2019高校大数据挑战赛于8月11日在和鲸社区(Heywhale)落幕,该文转发自 和鲸社区 的Rank 2 团队案例分享。
赛事页面:2019中国高校计算机大赛——大数据挑战赛
原文链接:zhuanlan.zhihu.com/p/89227505
为了让更多关心大数据挑战赛的小伙伴们能够快速理解,这次将以比较通俗的方式来分享此案例。
首先,我们先来看看赛题:
搜索中一个重要的任务是根据 query 和 title 预测 query 下 doc 点击率,本次大赛参赛队伍需要根据脱敏吼的数据预测指定 doc 的点击率,结果按照指定的评价指标使用在线评测数据进行评测和排名,得分最优者获胜。
听起来还挺深奥,那么我们来打个比方:
比如,搜索:高校大数据挑战赛,那么做为一个优秀的搜索引擎,就需要分析是“掏出”这条,更容易被点击
还是“掏出”这条,更容易被点击?

以上是实际操作中的场景,那如果是转化成科学问题呢?那也就是赛题所想表达的意思
搜索中一个重要的任务是根据 query 和 title 预测 query 下 doc 点击率,本次大赛参赛队伍需要根据脱敏吼的数据预测指定 doc 的点击率,结果按照指定的评价指标使用在线评测数据进行评测和排名,得分最优者获胜。
当然,数据也是要面子的,所以会进行一定的打码处理,你看到的数据就会是下面这样的↓
搜索词的处理
搜索结果的标题处理:




所以这个比赛实际上就是根据 脱敏后的搜索词和 脱敏吼的文章标题的关系,预测后者被点击的概率。
以上是对题目的解释,那么接下来我们步入正题,来看看此次大赛 Rank2 的解题思路。
第一步:了解数据
1、搜索词的长度分布情况
实际场景中,用户会使用不同长度的关键字来搜索,那么 Title 数就是关键词分布吼的词语个数。比如,“大数据 / 挑战赛” title 数就是2;“高校 / 大数据 / 挑战赛” title 数就是3
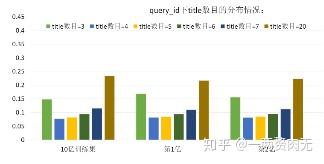
由图可得,训练集 Title 数的整体分布是均匀的
2、搜索词对应的点击数分布情况
实际场景中,用户一次搜索之后,会返回多个文章。接下来是研究相同 Title 数下,用户点击数量的分布。
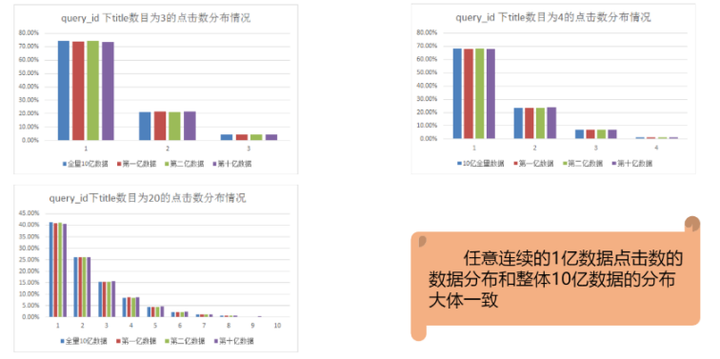
由图可得,相同 title 数下训练集的数据分布是均匀的。但不同 title 数之间,用户点击数分布是不均匀的 ,比如 title 数=3的用户,有75%的人点了一下就跑了,但 title 数=20的用户,将近60%的人会点击多条结果。(原作者还有一些关于训练集相关的分析,此处略去)
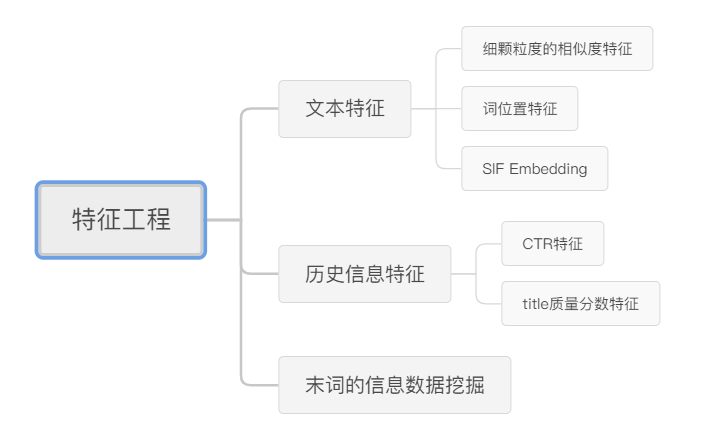
第二步:特征工程
这部分就需要尽情地开脑洞,想出一些实际场景中可能会影响你是否点击的因素,从而转化为数据的表达方式。
比如:
1、标题包含关键词的完整度


