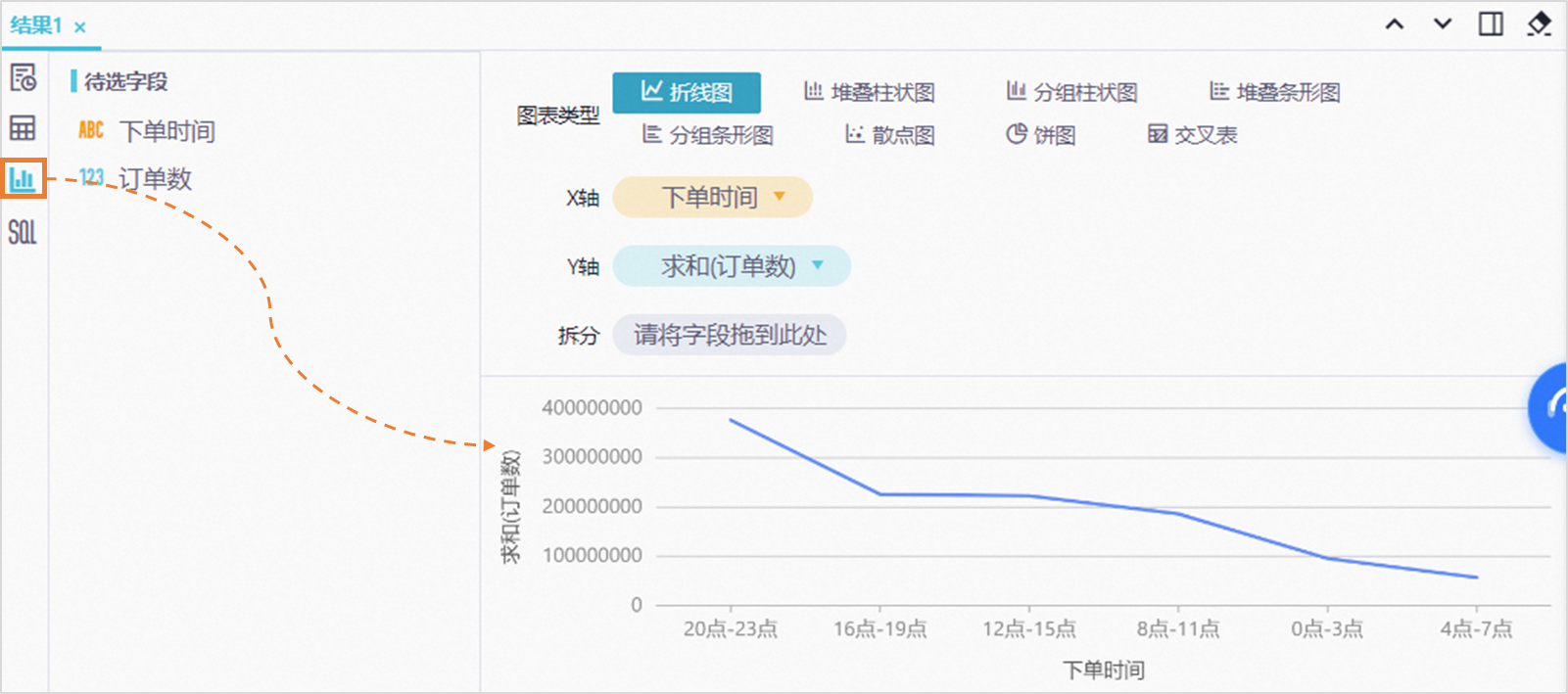
对查询结果进行简单可视化分析。
您可在查询结果页面单击

,DataWorks的SQL分析为您提供了简单的可视化图标功能,您可在此处进行简单的可视化分析。
(可选)数据分析:Github事件公共数据
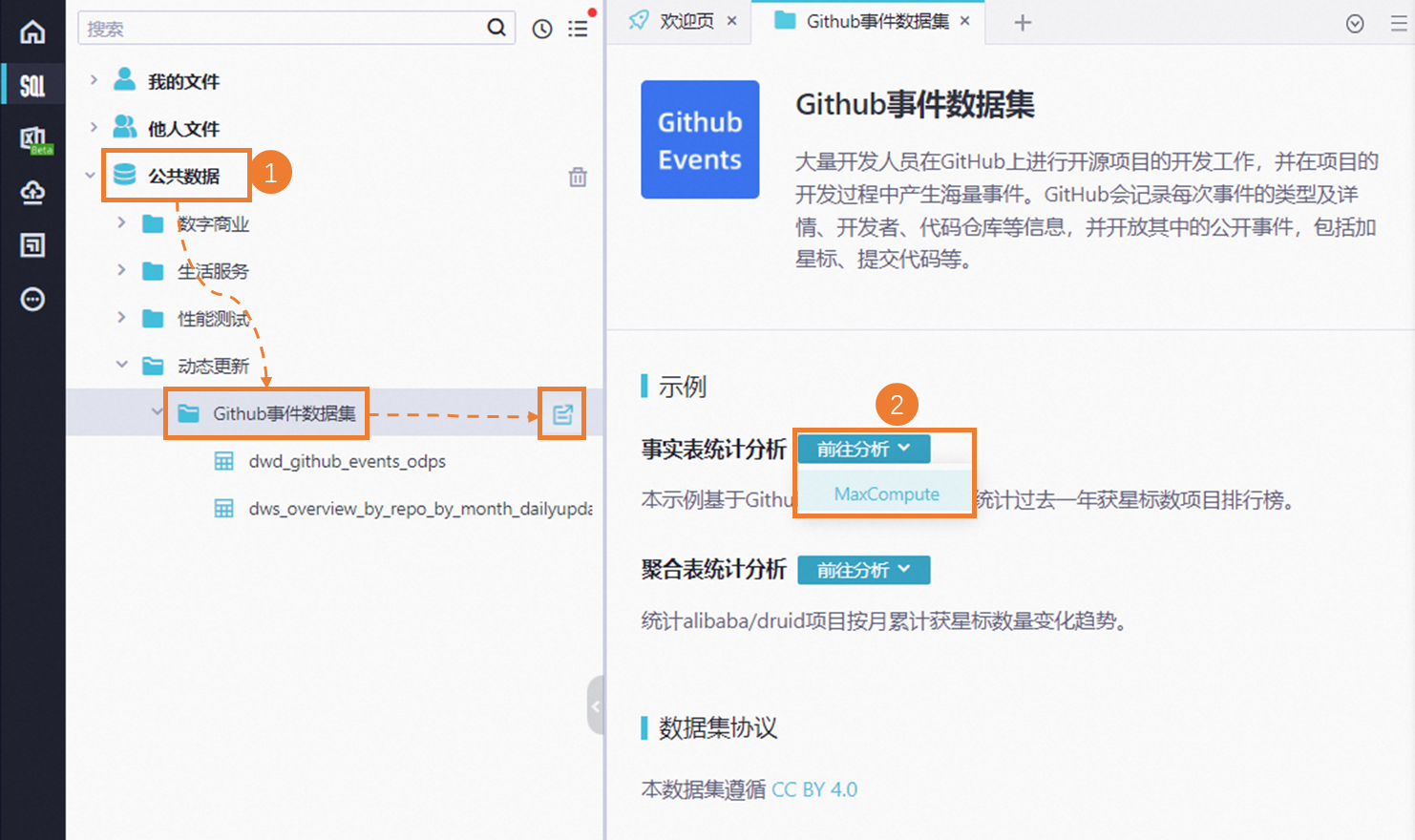
您也可以对其他公共数据进行数据分析操作,以下以Github时间公共数据为例。大量开发人员在GitHub上进行开源项目的开发工作,并在项目的开发过程中产生海量事件。GitHub会记录每次事件的类型及详情、开发者、代码仓库等信息,并开放其中的公开事件,包括加星标、提交代码等。
登录并进入。单击左侧导航中的公共数据>动态更新>Github事件数据集,单击查看详情按钮,打开Github事件数据集介绍页面,单击事实表统计分析后的前往分析,选择MaxCompute引擎。
