导语
上一篇文章我们简单介绍了下大数据的基础架构的模块组成和功能以及各模块间是如何协作的。本文开始,我们将对其中比较重要的几个模块来做一个详细的介绍,希望对大家的面试和工作有所帮助。
1.为什么要讲数据收集
数据收集是一切分析的源头。对于大数据分析来说,没有数量足够多,质量足够好的数据,一切分析都是空谈。因为基于统计学大数定律的结论,只有数据量足够大,才能更加接近真相。另外,数据的丰富性也是一个重要的考量指标,因为不同的数据之间可以相互辅助论证、验证,从而确保结论的正确性。因此,数据收集承担着,为数据分析工作,收集到数量足够多、质量够好、种类够丰富的数据的重任。
2.本文的课程目标
本文的主要目标是给大家介绍下数据收集系统的功能目标、运行形式和各种实现方案,并会举一个实际的案例,让大家对数据收集系统有个初步的了解,一来方便大家在面试过程中,知道和面试官如何聊这块的内容,二来让大家对其工作方式有所理解,知道数据是怎么来的,或许对理解自己的工作内容有所帮助。
3.本文的讲解思路
第一部分,我们会简单介绍下什么是数据收集系统,它的作用和目标是什么。
第二部分,我们会针对不同的数据源,讲解下如何对他们进行数据收集。
第三部分,我们以一个实际的实现案例来讲下数据收集系统是如何运转的。
×××
以下为正文01数据收集系统简介
数据收集,顾名思义就是采用某种手段将各种各样的数据收集起来,用于数据分析或其他目的。其概念是比较宽泛的,在不同领域中,收集的数据内容和形式差异很大。本文我们只讨论互联网行业中,用户行为数据和业务系统数据的收集。对于互联网行业的用户行为数据的收集,有以下几个特点:
由于互联网产品的用户很多,因此产生的行为数据量是非常大的;用户同时在线人数很多,数据收集的并发压力很大;用户非常分散,容易出现部分地区或运营商用户的数据上传不到服务端的情况;网络环境很复杂,容易混入脏数据;收集到的数据,要保证及时落盘存储,避免意外造成数据丢失。
数据收集系统在设计之时就会考虑到上述特点,并相应地去解决上述问题。数据收集系统通常分为以下几个部分:
数据收集系统的功能特性为:
拥有非常强的水平扩展能力,能够承载非常大的流量;具备负载均衡的能力,能够扛高并发压力,且支持通过扩展增强抗压能力;通过服务端和客户端SDK的配合,支持轮询探测多个域名和IP直至找到可用域名或IP的能力,并支持通过IP直接上传至服务端,并支持失败重试机制;具备数据校验机制,防止脏数据的混入;拥有数据缓冲能力,将数据及时落地存储,防止数据意外丢失;具备数据的初步分拣能力,方便后续的ETL工作的进行;性能较高,延迟较低,能够保证数据的实时性。