图1标题中包含了完整关键词,而图二标题中只包含了1个关键词词语。那么,关键字→图1标题的点击率,要比关键字→图2标题的点击率要高。
2、标题包含关键词是否连续


图1标题中关键词连续,而图二标题中关键词不连续。那么,关键字→图1标题的点击率,要比关键字→图2标题的点击率要高。
以上诸如此类,可以想到很多主观上会影响点击的因素。
除了分析同一个搜索词下不同的文章,我们还可以分析不同搜索词下的同一篇文章。比如,搜索“高校大数据挑战赛”和“高校数据挑战赛”,大家都点击了下面这篇:
那么说明,该文章质量较高,在其他搜索词下,该文章点击率会比其他文章点击率高。
当然,还有一些无法直接用实际场景的例子说明的“玄学”特征(比如下图的SIF),此处就不强行解释了。
以上所有特征,经过比较筛选后,最终留下一些作为最终使用的特征。
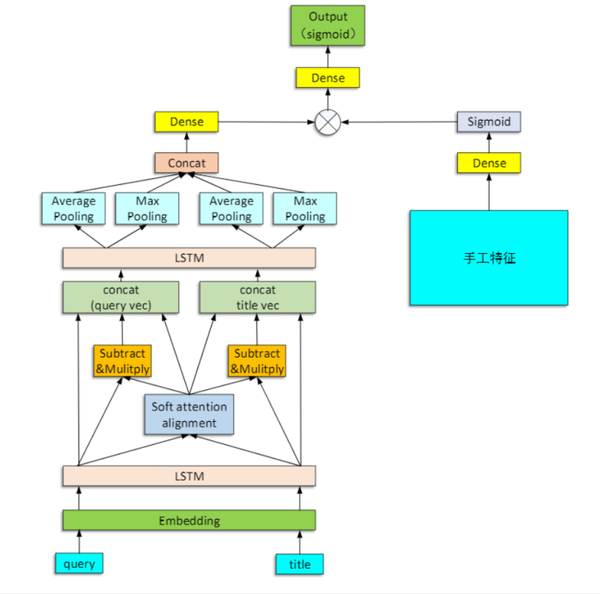
第三步:选择模型
这一步需要选择合适的模型进行深度学习训练(过程比较枯燥,略过,感兴趣的话可以查看PPT和代码),最终选择了如下模型
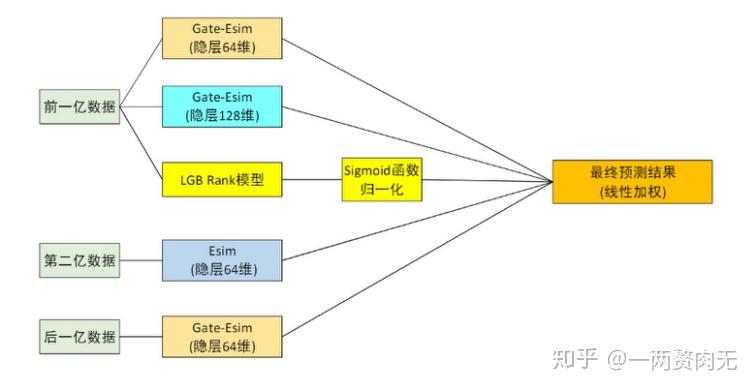
第四步:模型融合
这一步是数据科学竞赛特有的步骤,目的是为了提高分数,略过,感兴趣的话可以查看PPT和代码,最终选择了如下融合方案