在打开的临时文件中的右上角选择工作空间为上述步骤创建的空间,引擎为MaxCompute,数据源为odps_first,保存后单击运行,根据界面提示确认大概所需成本后继续单击运行,当分析任务运行完成后,您可以在结果页面查看运行结果。
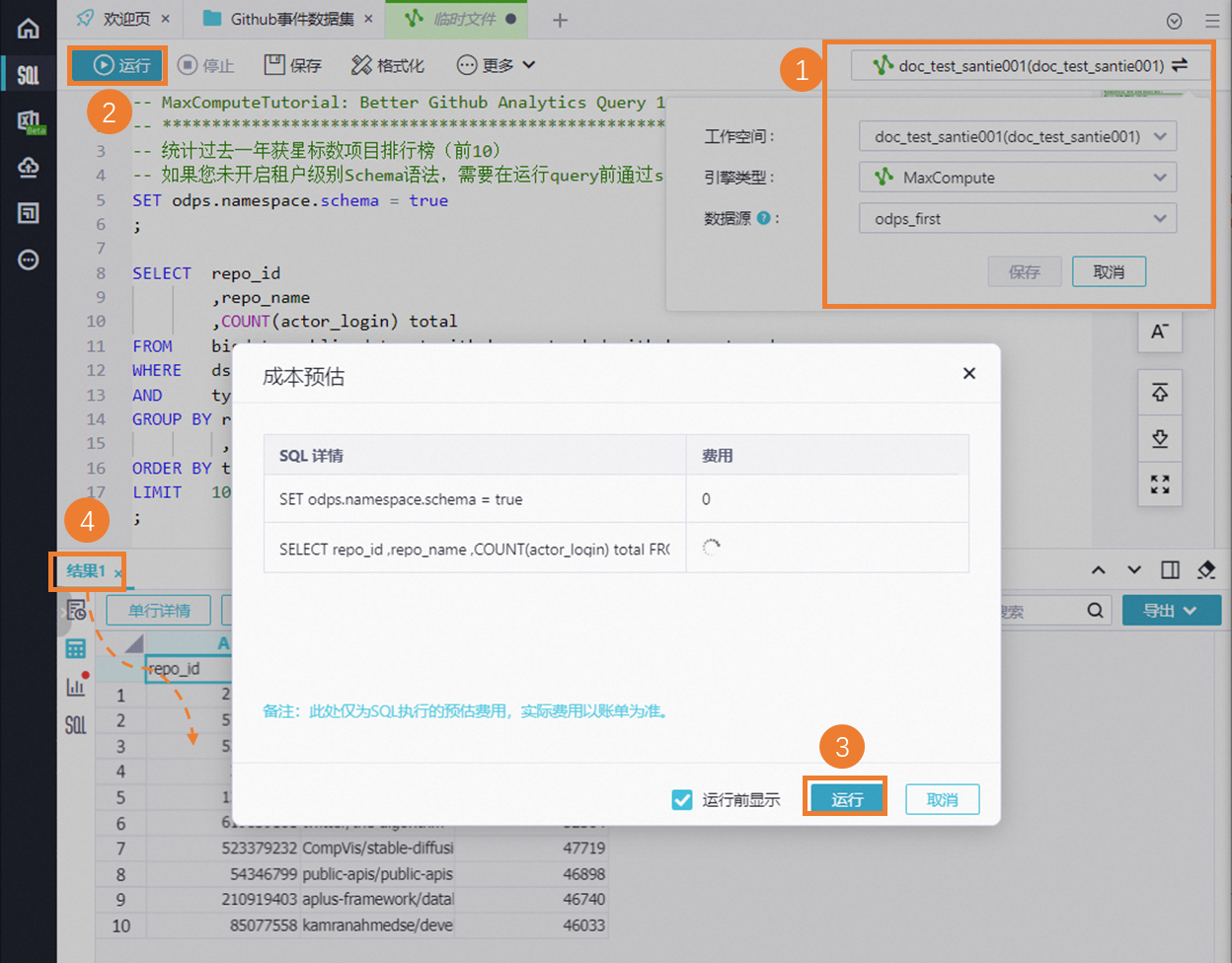
运行完成后,您也可以在结果页面进行简单的可视化分析,操作与上述步骤一致,这里不再赘述。
(可选)数据分析:自定义数据集
您也可以在DataWorks数据分析中创建新的SQL文件,对公共数据集中的数据自行编写查询分析语句,以下以淘宝广告数据集为例,为您示例自定义数据分析SQL语句分析公共数据集的操作。
登录并进入。
单击左侧导航中的公共数据>数字商业>淘宝购物数据集,单击数据集commerce_taobao_shopping,打开数据集介绍页面,您可以在明细信息中查看表的字段信息。