02
数据收集的常见数据源及对应方案
数据库
数据库是非常重要的数据源,因为很多公司的核心业务数据都是存储在数据库中的。比如,电商类公司的订单数据、视频类公司的会员数据等。这些数据的共同特点是,数据量相对较大、更新频率比较高、涉及的表比较多、数据规范比较好、数据质量非常高。
针对这类数据,我们通常是根据数据分析的场景决定收集方式的。
如果是做实时或近实时的数据大屏或者用户画像,可以采用实时监测数据变化,然后通过消息队列,传送给下游的处理程序。例如,其中一种实现方式为,业务系统在数据插入成功后,发送消息到消息中间件,然后下游程序监听消息队列,实时将数据进行分析或者加载到数据仓库中。也有相关的开源组件,如阿里的canal,通过监听数据库的binlog,实现数据的实时收集。
如果只是做T+1的离线报表,也可以采用另一种方式,即对数据库的表做快照,可以是增量的快照,或者全量的快照。是增量还是全量,取决于我们关心的数据内容是否会更新。如果数据只新增不更新或者我们不关心更新的字段,那么就比较适合做增量快照;如果数据更新频繁且我们关心的是数据在一天结束时的最终状态,则比较适合使用全量快照。
用户行为日志
用户行为日志,是指用户在应用上进行各种操作所产生的日志。这些日志中,既包括用户的属性,还包含设备属性、操作场景、操作对象、操作后的状态、以及各种业务参数等。我们通常会使用这些日志,来挖掘用户行为模式,用于改善我们的产品,进而提升用户体验。
对于用户量较大的互联网产品来说,用户行为日志,最大的特点就是数据量很大,而且并发度很高。因此,其收集方案就要考虑,如何应对大流量和高并发的问题,我们在第三部分会用一个具体的示例来详细讲解下其架构实现的其中一种方式。
服务端日志
服务端日志,是指有后台系统运行过程中输出的日志数据。通常有两种形式,一种是写本地日志文件,另一种是写入消息队列。第一种,通常会按小时或者天进行切割,之后经由ftp服务转发或者直接上传至数据中心,也有一些公司的做法是使用flume监听日志文件,将数据写入kafka,供下游程序使用。第二种,则更加实时便捷,后台程序直接就把日志输出写入消息队列,这样下游程序对接消息队列即可。
03
数据收集的架构示例
上面我们提到了,用户行为数据收集,需要考虑的大流量和高并发等一些问题,接下来,我们用一个具体的实例来讲解下如何解决这些问题。
面对大流量和高并发问题,比较成熟的应对措施就是数据压缩+负载均衡+水平扩展。首先,我们要理解这两个问题的本质,那就是数据传输量很大导致IO很高,同一时刻请求量大需要消耗大量cpu、内存和socket连接等资源。
那么,对应的,解决方案就是尽可能降低IO以及资源的消耗,同时可以随时提升各种资源的总量。我们的解决方案是数据压缩+负载均衡+水平扩展。数据压缩,主要作用是降低网络请求的数据量和请求数,从而降低IO和socket连接资源。负载均衡,使得后台可以通过集群的方式,使用多台服务,共同承载压力。水平扩展的能力,使得架构支持水平伸缩,在面临更高压力时,可以通过增加主机,从而增加cpu、内存、socket连接等资源总量,提升服务能力。
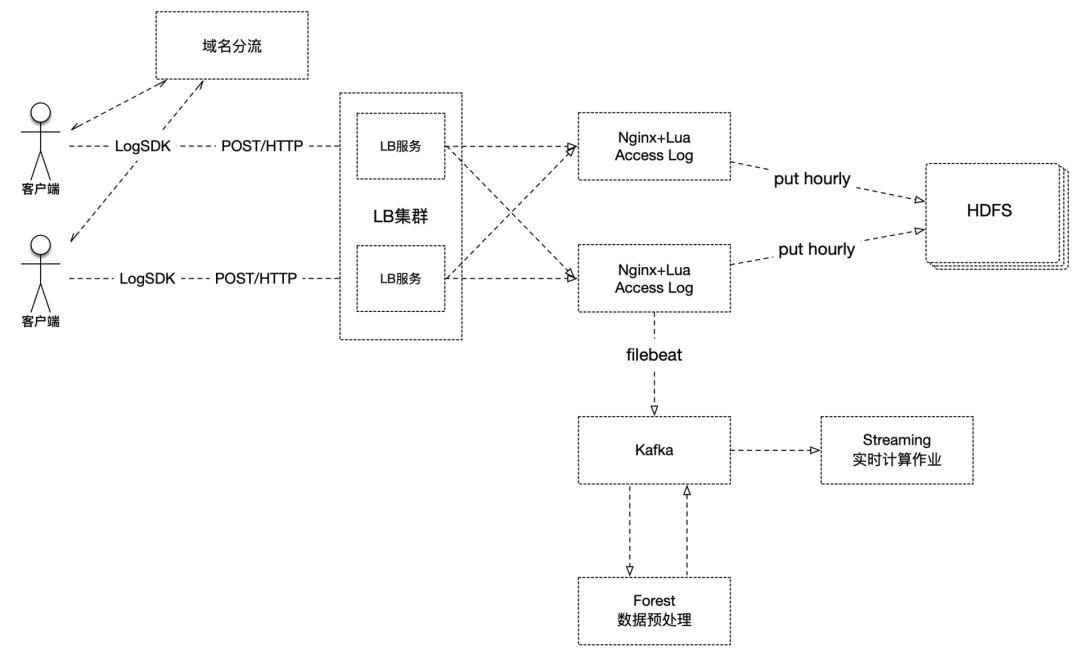
具体的技术架构图如下所示:
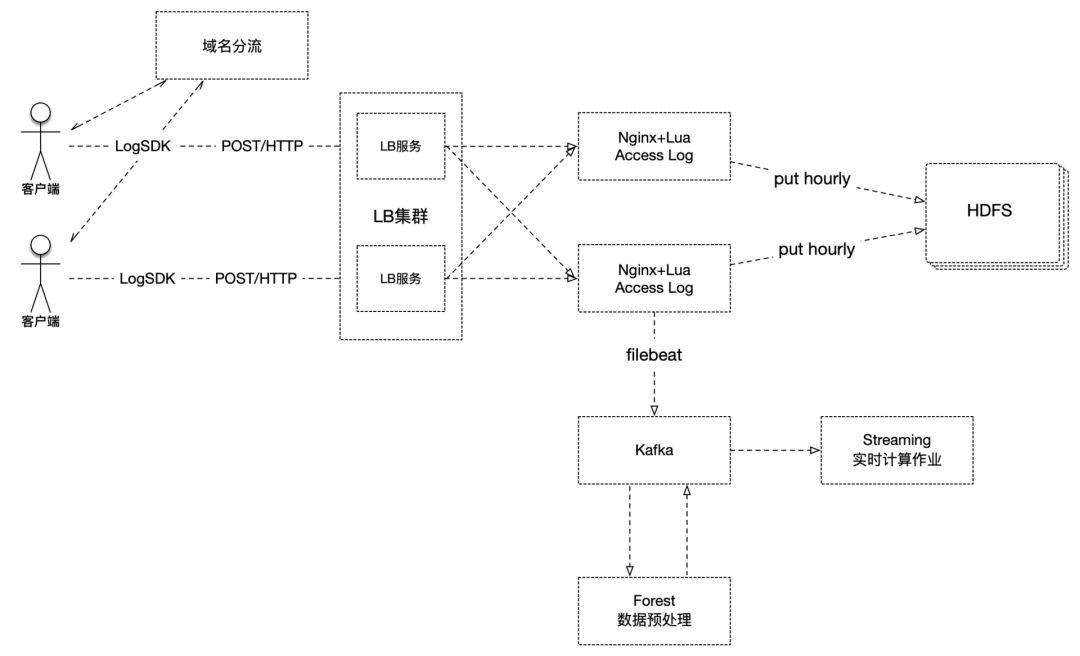
首先,客户端集成了自研的LogSDK,主要负责客户端的信息采集、数据组装、生成校验码、域名IP探测、失败重传、控制不同上传策略等。其中,数据组装,可以实现将多条日志中的相同字段和值抽离出来,这样就从内容上压缩了数据的大小,同时多条数据一次上传,也实现了降低请求量的功能。
其次,客户端在上报数据时,会先经过域名分流服务,我们的域名对应了30个IP,每次访问DNS服务,它都会轮询给出其中一个IP。当请求到达服务端时,首先接收请求的是负载均衡集群,它在接收到数据后,进而均衡地转发给nginx集群。
众所周知,nginx具有很高的网络性能。我们采用nginx+lua的方式来接收数据,nginx负责处理网络请求,而lua则承担数据初步处理的工作,最终会把数据以access_log的方式写入磁盘。
之后,就分为离线和实时两条线路。对于离线线路来说,nginx每小时会切割一次日志,由日志上传脚本负责定时将切割出来的日志上传到HDFS集群,供后续的ETL程序或分析程序使用。而对于实时线路,我们使用filebeat组件将日志文件数据流化,写入kafka,之后由自研的数据清洗处理组件Forest来负责数据的清洗、格式转换、字段校验等各种处理,并将处理后的数据写回kafka(当然前后两个topic是不同的),然后实时作业就可以直接使用了。
总结
本文对互联网公司的数据收集系统做了一个简单的介绍,并举了一个实际的实现案例帮助大家理解它是如何运转的,希望对大家的面试和工作有帮助
点击文章底部左下角“阅读原文”,查看“大数据分析工程师入门”系列文章。
- END -