单击顶部的生成SQL语句,选择MaxCompute引擎,进入一个SQL文件。同上述步骤类似,您可以配置好数据源后单击顶部的运行按钮,查看当前公共数据集的数据详情。
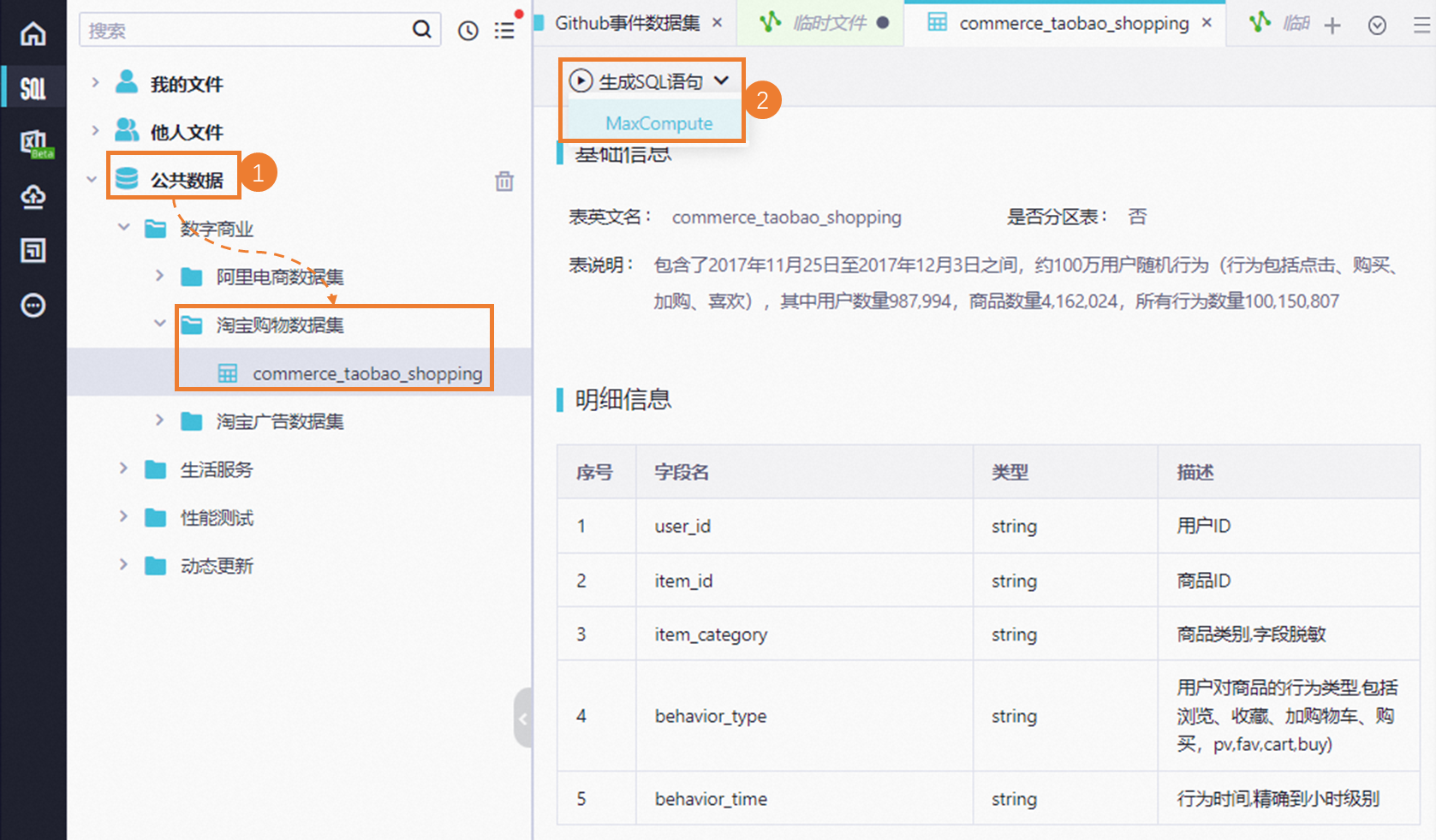
单击顶部SQL文件页签旁的

,新增一个临时SQL文件。在临时SQL文件中输入SET odps.namespace.schema = true;---打开MaxCompute三层模型后,继续编写自定义查询语句,完成后单击运行。
SET odps.namespace.schema = true;---打开MaxCompute三层模型
SELECT user_id , item_id
FROM bigdata_public_dataset.commerce.commerce_taobao_shopping
LIMIT 20
;自定义SQL运行完成后,您可以在结果页面查看查询数据明细,并进行简单可视化分析。
清理及后续
清理
完成教程后,请及时清理测试数据和试用资源。
总结
常用知识点
问题1:公共数据集是否存储在DataWorks中?(单选题)
正确答案是否。DataWorks工作空间可以绑定计算引擎,进行各类高效的数据分析等操作,DataWorks本身不存储和计算数据。
问题2:DataWorks的数据分析是否支持对公共数据集进行自定义分析?(单选题)
正确答案是支持。DataWorks为您提供了多种公共数据集,也为您内置了默认的查询分析SQL文件,同时开支持您自定义分析,进行自定义分析是,务必在自定义SQL前加上SET odps.namespace.schema = true;---打开MaxCompute三层模型。